 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDivide-and-Conquer Inference for Large-Scale Visual Recognition with Multimodal Large Language Models
May 24, 2026Multimodal Large Language Models (MLLMs) have demonstrated strong capabilities across a wide range of vision language tasks. However, when applied to large scale image classification, their performance degrades significantly as the label space expands a phenomenon we define as Performance Collapse in Long Sequence Recognition. Through an information theoretic analysis, we reveal that this collapse stems from a fundamental conflict between the escalating information entropy and the prominent attention dilution and decay within attention mechanisms, which impairs the model's ability to maintain a sufficient signal-to-noise ratio when processing extremely long prompts. To mitigate this, we propose Divide-and-Conquer Inference (DCI), a novel test-time scaling strategy for visual recognition with MLLMs. DCI recursively decomposes complex global classification tasks into multiple simpler, localized subproblems and employs a dynamic pruning mechanism to compress the search space. This method effectively improves the local signal to noise ratio and model accuracy by mitigating the inherent weight dilution issues in long-sequence inference. Moreover, while traditional self-attention incurs a prohibitive quadratic computational complexity, DCI achieves more favorable scaling behavior and substantially accelerates inference in large scale classification scenarios. Extensive experiments on benchmarks such as ImageNet-1K and ImageNet-21K demonstrate that DCI consistently improves classification accuracy. This enables lightweight open-source models to rival or even surpass frontier closed-source giants without any additional training or fine-tuning. As a model-agnostic, plug-and-play paradigm, DCI offers an efficient approach for scaling the inferential precision of MLLMs in large-scale scenarios.
Uni-ViGU: Towards Unified Video Generation and Understanding via A Diffusion-Based Video Generator
Apr 09, 2026Unified multimodal models integrating visual understanding and generation face a fundamental challenge: visual generation incurs substantially higher computational costs than understanding, particularly for video. This imbalance motivates us to invert the conventional paradigm: rather than extending understanding-centric MLLMs to support generation, we propose Uni-ViGU, a framework that unifies video generation and understanding by extending a video generator as the foundation. We introduce a unified flow method that performs continuous flow matching for video and discrete flow matching for text within a single process, enabling coherent multimodal generation. We further propose a modality-driven MoE-based framework that augments Transformer blocks with lightweight layers for text generation while preserving generative priors. To repurpose generation knowledge for understanding, we design a bidirectional training mechanism with two stages: Knowledge Recall reconstructs input prompts to leverage learned text-video correspondences, while Capability Refinement fine-tunes on detailed captions to establish discriminative shared representations. Experiments demonstrate that Uni-ViGU achieves competitive performance on both video generation and understanding, validating generation-centric architectures as a scalable path toward unified multimodal intelligence. Project Page and Code: https://fr0zencrane.github.io/uni-vigu-page/.
CASR: A Robust Cyclic Framework for Arbitrary Large-Scale Super-Resolution with Distribution Alignment and Self-Similarity Awareness
Feb 25, 2026Arbitrary-Scale SR (ASISR) remains fundamentally limited by cross-scale distribution shift: once the inference scale leaves the training range, noise, blur, and artifacts accumulate sharply. We revisit this challenge from a cross-scale distribution transition perspective and propose CASR, a simple yet highly efficient cyclic SR framework that reformulates ultra-magnification as a sequence of in-distribution scale transitions. This design ensures stable inference at arbitrary scales while requiring only a single model. CASR tackles two major bottlenecks: distribution drift across iterations and patch-wise diffusion inconsistencies. The proposed SDAM module aligns structural distributions via superpixel aggregation, preventing error accumulation, while SARM module restores high-frequency textures by enforcing autocorrelation and embedding LR self-similarity priors. Despite using only a single model, our approach significantly reduces distribution drift, preserves long-range texture consistency, and achieves superior generalization even at extreme magnification.
AutoQRA: Joint Optimization of Mixed-Precision Quantization and Low-rank Adapters for Efficient LLM Fine-Tuning
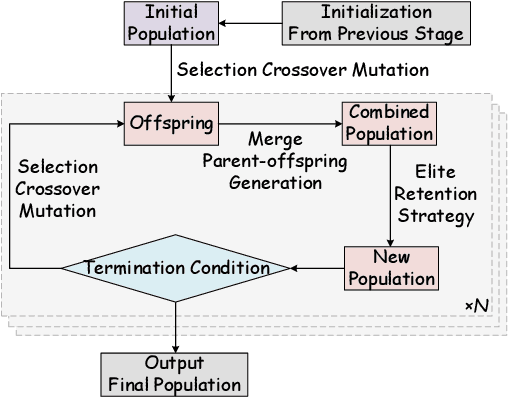
Feb 25, 2026Quantization followed by parameter-efficient fine-tuning has emerged as a promising paradigm for downstream adaptation under tight GPU memory constraints. However, this sequential pipeline fails to leverage the intricate interaction between quantization bit-width and LoRA rank. Specifically, a carefully optimized quantization allocation with low quantization error does not always translate to strong fine-tuning performance, and different bit-width and rank configurations can lead to significantly varying outcomes under the same memory budget. To address this limitation, we propose AutoQRA, a joint optimization framework that simultaneously optimizes the bit-width and LoRA rank configuration for each layer during the mixed quantized fine-tuning process. To tackle the challenges posed by the large discrete search space and the high evaluation cost associated with frequent fine-tuning iterations, AutoQRA decomposes the optimization process into two stages. First, it first conducts a global multi-fidelity evolutionary search, where the initial population is warm-started by injecting layer-wise importance priors. This stage employs specific operators and a performance model to efficiently screen candidate configurations. Second, trust-region Bayesian optimization is applied to locally refine promising regions of the search space and identify optimal configurations under the given memory budget. This approach enables active compensation for quantization noise in specific layers during training. Experiments show that AutoQRA achieves performance close to full-precision fine-tuning with a memory footprint comparable to uniform 4-bit methods.
SoulX-FlashHead: Oracle-guided Generation of Infinite Real-time Streaming Talking Heads
Feb 07, 2026Achieving a balance between high-fidelity visual quality and low-latency streaming remains a formidable challenge in audio-driven portrait generation. Existing large-scale models often suffer from prohibitive computational costs, while lightweight alternatives typically compromise on holistic facial representations and temporal stability. In this paper, we propose SoulX-FlashHead, a unified 1.3B-parameter framework designed for real-time, infinite-length, and high-fidelity streaming video generation. To address the instability of audio features in streaming scenarios, we introduce Streaming-Aware Spatiotemporal Pre-training equipped with a Temporal Audio Context Cache mechanism, which ensures robust feature extraction from short audio fragments. Furthermore, to mitigate the error accumulation and identity drift inherent in long-sequence autoregressive generation, we propose Oracle-Guided Bidirectional Distillation, leveraging ground-truth motion priors to provide precise physical guidance. We also present VividHead, a large-scale, high-quality dataset containing 782 hours of strictly aligned footage to support robust training. Extensive experiments demonstrate that SoulX-FlashHead achieves state-of-the-art performance on HDTF and VFHQ benchmarks. Notably, our Lite variant achieves an inference speed of 96 FPS on a single NVIDIA RTX 4090, facilitating ultra-fast interaction without sacrificing visual coherence.
SoulX-FlashTalk: Real-Time Infinite Streaming of Audio-Driven Avatars via Self-Correcting Bidirectional Distillation
Jan 06, 2026Deploying massive diffusion models for real-time, infinite-duration, audio-driven avatar generation presents a significant engineering challenge, primarily due to the conflict between computational load and strict latency constraints. Existing approaches often compromise visual fidelity by enforcing strictly unidirectional attention mechanisms or reducing model capacity. To address this problem, we introduce \textbf{SoulX-FlashTalk}, a 14B-parameter framework optimized for high-fidelity real-time streaming. Diverging from conventional unidirectional paradigms, we use a \textbf{Self-correcting Bidirectional Distillation} strategy that retains bidirectional attention within video chunks. This design preserves critical spatiotemporal correlations, significantly enhancing motion coherence and visual detail. To ensure stability during infinite generation, we incorporate a \textbf{Multi-step Retrospective Self-Correction Mechanism}, enabling the model to autonomously recover from accumulated errors and preventing collapse. Furthermore, we engineered a full-stack inference acceleration suite incorporating hybrid sequence parallelism, Parallel VAE, and kernel-level optimizations. Extensive evaluations confirm that SoulX-FlashTalk is the first 14B-scale system to achieve a \textbf{sub-second start-up latency (0.87s)} while reaching a real-time throughput of \textbf{32 FPS}, setting a new standard for high-fidelity interactive digital human synthesis.
RAP: Real-time Audio-driven Portrait Animation with Video Diffusion Transformer
Aug 07, 2025Audio-driven portrait animation aims to synthesize realistic and natural talking head videos from an input audio signal and a single reference image. While existing methods achieve high-quality results by leveraging high-dimensional intermediate representations and explicitly modeling motion dynamics, their computational complexity renders them unsuitable for real-time deployment. Real-time inference imposes stringent latency and memory constraints, often necessitating the use of highly compressed latent representations. However, operating in such compact spaces hinders the preservation of fine-grained spatiotemporal details, thereby complicating audio-visual synchronization RAP (Real-time Audio-driven Portrait animation), a unified framework for generating high-quality talking portraits under real-time constraints. Specifically, RAP introduces a hybrid attention mechanism for fine-grained audio control, and a static-dynamic training-inference paradigm that avoids explicit motion supervision. Through these techniques, RAP achieves precise audio-driven control, mitigates long-term temporal drift, and maintains high visual fidelity. Extensive experiments demonstrate that RAP achieves state-of-the-art performance while operating under real-time constraints.
Marrying Autoregressive Transformer and Diffusion with Multi-Reference Autoregression
Jun 11, 2025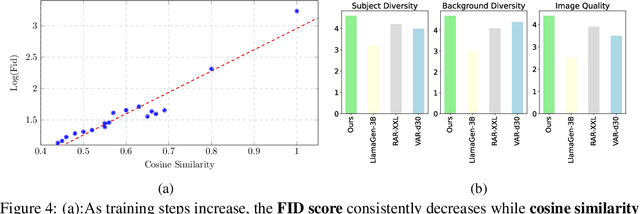

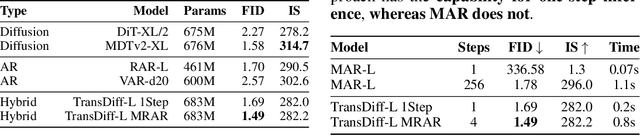
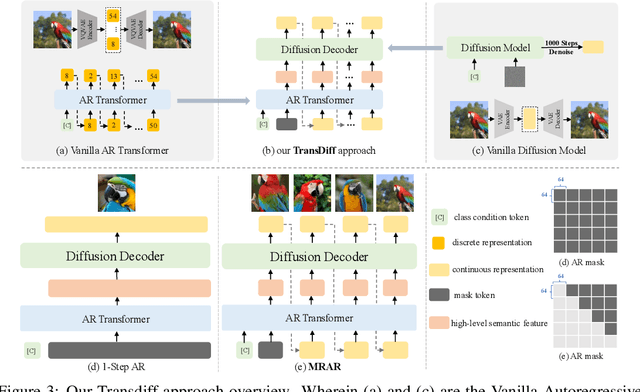
We introduce TransDiff, the first image generation model that marries Autoregressive (AR) Transformer with diffusion models. In this joint modeling framework, TransDiff encodes labels and images into high-level semantic features and employs a diffusion model to estimate the distribution of image samples. On the ImageNet 256x256 benchmark, TransDiff significantly outperforms other image generation models based on standalone AR Transformer or diffusion models. Specifically, TransDiff achieves a Fr\'echet Inception Distance (FID) of 1.61 and an Inception Score (IS) of 293.4, and further provides x2 faster inference latency compared to state-of-the-art methods based on AR Transformer and x112 faster inference compared to diffusion-only models. Furthermore, building on the TransDiff model, we introduce a novel image generation paradigm called Multi-Reference Autoregression (MRAR), which performs autoregressive generation by predicting the next image. MRAR enables the model to reference multiple previously generated images, thereby facilitating the learning of more diverse representations and improving the quality of generated images in subsequent iterations. By applying MRAR, the performance of TransDiff is improved, with the FID reduced from 1.61 to 1.42. We expect TransDiff to open up a new frontier in the field of image generation.
TextFlux: An OCR-Free DiT Model for High-Fidelity Multilingual Scene Text Synthesis
May 23, 2025


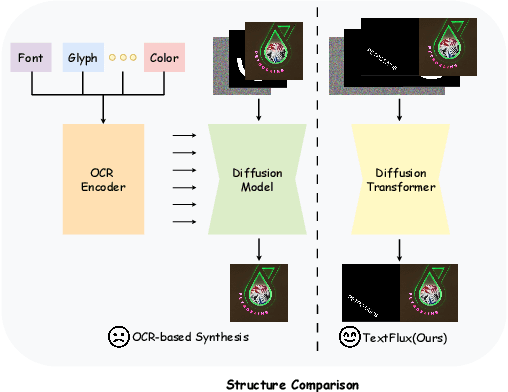
Diffusion-based scene text synthesis has progressed rapidly, yet existing methods commonly rely on additional visual conditioning modules and require large-scale annotated data to support multilingual generation. In this work, we revisit the necessity of complex auxiliary modules and further explore an approach that simultaneously ensures glyph accuracy and achieves high-fidelity scene integration, by leveraging diffusion models' inherent capabilities for contextual reasoning. To this end, we introduce TextFlux, a DiT-based framework that enables multilingual scene text synthesis. The advantages of TextFlux can be summarized as follows: (1) OCR-free model architecture. TextFlux eliminates the need for OCR encoders (additional visual conditioning modules) that are specifically used to extract visual text-related features. (2) Strong multilingual scalability. TextFlux is effective in low-resource multilingual settings, and achieves strong performance in newly added languages with fewer than 1,000 samples. (3) Streamlined training setup. TextFlux is trained with only 1% of the training data required by competing methods. (4) Controllable multi-line text generation. TextFlux offers flexible multi-line synthesis with precise line-level control, outperforming methods restricted to single-line or rigid layouts. Extensive experiments and visualizations demonstrate that TextFlux outperforms previous methods in both qualitative and quantitative evaluations.
Efficient Fine-Tuning of Quantized Models via Adaptive Rank and Bitwidth
May 02, 2025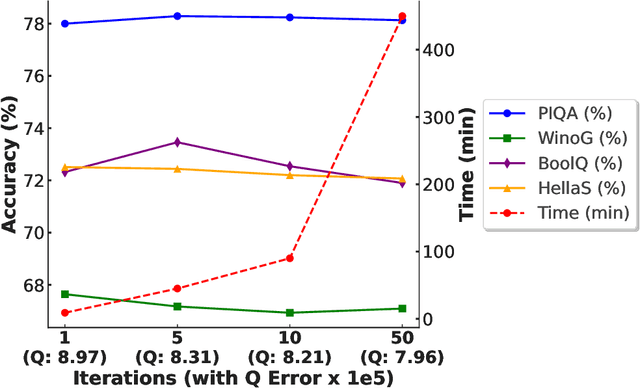
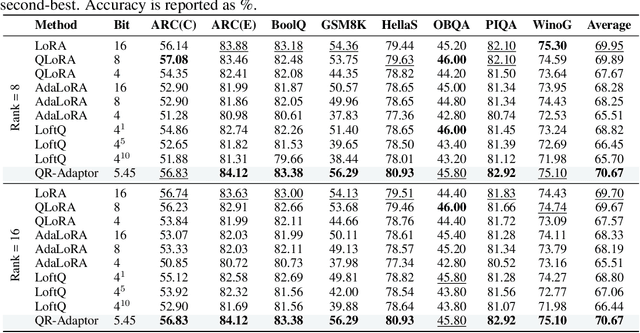
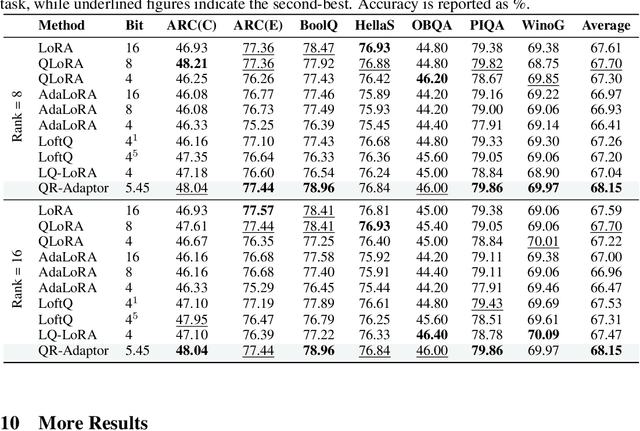
QLoRA effectively combines low-bit quantization and LoRA to achieve memory-friendly fine-tuning for large language models (LLM). Recently, methods based on SVD for continuous update iterations to initialize LoRA matrices to accommodate quantization errors have generally failed to consistently improve performance. Dynamic mixed precision is a natural idea for continuously improving the fine-tuning performance of quantized models, but previous methods often optimize low-rank subspaces or quantization components separately, without considering their synergy. To address this, we propose \textbf{QR-Adaptor}, a unified, gradient-free strategy that uses partial calibration data to jointly search the quantization components and the rank of low-rank spaces for each layer, thereby continuously improving model performance. QR-Adaptor does not minimize quantization error but treats precision and rank allocation as a discrete optimization problem guided by actual downstream performance and memory usage. Compared to state-of-the-art (SOTA) quantized LoRA fine-tuning methods, our approach achieves a 4.89\% accuracy improvement on GSM8K, and in some cases even outperforms the 16-bit fine-tuned model while maintaining the memory footprint of the 4-bit setting.