 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocate before Answering: Answer Guided Question Localization for Video Question Answering
Oct 05, 2022
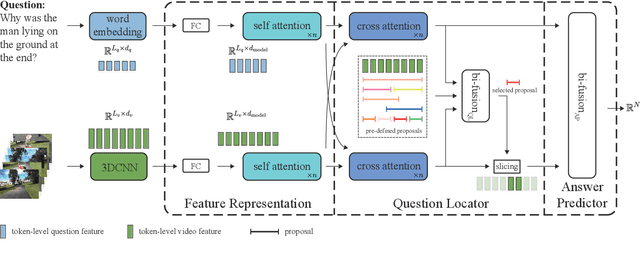
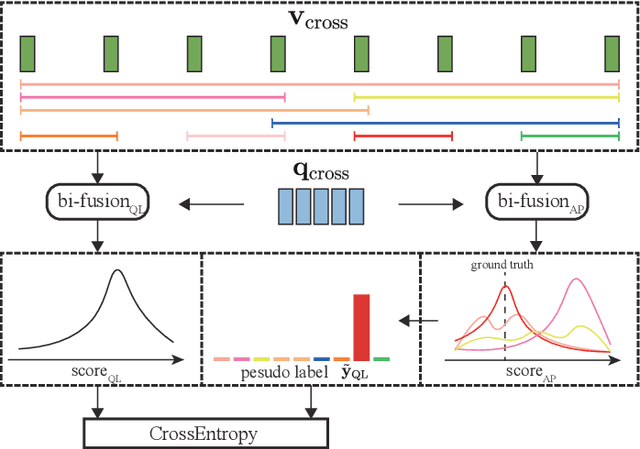
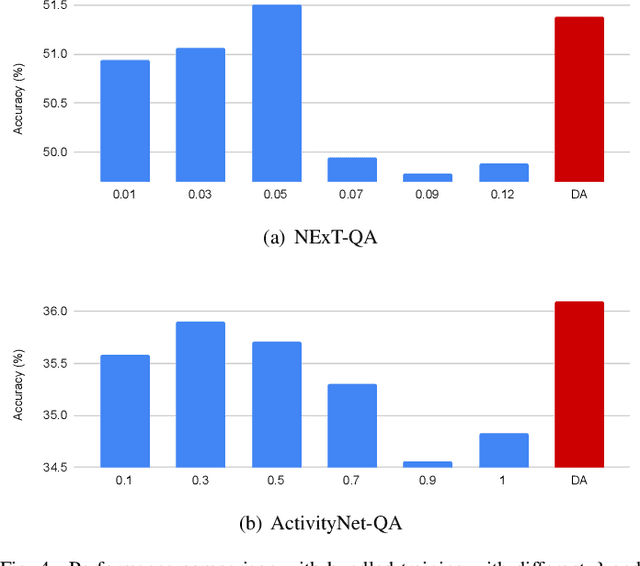
Video question answering (VideoQA) is an essential task in vision-language understanding, which has attracted numerous research attention recently. Nevertheless, existing works mostly achieve promising performances on short videos of duration within 15 seconds. For VideoQA on minute-level long-term videos, those methods are likely to fail because of lacking the ability to deal with noise and redundancy caused by scene changes and multiple actions in the video. Considering the fact that the question often remains concentrated in a short temporal range, we propose to first locate the question to a segment in the video and then infer the answer using the located segment only. Under this scheme, we propose "Locate before Answering" (LocAns), a novel approach that integrates a question locator and an answer predictor into an end-to-end model. During the training phase, the available answer label not only serves as the supervision signal of the answer predictor, but also is used to generate pseudo temporal labels for the question locator. Moreover, we design a decoupled alternative training strategy to update the two modules separately. In the experiments, LocAns achieves state-of-the-art performance on two modern long-term VideoQA datasets NExT-QA and ActivityNet-QA, and its qualitative examples show the reliable performance of the question localization.
Video Moment Retrieval from Text Queries via Single Frame Annotation
Apr 26, 2022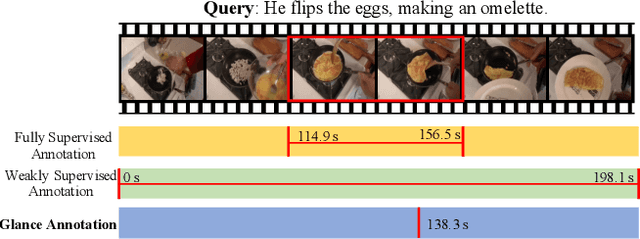
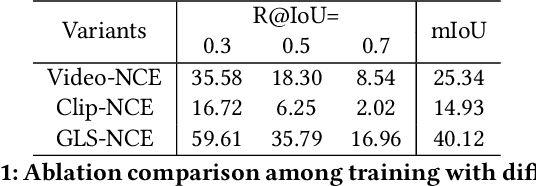
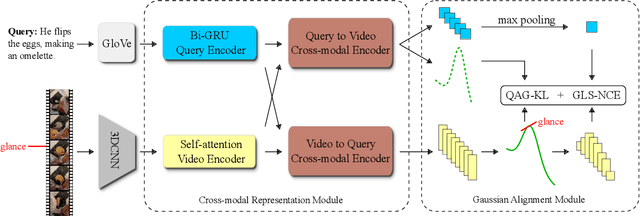
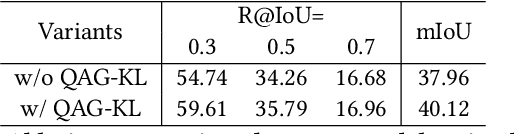
Video moment retrieval aims at finding the start and end timestamps of a moment (part of a video) described by a given natural language query. Fully supervised methods need complete temporal boundary annotations to achieve promising results, which is costly since the annotator needs to watch the whole moment. Weakly supervised methods only rely on the paired video and query, but the performance is relatively poor. In this paper, we look closer into the annotation process and propose a new paradigm called "glance annotation". This paradigm requires the timestamp of only one single random frame, which we refer to as a "glance", within the temporal boundary of the fully supervised counterpart. We argue this is beneficial because comparing to weak supervision, trivial cost is added yet more potential in performance is provided. Under the glance annotation setting, we propose a method named as Video moment retrieval via Glance Annotation (ViGA) based on contrastive learning. ViGA cuts the input video into clips and contrasts between clips and queries, in which glance guided Gaussian distributed weights are assigned to all clips. Our extensive experiments indicate that ViGA achieves better results than the state-of-the-art weakly supervised methods by a large margin, even comparable to fully supervised methods in some cases.