 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTextFlux: An OCR-Free DiT Model for High-Fidelity Multilingual Scene Text Synthesis
May 23, 2025


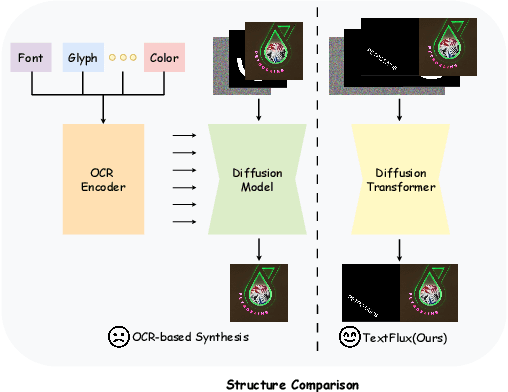
Diffusion-based scene text synthesis has progressed rapidly, yet existing methods commonly rely on additional visual conditioning modules and require large-scale annotated data to support multilingual generation. In this work, we revisit the necessity of complex auxiliary modules and further explore an approach that simultaneously ensures glyph accuracy and achieves high-fidelity scene integration, by leveraging diffusion models' inherent capabilities for contextual reasoning. To this end, we introduce TextFlux, a DiT-based framework that enables multilingual scene text synthesis. The advantages of TextFlux can be summarized as follows: (1) OCR-free model architecture. TextFlux eliminates the need for OCR encoders (additional visual conditioning modules) that are specifically used to extract visual text-related features. (2) Strong multilingual scalability. TextFlux is effective in low-resource multilingual settings, and achieves strong performance in newly added languages with fewer than 1,000 samples. (3) Streamlined training setup. TextFlux is trained with only 1% of the training data required by competing methods. (4) Controllable multi-line text generation. TextFlux offers flexible multi-line synthesis with precise line-level control, outperforming methods restricted to single-line or rigid layouts. Extensive experiments and visualizations demonstrate that TextFlux outperforms previous methods in both qualitative and quantitative evaluations.
Aligning Anime Video Generation with Human Feedback
Apr 14, 2025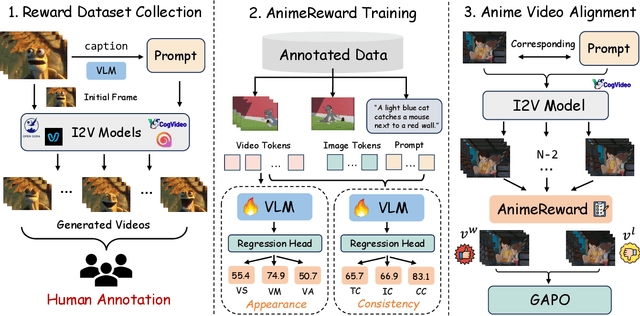

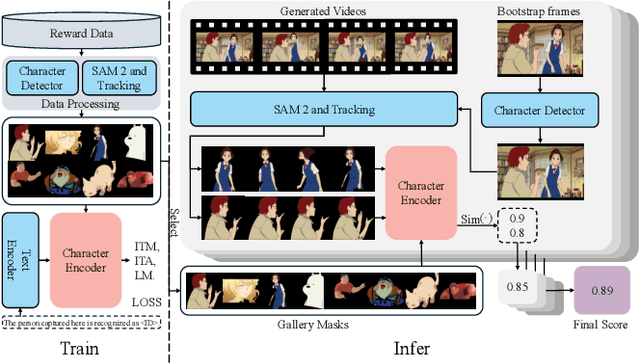
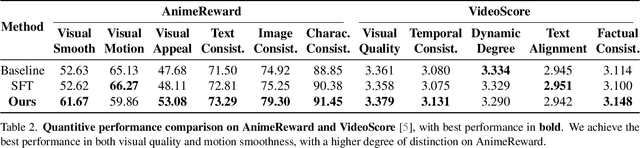
Anime video generation faces significant challenges due to the scarcity of anime data and unusual motion patterns, leading to issues such as motion distortion and flickering artifacts, which result in misalignment with human preferences. Existing reward models, designed primarily for real-world videos, fail to capture the unique appearance and consistency requirements of anime. In this work, we propose a pipeline to enhance anime video generation by leveraging human feedback for better alignment. Specifically, we construct the first multi-dimensional reward dataset for anime videos, comprising 30k human-annotated samples that incorporating human preferences for both visual appearance and visual consistency. Based on this, we develop AnimeReward, a powerful reward model that employs specialized vision-language models for different evaluation dimensions to guide preference alignment. Furthermore, we introduce Gap-Aware Preference Optimization (GAPO), a novel training method that explicitly incorporates preference gaps into the optimization process, enhancing alignment performance and efficiency. Extensive experiment results show that AnimeReward outperforms existing reward models, and the inclusion of GAPO leads to superior alignment in both quantitative benchmarks and human evaluations, demonstrating the effectiveness of our pipeline in enhancing anime video quality. Our dataset and code will be publicly available.
AniSora: Exploring the Frontiers of Animation Video Generation in the Sora Era
Dec 19, 2024



Animation has gained significant interest in the recent film and TV industry. Despite the success of advanced video generation models like Sora, Kling, and CogVideoX in generating natural videos, they lack the same effectiveness in handling animation videos. Evaluating animation video generation is also a great challenge due to its unique artist styles, violating the laws of physics and exaggerated motions. In this paper, we present a comprehensive system, AniSora, designed for animation video generation, which includes a data processing pipeline, a controllable generation model, and an evaluation dataset. Supported by the data processing pipeline with over 10M high-quality data, the generation model incorporates a spatiotemporal mask module to facilitate key animation production functions such as image-to-video generation, frame interpolation, and localized image-guided animation. We also collect an evaluation benchmark of 948 various animation videos, the evaluation on VBench and human double-blind test demonstrates consistency in character and motion, achieving state-of-the-art results in animation video generation. Our evaluation benchmark will be publicly available at https://github.com/bilibili/Index-anisora.
Exploring the Frontiers of Animation Video Generation in the Sora Era: Method, Dataset and Benchmark
Dec 13, 2024Animation has gained significant interest in the recent film and TV industry. Despite the success of advanced video generation models like Sora, Kling, and CogVideoX in generating natural videos, they lack the same effectiveness in handling animation videos. Evaluating animation video generation is also a great challenge due to its unique artist styles, violating the laws of physics and exaggerated motions. In this paper, we present a comprehensive system, AniSora, designed for animation video generation, which includes a data processing pipeline, a controllable generation model, and an evaluation dataset. Supported by the data processing pipeline with over 10M high-quality data, the generation model incorporates a spatiotemporal mask module to facilitate key animation production functions such as image-to-video generation, frame interpolation, and localized image-guided animation. We also collect an evaluation benchmark of 948 various animation videos, the evaluation on VBench and human double-blind test demonstrates consistency in character and motion, achieving state-of-the-art results in animation video generation. %We also collect an evaluation benchmark of 948 various animation videos, with specifically developed metrics for animation video generation. Our model access API and evaluation benchmark will be publicly available.
DNTextSpotter: Arbitrary-Shaped Scene Text Spotting via Improved Denoising Training
Aug 01, 2024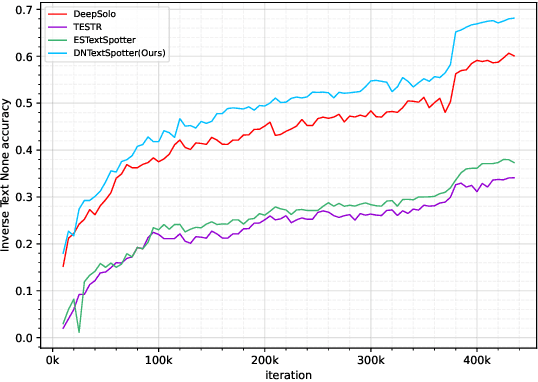
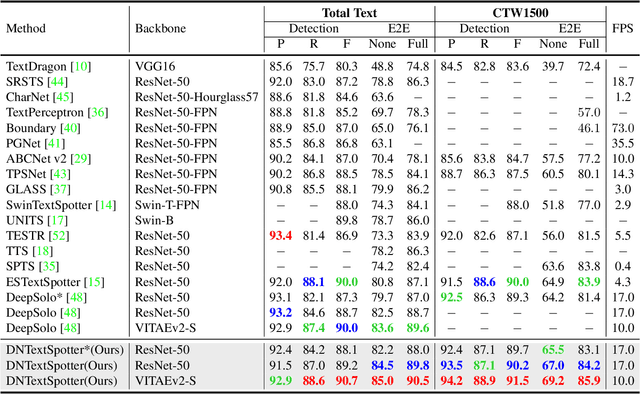
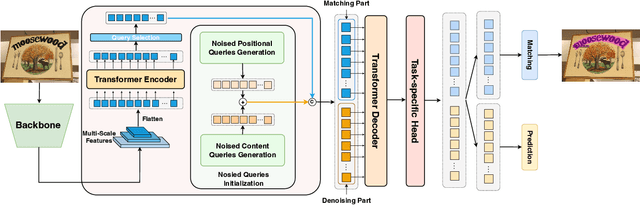
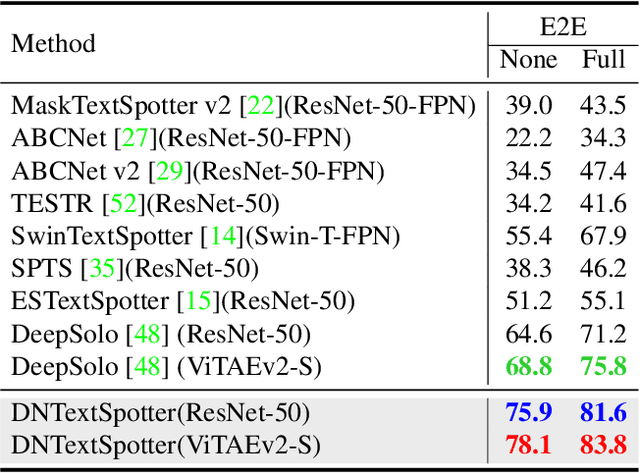
More and more end-to-end text spotting methods based on Transformer architecture have demonstrated superior performance. These methods utilize a bipartite graph matching algorithm to perform one-to-one optimal matching between predicted objects and actual objects. However, the instability of bipartite graph matching can lead to inconsistent optimization targets, thereby affecting the training performance of the model. Existing literature applies denoising training to solve the problem of bipartite graph matching instability in object detection tasks. Unfortunately, this denoising training method cannot be directly applied to text spotting tasks, as these tasks need to perform irregular shape detection tasks and more complex text recognition tasks than classification. To address this issue, we propose a novel denoising training method (DNTextSpotter) for arbitrary-shaped text spotting. Specifically, we decompose the queries of the denoising part into noised positional queries and noised content queries. We use the four Bezier control points of the Bezier center curve to generate the noised positional queries. For the noised content queries, considering that the output of the text in a fixed positional order is not conducive to aligning position with content, we employ a masked character sliding method to initialize noised content queries, thereby assisting in the alignment of text content and position. To improve the model's perception of the background, we further utilize an additional loss function for background characters classification in the denoising training part.Although DNTextSpotter is conceptually simple, it outperforms the state-of-the-art methods on four benchmarks (Total-Text, SCUT-CTW1500, ICDAR15, and Inverse-Text), especially yielding an improvement of 11.3% against the best approach in Inverse-Text dataset.
Video Moment Retrieval from Text Queries via Single Frame Annotation
Apr 26, 2022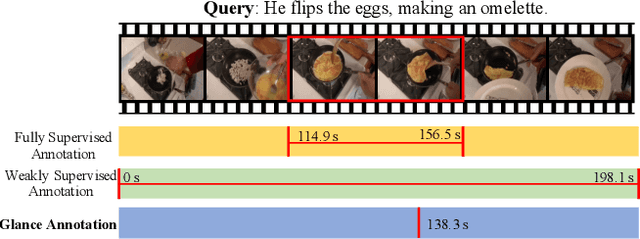
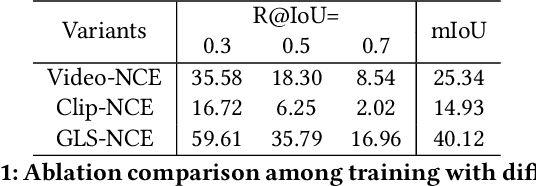
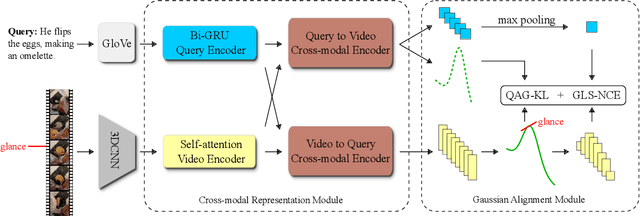
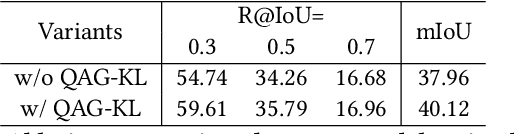
Video moment retrieval aims at finding the start and end timestamps of a moment (part of a video) described by a given natural language query. Fully supervised methods need complete temporal boundary annotations to achieve promising results, which is costly since the annotator needs to watch the whole moment. Weakly supervised methods only rely on the paired video and query, but the performance is relatively poor. In this paper, we look closer into the annotation process and propose a new paradigm called "glance annotation". This paradigm requires the timestamp of only one single random frame, which we refer to as a "glance", within the temporal boundary of the fully supervised counterpart. We argue this is beneficial because comparing to weak supervision, trivial cost is added yet more potential in performance is provided. Under the glance annotation setting, we propose a method named as Video moment retrieval via Glance Annotation (ViGA) based on contrastive learning. ViGA cuts the input video into clips and contrasts between clips and queries, in which glance guided Gaussian distributed weights are assigned to all clips. Our extensive experiments indicate that ViGA achieves better results than the state-of-the-art weakly supervised methods by a large margin, even comparable to fully supervised methods in some cases.
Boosting the Performance of Video Compression Artifact Reduction with Reference Frame Proposals and Frequency Domain Information
May 31, 2021
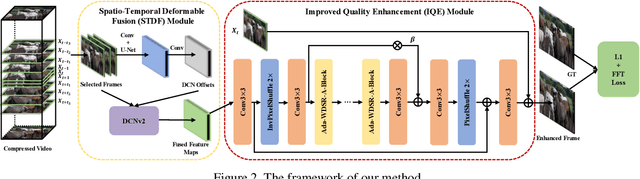
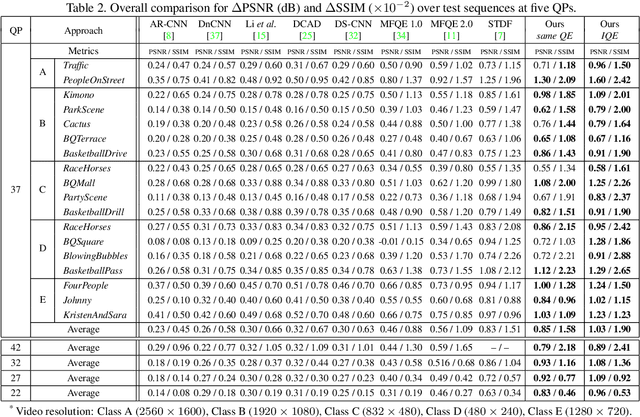
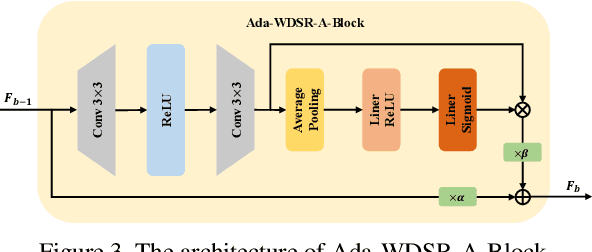
Many deep learning based video compression artifact removal algorithms have been proposed to recover high-quality videos from low-quality compressed videos. Recently, methods were proposed to mine spatiotemporal information via utilizing multiple neighboring frames as reference frames. However, these post-processing methods take advantage of adjacent frames directly, but neglect the information of the video itself, which can be exploited. In this paper, we propose an effective reference frame proposal strategy to boost the performance of the existing multi-frame approaches. Besides, we introduce a loss based on fast Fourier transformation~(FFT) to further improve the effectiveness of restoration. Experimental results show that our method achieves better fidelity and perceptual performance on MFQE 2.0 dataset than the state-of-the-art methods. And our method won Track 1 and Track 2, and was ranked the 2nd in Track 3 of NTIRE 2021 Quality enhancement of heavily compressed videos Challenge.
Dance Generation with Style Embedding: Learning and Transferring Latent Representations of Dance Styles
Apr 30, 2021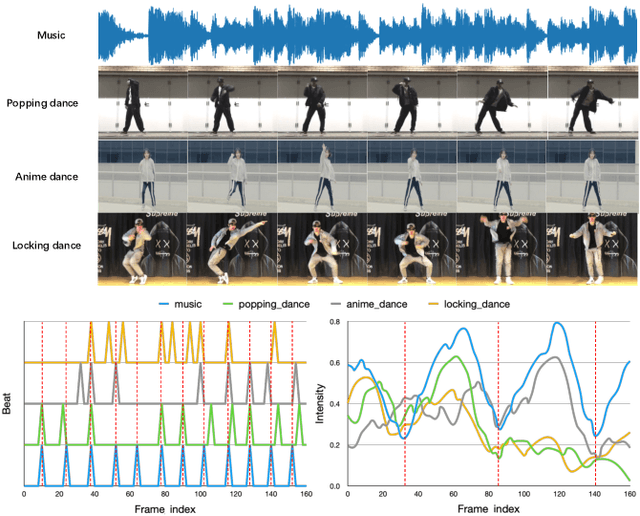
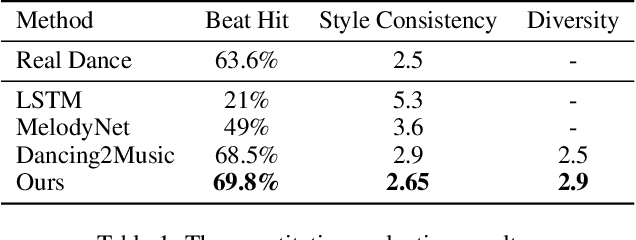
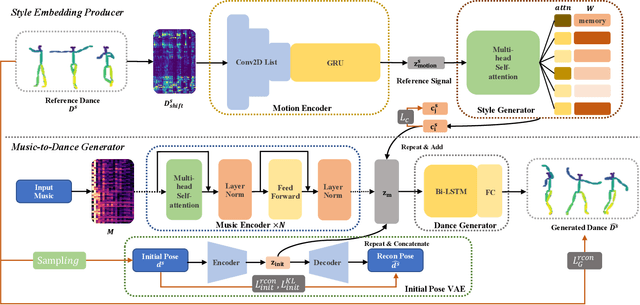
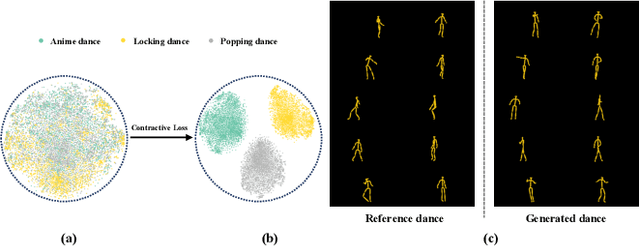
Choreography refers to creation of dance steps and motions for dances according to the latent knowledge in human mind, where the created dance motions are in general style-specific and consistent. So far, such latent style-specific knowledge about dance styles cannot be represented explicitly in human language and has not yet been learned in previous works on music-to-dance generation tasks. In this paper, we propose a novel music-to-dance synthesis framework with controllable style embeddings. These embeddings are learned representations of style-consistent kinematic abstraction of reference dance clips, which act as controllable factors to impose style constraints on dance generation in a latent manner. Thus, the dance styles can be transferred to dance motions by merely modifying the style embeddings. To support this study, we build a large music-to-dance dataset. The qualitative and quantitative evaluations demonstrate the advantage of our proposed framework, as well as the ability of synthesizing diverse styles of dances from identical music via style embeddings.
Non-Local ConvLSTM for Video Compression Artifact Reduction
Oct 27, 2019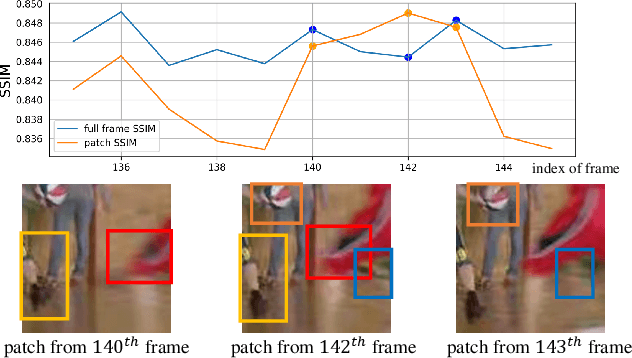
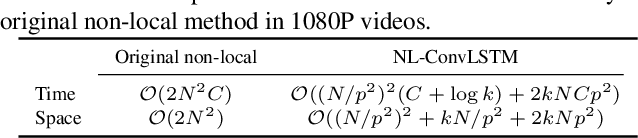
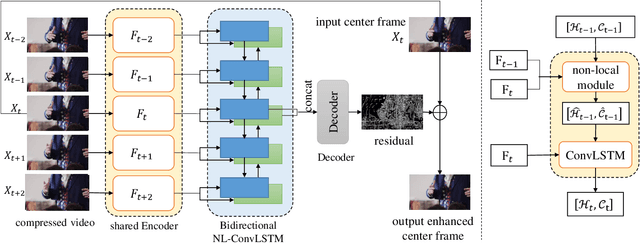

Video compression artifact reduction aims to recover high-quality videos from low-quality compressed videos. Most existing approaches use a single neighboring frame or a pair of neighboring frames (preceding and/or following the target frame) for this task. Furthermore, as frames of high quality overall may contain low-quality patches, and high-quality patches may exist in frames of low quality overall, current methods focusing on nearby peak-quality frames (PQFs) may miss high-quality details in low-quality frames. To remedy these shortcomings, in this paper we propose a novel end-to-end deep neural network called non-local ConvLSTM (NL-ConvLSTM in short) that exploits multiple consecutive frames. An approximate non-local strategy is introduced in NL-ConvLSTM to capture global motion patterns and trace the spatiotemporal dependency in a video sequence. This approximate strategy makes the non-local module work in a fast and low space-cost way. Our method uses the preceding and following frames of the target frame to generate a residual, from which a higher quality frame is reconstructed. Experiments on two datasets show that NL-ConvLSTM outperforms the existing methods.
Macro action selection with deep reinforcement learning in StarCraft
Dec 02, 2018

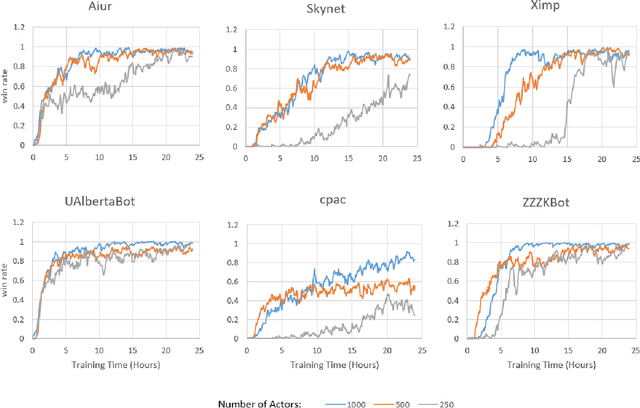
StarCraft (SC) is one of the most popular and successful Real Time Strategy (RTS) games. In recent years, SC is also considered as a testbed for AI research, due to its enormous state space, hidden information, multi-agent collaboration and so on. Thanks to the annual AIIDE and CIG competitions, a growing number of bots are proposed and being continuously improved. However, a big gap still remains between the top bot and the professional human players. One vital reason is that current bots mainly rely on predefined rules to perform macro actions. These rules are not scalable and efficient enough to cope with the large but partially observed macro state space in SC. In this paper, we propose a DRL based framework to do macro action selection. Our framework combines the reinforcement learning approach Ape-X DQN with Long-Short-Term-Memory (LSTM) to improve the macro action selection in bot. We evaluate our bot, named as LastOrder, on the AIIDE 2017 StarCraft AI competition bots set. Our bot achieves overall 83% win-rate, outperforming 26 bots in total 28 entrants.