 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMVP: A Multimodal MoCap Dataset with Vision and Pressure Sensors
Mar 30, 2024



Foot contact is an important cue for human motion capture, understanding, and generation. Existing datasets tend to annotate dense foot contact using visual matching with thresholding or incorporating pressure signals. However, these approaches either suffer from low accuracy or are only designed for small-range and slow motion. There is still a lack of a vision-pressure multimodal dataset with large-range and fast human motion, as well as accurate and dense foot-contact annotation. To fill this gap, we propose a Multimodal MoCap Dataset with Vision and Pressure sensors, named MMVP. MMVP provides accurate and dense plantar pressure signals synchronized with RGBD observations, which is especially useful for both plausible shape estimation, robust pose fitting without foot drifting, and accurate global translation tracking. To validate the dataset, we propose an RGBD-P SMPL fitting method and also a monocular-video-based baseline framework, VP-MoCap, for human motion capture. Experiments demonstrate that our RGBD-P SMPL Fitting results significantly outperform pure visual motion capture. Moreover, VP-MoCap outperforms SOTA methods in foot-contact and global translation estimation accuracy. We believe the configuration of the dataset and the baseline frameworks will stimulate the research in this direction and also provide a good reference for MoCap applications in various domains. Project page: https://metaverse-ai-lab-thu.github.io/MMVP-Dataset/.
AdLER: Adversarial Training with Label Error Rectification for One-Shot Medical Image Segmentation
Sep 02, 2023Accurate automatic segmentation of medical images typically requires large datasets with high-quality annotations, making it less applicable in clinical settings due to limited training data. One-shot segmentation based on learned transformations (OSSLT) has shown promise when labeled data is extremely limited, typically including unsupervised deformable registration, data augmentation with learned registration, and segmentation learned from augmented data. However, current one-shot segmentation methods are challenged by limited data diversity during augmentation, and potential label errors caused by imperfect registration. To address these issues, we propose a novel one-shot medical image segmentation method with adversarial training and label error rectification (AdLER), with the aim of improving the diversity of generated data and correcting label errors to enhance segmentation performance. Specifically, we implement a novel dual consistency constraint to ensure anatomy-aligned registration that lessens registration errors. Furthermore, we develop an adversarial training strategy to augment the atlas image, which ensures both generation diversity and segmentation robustness. We also propose to rectify potential label errors in the augmented atlas images by estimating segmentation uncertainty, which can compensate for the imperfect nature of deformable registration and improve segmentation authenticity. Experiments on the CANDI and ABIDE datasets demonstrate that the proposed AdLER outperforms previous state-of-the-art methods by 0.7% (CANDI), 3.6% (ABIDE "seen"), and 4.9% (ABIDE "unseen") in segmentation based on Dice scores, respectively. The source code will be available at https://github.com/hsiangyuzhao/AdLER.
Distributed Attention for Grounded Image Captioning
Aug 22, 2021
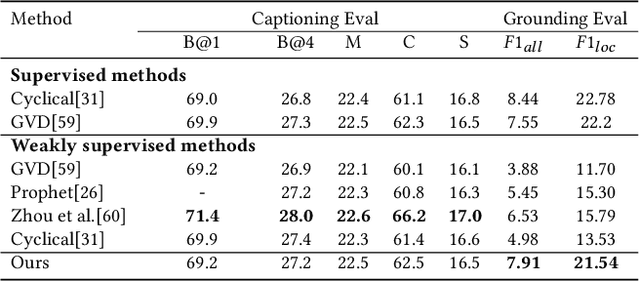

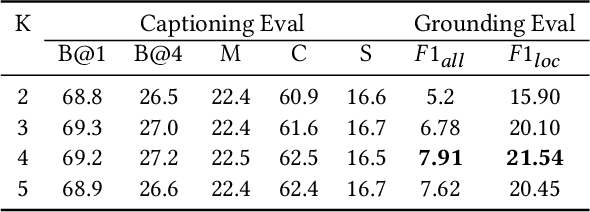
We study the problem of weakly supervised grounded image captioning. That is, given an image, the goal is to automatically generate a sentence describing the context of the image with each noun word grounded to the corresponding region in the image. This task is challenging due to the lack of explicit fine-grained region word alignments as supervision. Previous weakly supervised methods mainly explore various kinds of regularization schemes to improve attention accuracy. However, their performances are still far from the fully supervised ones. One main issue that has been ignored is that the attention for generating visually groundable words may only focus on the most discriminate parts and can not cover the whole object. To this end, we propose a simple yet effective method to alleviate the issue, termed as partial grounding problem in our paper. Specifically, we design a distributed attention mechanism to enforce the network to aggregate information from multiple spatially different regions with consistent semantics while generating the words. Therefore, the union of the focused region proposals should form a visual region that encloses the object of interest completely. Extensive experiments have demonstrated the superiority of our proposed method compared with the state-of-the-arts.
Unveiling the Potential of Structure Preserving for Weakly Supervised Object Localization
Mar 30, 2021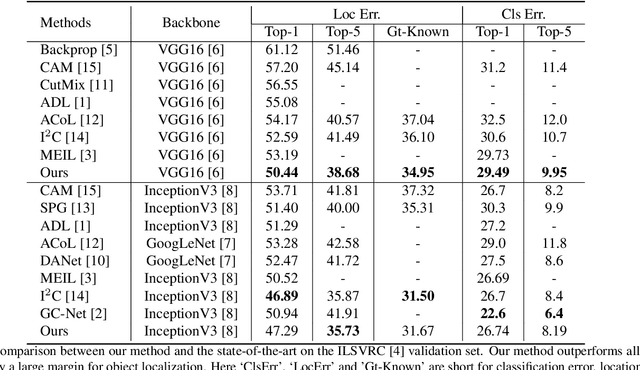

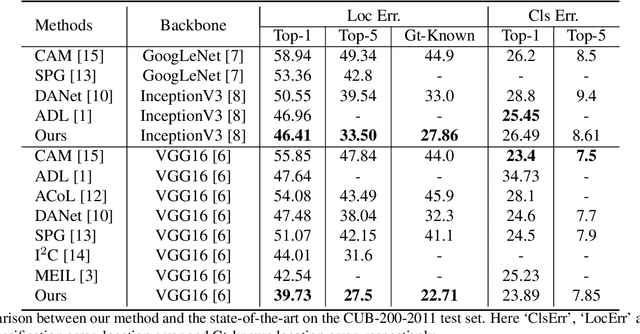
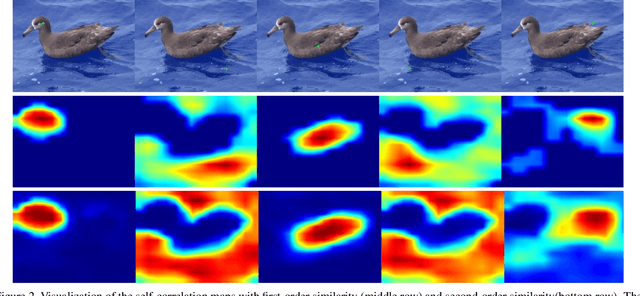
Weakly supervised object localization(WSOL) remains an open problem given the deficiency of finding object extent information using a classification network. Although prior works struggled to localize objects through various spatial regularization strategies, we argue that how to extract object structural information from the trained classification network is neglected. In this paper, we propose a two-stage approach, termed structure-preserving activation (SPA), toward fully leveraging the structure information incorporated in convolutional features for WSOL. First, a restricted activation module (RAM) is designed to alleviate the structure-missing issue caused by the classification network on the basis of the observation that the unbounded classification map and global average pooling layer drive the network to focus only on object parts. Second, we designed a post-process approach, termed self-correlation map generating (SCG) module to obtain structure-preserving localization maps on the basis of the activation maps acquired from the first stage. Specifically, we utilize the high-order self-correlation (HSC) to extract the inherent structural information retained in the learned model and then aggregate HSC of multiple points for precise object localization. Extensive experiments on two publicly available benchmarks including CUB-200-2011 and ILSVRC show that the proposed SPA achieves substantial and consistent performance gains compared with baseline approaches.Code and models are available at https://github.com/Panxjia/SPA_CVPR2021
Dynamic Refinement Network for Oriented and Densely Packed Object Detection
Jun 10, 2020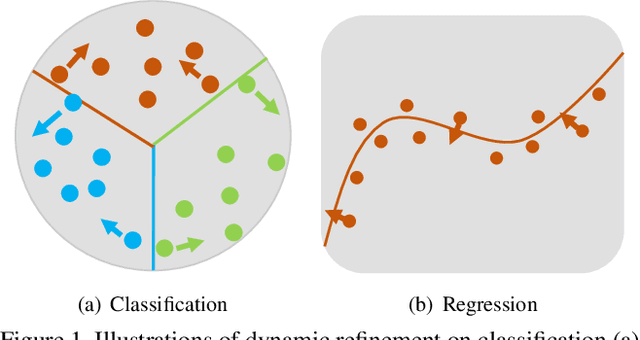

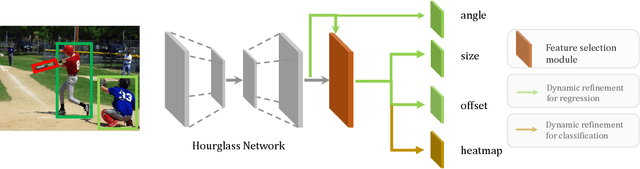

Object detection has achieved remarkable progress in the past decade. However, the detection of oriented and densely packed objects remains challenging because of following inherent reasons: (1) receptive fields of neurons are all axis-aligned and of the same shape, whereas objects are usually of diverse shapes and align along various directions; (2) detection models are typically trained with generic knowledge and may not generalize well to handle specific objects at test time; (3) the limited dataset hinders the development on this task. To resolve the first two issues, we present a dynamic refinement network that consists of two novel components, i.e., a feature selection module (FSM) and a dynamic refinement head (DRH). Our FSM enables neurons to adjust receptive fields in accordance with the shapes and orientations of target objects, whereas the DRH empowers our model to refine the prediction dynamically in an object-aware manner. To address the limited availability of related benchmarks, we collect an extensive and fully annotated dataset, namely, SKU110K-R, which is relabeled with oriented bounding boxes based on SKU110K. We perform quantitative evaluations on several publicly available benchmarks including DOTA, HRSC2016, SKU110K, and our own SKU110K-R dataset. Experimental results show that our method achieves consistent and substantial gains compared with baseline approaches. The code and dataset are available at https://github.com/Anymake/DRN_CVPR2020.