 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM4Fluid: Large Language Models as Generalizable Neural Solvers for Fluid Dynamics
Jan 29, 2026Deep learning has emerged as a promising paradigm for spatio-temporal modeling of fluid dynamics. However, existing approaches often suffer from limited generalization to unseen flow conditions and typically require retraining when applied to new scenarios. In this paper, we present LLM4Fluid, a spatio-temporal prediction framework that leverages Large Language Models (LLMs) as generalizable neural solvers for fluid dynamics. The framework first compresses high-dimensional flow fields into a compact latent space via reduced-order modeling enhanced with a physics-informed disentanglement mechanism, effectively mitigating spatial feature entanglement while preserving essential flow structures. A pretrained LLM then serves as a temporal processor, autoregressively predicting the dynamics of physical sequences with time series prompts. To bridge the modality gap between prompts and physical sequences, which can otherwise degrade prediction accuracy, we propose a dedicated modality alignment strategy that resolves representational mismatch and stabilizes long-term prediction. Extensive experiments across diverse flow scenarios demonstrate that LLM4Fluid functions as a robust and generalizable neural solver without retraining, achieving state-of-the-art accuracy while exhibiting powerful zero-shot and in-context learning capabilities. Code and datasets are publicly available at https://github.com/qisongxiao/LLM4Fluid.
Revolutionizing Agrifood Systems with Artificial Intelligence: A Survey
May 03, 2023



With the world population rapidly increasing, transforming our agrifood systems to be more productive, efficient, safe, and sustainable is crucial to mitigate potential food shortages. Recently, artificial intelligence (AI) techniques such as deep learning (DL) have demonstrated their strong abilities in various areas, including language, vision, remote sensing (RS), and agrifood systems applications. However, the overall impact of AI on agrifood systems remains unclear. In this paper, we thoroughly review how AI techniques can transform agrifood systems and contribute to the modern agrifood industry. Firstly, we summarize the data acquisition methods in agrifood systems, including acquisition, storage, and processing techniques. Secondly, we present a progress review of AI methods in agrifood systems, specifically in agriculture, animal husbandry, and fishery, covering topics such as agrifood classification, growth monitoring, yield prediction, and quality assessment. Furthermore, we highlight potential challenges and promising research opportunities for transforming modern agrifood systems with AI. We hope this survey could offer an overall picture to newcomers in the field and serve as a starting point for their further research.
Locate before Answering: Answer Guided Question Localization for Video Question Answering
Oct 05, 2022
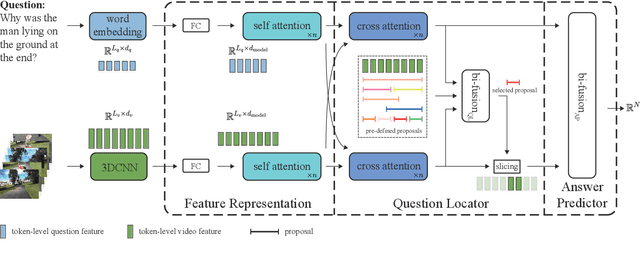
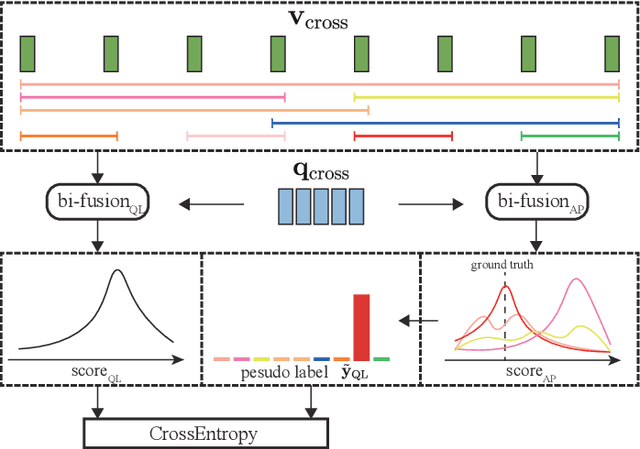
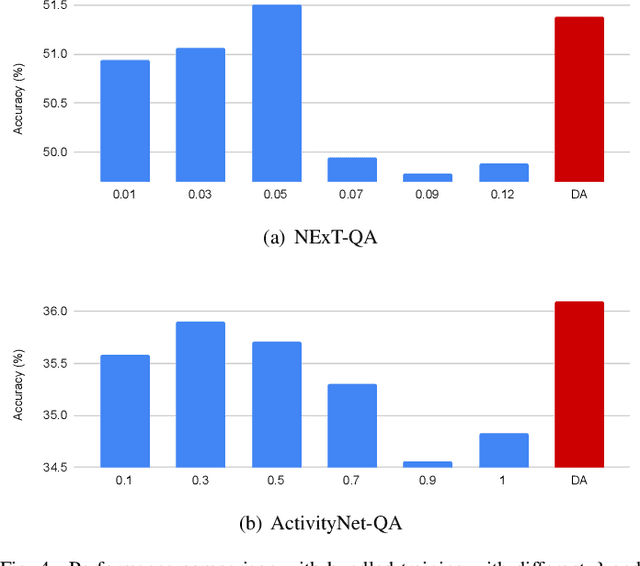
Video question answering (VideoQA) is an essential task in vision-language understanding, which has attracted numerous research attention recently. Nevertheless, existing works mostly achieve promising performances on short videos of duration within 15 seconds. For VideoQA on minute-level long-term videos, those methods are likely to fail because of lacking the ability to deal with noise and redundancy caused by scene changes and multiple actions in the video. Considering the fact that the question often remains concentrated in a short temporal range, we propose to first locate the question to a segment in the video and then infer the answer using the located segment only. Under this scheme, we propose "Locate before Answering" (LocAns), a novel approach that integrates a question locator and an answer predictor into an end-to-end model. During the training phase, the available answer label not only serves as the supervision signal of the answer predictor, but also is used to generate pseudo temporal labels for the question locator. Moreover, we design a decoupled alternative training strategy to update the two modules separately. In the experiments, LocAns achieves state-of-the-art performance on two modern long-term VideoQA datasets NExT-QA and ActivityNet-QA, and its qualitative examples show the reliable performance of the question localization.
Transformer-based Dual Relation Graph for Multi-label Image Recognition
Oct 12, 2021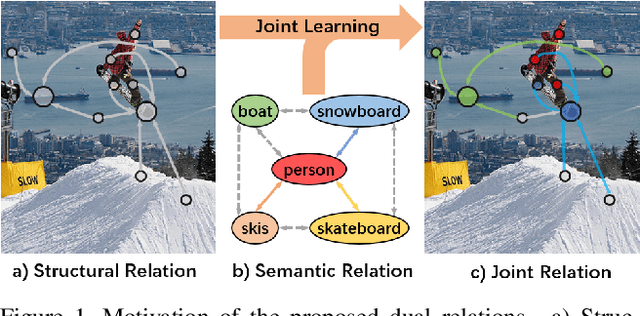
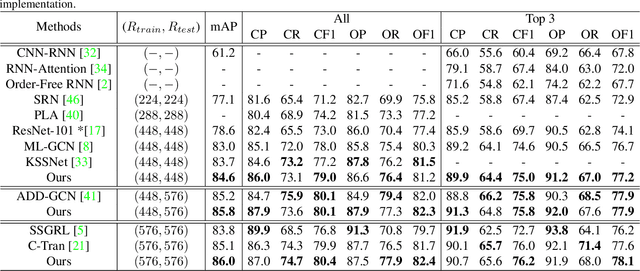
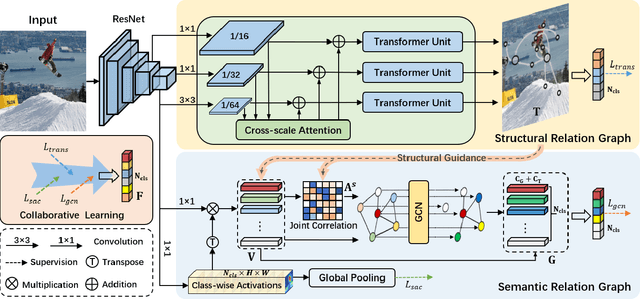
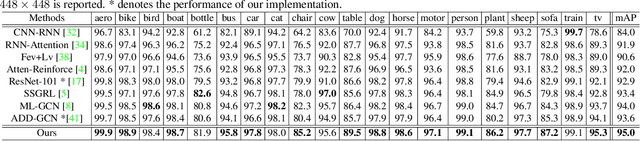
The simultaneous recognition of multiple objects in one image remains a challenging task, spanning multiple events in the recognition field such as various object scales, inconsistent appearances, and confused inter-class relationships. Recent research efforts mainly resort to the statistic label co-occurrences and linguistic word embedding to enhance the unclear semantics. Different from these researches, in this paper, we propose a novel Transformer-based Dual Relation learning framework, constructing complementary relationships by exploring two aspects of correlation, i.e., structural relation graph and semantic relation graph. The structural relation graph aims to capture long-range correlations from object context, by developing a cross-scale transformer-based architecture. The semantic graph dynamically models the semantic meanings of image objects with explicit semantic-aware constraints. In addition, we also incorporate the learnt structural relationship into the semantic graph, constructing a joint relation graph for robust representations. With the collaborative learning of these two effective relation graphs, our approach achieves new state-of-the-art on two popular multi-label recognition benchmarks, i.e., MS-COCO and VOC 2007 dataset.
* 10 pages, 5 figures. Published in ICCV 2021
Distributed Attention for Grounded Image Captioning
Aug 22, 2021
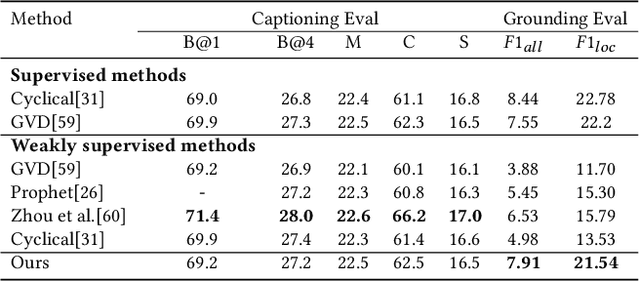

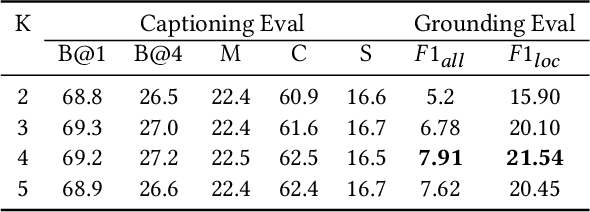
We study the problem of weakly supervised grounded image captioning. That is, given an image, the goal is to automatically generate a sentence describing the context of the image with each noun word grounded to the corresponding region in the image. This task is challenging due to the lack of explicit fine-grained region word alignments as supervision. Previous weakly supervised methods mainly explore various kinds of regularization schemes to improve attention accuracy. However, their performances are still far from the fully supervised ones. One main issue that has been ignored is that the attention for generating visually groundable words may only focus on the most discriminate parts and can not cover the whole object. To this end, we propose a simple yet effective method to alleviate the issue, termed as partial grounding problem in our paper. Specifically, we design a distributed attention mechanism to enforce the network to aggregate information from multiple spatially different regions with consistent semantics while generating the words. Therefore, the union of the focused region proposals should form a visual region that encloses the object of interest completely. Extensive experiments have demonstrated the superiority of our proposed method compared with the state-of-the-arts.
Discriminator-Free Generative Adversarial Attack
Jul 20, 2021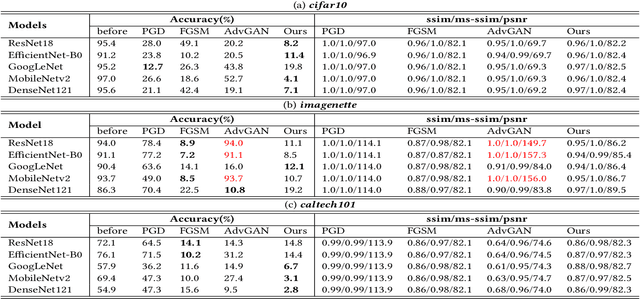
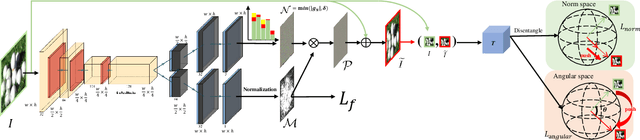
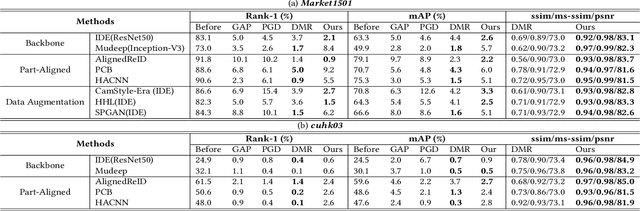
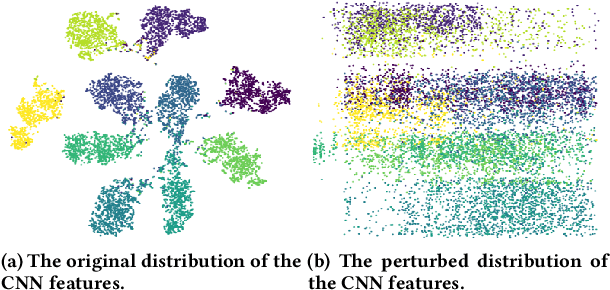
The Deep Neural Networks are vulnerable toadversarial exam-ples(Figure 1), making the DNNs-based systems collapsed byadding the inconspicuous perturbations to the images. Most of the existing works for adversarial attack are gradient-based and suf-fer from the latency efficiencies and the load on GPU memory. Thegenerative-based adversarial attacks can get rid of this limitation,and some relative works propose the approaches based on GAN.However, suffering from the difficulty of the convergence of train-ing a GAN, the adversarial examples have either bad attack abilityor bad visual quality. In this work, we find that the discriminatorcould be not necessary for generative-based adversarial attack, andpropose theSymmetric Saliency-based Auto-Encoder (SSAE)to generate the perturbations, which is composed of the saliencymap module and the angle-norm disentanglement of the featuresmodule. The advantage of our proposed method lies in that it is notdepending on discriminator, and uses the generative saliency map to pay more attention to label-relevant regions. The extensive exper-iments among the various tasks, datasets, and models demonstratethat the adversarial examples generated by SSAE not only make thewidely-used models collapse, but also achieves good visual quality.The code is available at https://github.com/BravoLu/SSAE.
DisCo: Remedy Self-supervised Learning on Lightweight Models with Distilled Contrastive Learning
Apr 19, 2021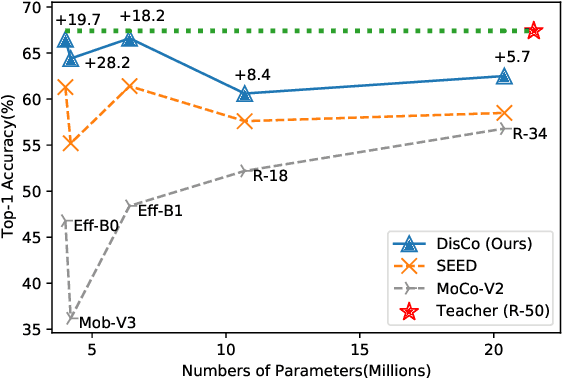
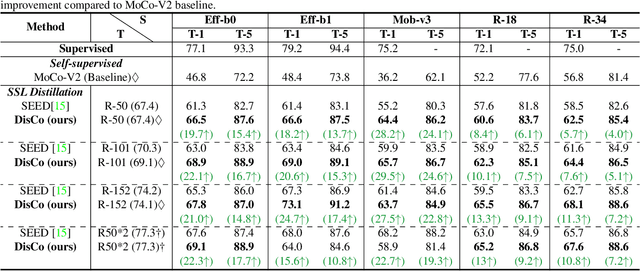
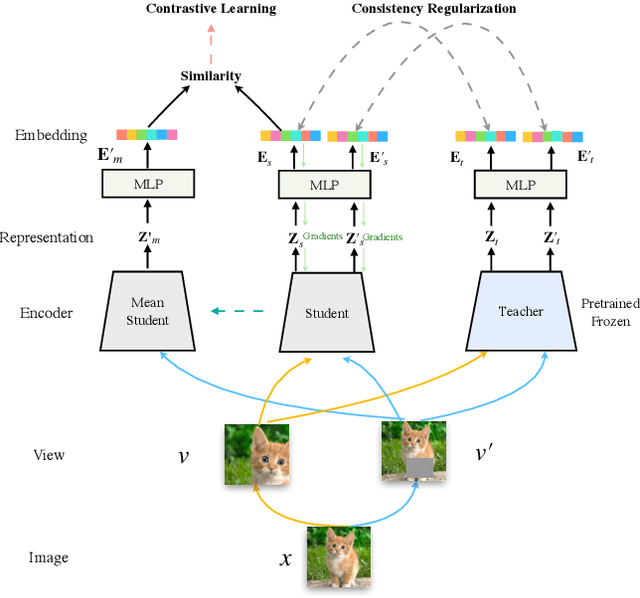
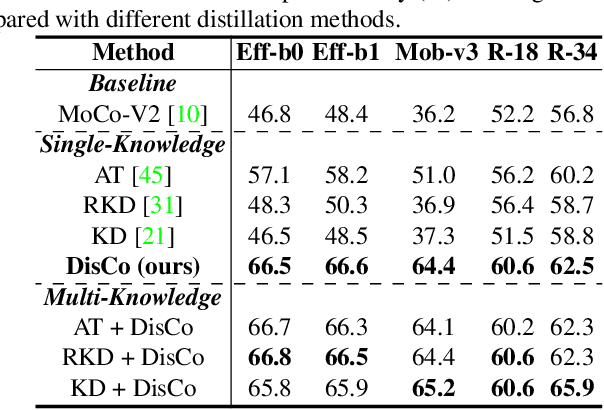
While self-supervised representation learning (SSL) has received widespread attention from the community, recent research argue that its performance will suffer a cliff fall when the model size decreases. The current method mainly relies on contrastive learning to train the network and in this work, we propose a simple yet effective Distilled Contrastive Learning (DisCo) to ease the issue by a large margin. Specifically, we find the final embedding obtained by the mainstream SSL methods contains the most fruitful information, and propose to distill the final embedding to maximally transmit a teacher's knowledge to a lightweight model by constraining the last embedding of the student to be consistent with that of the teacher. In addition, in the experiment, we find that there exists a phenomenon termed Distilling BottleNeck and present to enlarge the embedding dimension to alleviate this problem. Our method does not introduce any extra parameter to lightweight models during deployment. Experimental results demonstrate that our method achieves the state-of-the-art on all lightweight models. Particularly, when ResNet-101/ResNet-50 is used as teacher to teach EfficientNet-B0, the linear result of EfficientNet-B0 on ImageNet is very close to ResNet-101/ResNet-50, but the number of parameters of EfficientNet-B0 is only 9.4%/16.3% of ResNet-101/ResNet-50.
Part2Whole: Iteratively Enrich Detail for Cross-Modal Retrieval with Partial Query
Mar 02, 2021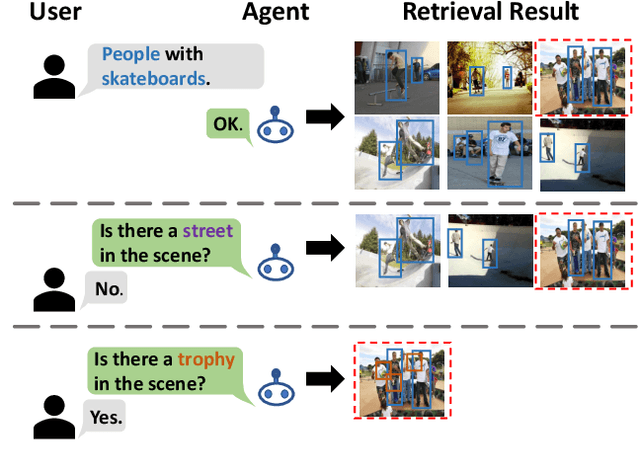

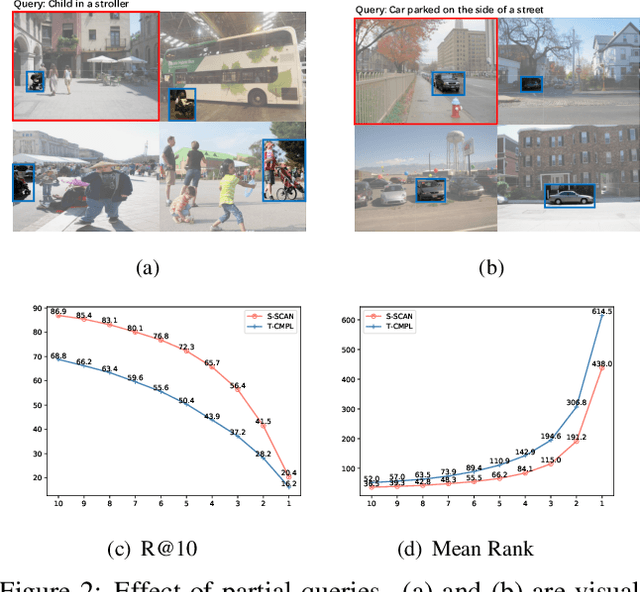
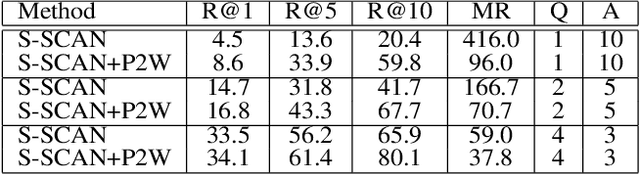
Text-based image retrieval has seen considerable progress in recent years. However, the performance of existing methods suffers in real life since the user is likely to provide an incomplete description of a complex scene, which often leads to results filled with false positives that fit the incomplete description. In this work, we introduce the partial-query problem and extensively analyze its influence on text-based image retrieval. We then propose an interactive retrieval framework called Part2Whole to tackle this problem by iteratively enriching the missing details. Specifically, an Interactive Retrieval Agent is trained to build an optimal policy to refine the initial query based on a user-friendly interaction and statistical characteristics of the gallery. Compared to other dialog-based methods that rely heavily on the user to feed back differentiating information, we let AI take over the optimal feedback searching process and hint the user with confirmation-based questions about details. Furthermore, since fully-supervised training is often infeasible due to the difficulty of obtaining human-machine dialog data, we present a weakly-supervised reinforcement learning method that needs no human-annotated data other than the text-image dataset. Experiments show that our framework significantly improves the performance of text-based image retrieval under complex scenes.
On The Consistency Training for Open-Set Semi-Supervised Learning
Jan 19, 2021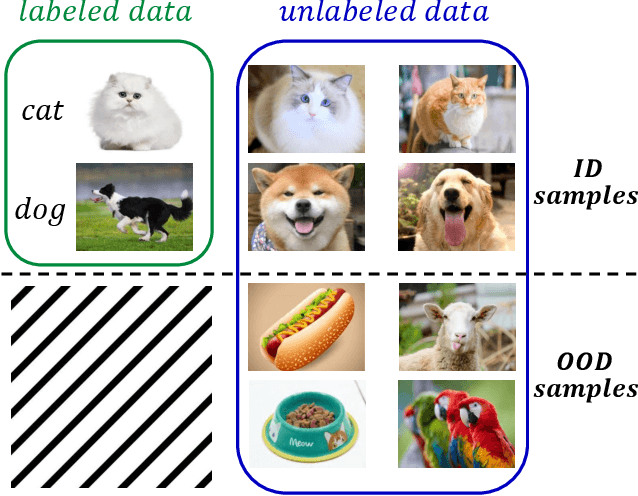
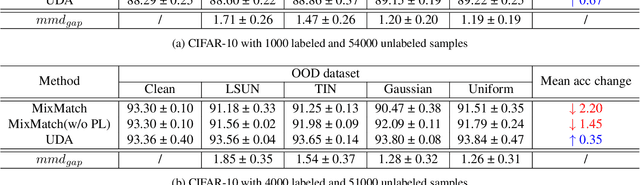
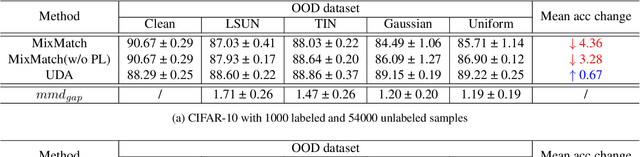

Conventional semi-supervised learning (SSL) methods, e.g., MixMatch, achieve great performance when both labeled and unlabeled dataset are drawn from the same distribution. However, these methods often suffer severe performance degradation in a more realistic setting, where unlabeled dataset contains out-of-distribution (OOD) samples. Recent approaches mitigate the negative influence of OOD samples by filtering them out from the unlabeled data. Our studies show that it is not necessary to get rid of OOD samples during training. On the contrary, the network can benefit from them if OOD samples are properly utilized. We thoroughly study how OOD samples affect DNN training in both low- and high-dimensional spaces, where two fundamental SSL methods are considered: Pseudo Labeling (PL) and Data Augmentation based Consistency Training (DACT). Conclusion is twofold: (1) unlike PL that suffers performance degradation, DACT brings improvement to model performance; (2) the improvement is closely related to class-wise distribution gap between the labeled and the unlabeled dataset. Motivated by this observation, we further improve the model performance by bridging the gap between the labeled and the unlabeled datasets (containing OOD samples). Compared to previous algorithms paying much attention to distinguishing between ID and OOD samples, our method makes better use of OOD samples and achieves state-of-the-art results.
Contextual Non-Local Alignment over Full-Scale Representation for Text-Based Person Search
Jan 08, 2021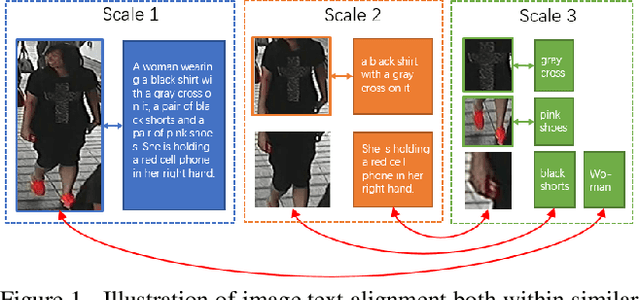
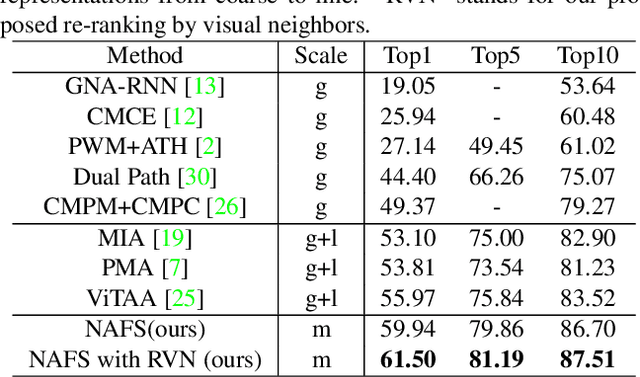
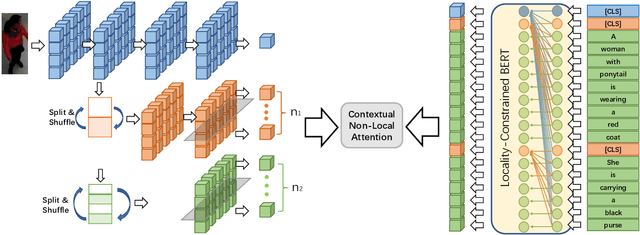
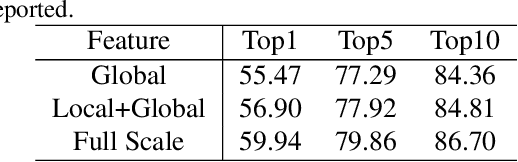
Text-based person search aims at retrieving target person in an image gallery using a descriptive sentence of that person. It is very challenging since modal gap makes effectively extracting discriminative features more difficult. Moreover, the inter-class variance of both pedestrian images and descriptions is small. So comprehensive information is needed to align visual and textual clues across all scales. Most existing methods merely consider the local alignment between images and texts within a single scale (e.g. only global scale or only partial scale) then simply construct alignment at each scale separately. To address this problem, we propose a method that is able to adaptively align image and textual features across all scales, called NAFS (i.e.Non-local Alignment over Full-Scale representations). Firstly, a novel staircase network structure is proposed to extract full-scale image features with better locality. Secondly, a BERT with locality-constrained attention is proposed to obtain representations of descriptions at different scales. Then, instead of separately aligning features at each scale, a novel contextual non-local attention mechanism is applied to simultaneously discover latent alignments across all scales. The experimental results show that our method outperforms the state-of-the-art methods by 5.53% in terms of top-1 and 5.35% in terms of top-5 on text-based person search dataset. The code is available at https://github.com/TencentYoutuResearch/PersonReID-NAFS