 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMarrying Autoregressive Transformer and Diffusion with Multi-Reference Autoregression
Jun 11, 2025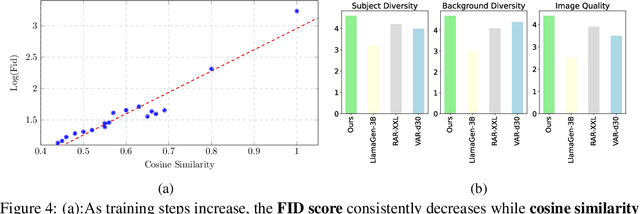

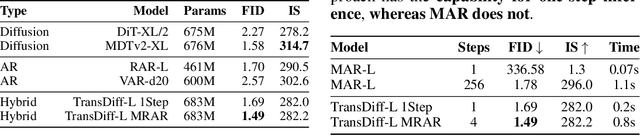
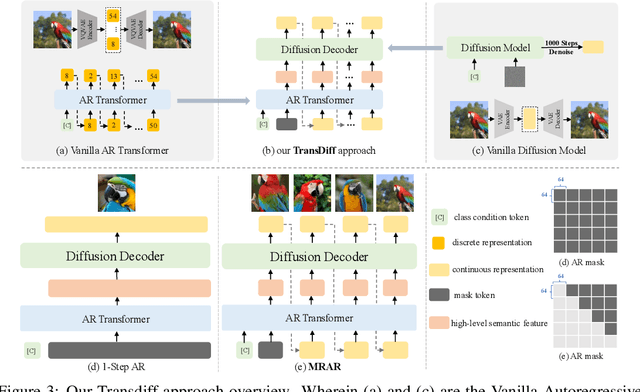
We introduce TransDiff, the first image generation model that marries Autoregressive (AR) Transformer with diffusion models. In this joint modeling framework, TransDiff encodes labels and images into high-level semantic features and employs a diffusion model to estimate the distribution of image samples. On the ImageNet 256x256 benchmark, TransDiff significantly outperforms other image generation models based on standalone AR Transformer or diffusion models. Specifically, TransDiff achieves a Fr\'echet Inception Distance (FID) of 1.61 and an Inception Score (IS) of 293.4, and further provides x2 faster inference latency compared to state-of-the-art methods based on AR Transformer and x112 faster inference compared to diffusion-only models. Furthermore, building on the TransDiff model, we introduce a novel image generation paradigm called Multi-Reference Autoregression (MRAR), which performs autoregressive generation by predicting the next image. MRAR enables the model to reference multiple previously generated images, thereby facilitating the learning of more diverse representations and improving the quality of generated images in subsequent iterations. By applying MRAR, the performance of TransDiff is improved, with the FID reduced from 1.61 to 1.42. We expect TransDiff to open up a new frontier in the field of image generation.
Baichuan-M1: Pushing the Medical Capability of Large Language Models
Feb 18, 2025



The current generation of large language models (LLMs) is typically designed for broad, general-purpose applications, while domain-specific LLMs, especially in vertical fields like medicine, remain relatively scarce. In particular, the development of highly efficient and practical LLMs for the medical domain is challenging due to the complexity of medical knowledge and the limited availability of high-quality data. To bridge this gap, we introduce Baichuan-M1, a series of large language models specifically optimized for medical applications. Unlike traditional approaches that simply continue pretraining on existing models or apply post-training to a general base model, Baichuan-M1 is trained from scratch with a dedicated focus on enhancing medical capabilities. Our model is trained on 20 trillion tokens and incorporates a range of effective training methods that strike a balance between general capabilities and medical expertise. As a result, Baichuan-M1 not only performs strongly across general domains such as mathematics and coding but also excels in specialized medical fields. We have open-sourced Baichuan-M1-14B, a mini version of our model, which can be accessed through the following links.
Enhancing Training Data Attribution for Large Language Models with Fitting Error Consideration
Oct 02, 2024

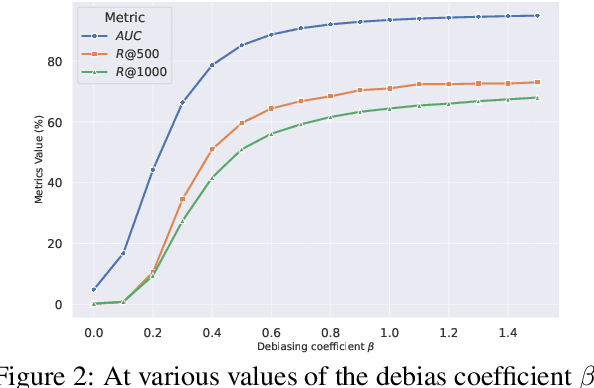
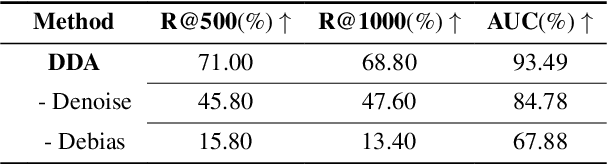
The black-box nature of large language models (LLMs) poses challenges in interpreting results, impacting issues such as data intellectual property protection and hallucination tracing. Training data attribution (TDA) methods are considered effective solutions to address these challenges. Most recent TDA methods rely on influence functions, assuming the model achieves minimized empirical risk. However, achieving this criterion is difficult, and sourcing accuracy can be compromised by fitting errors during model training. In this paper, we introduce a novel TDA method called Debias and Denoise Attribution (DDA), which enhances influence functions by addressing fitting errors. Specifically, the debias strategy seeks to improve the performance of influence functions by eliminating the knowledge bias present in the base model before fine-tuning, while the denoise strategy aims to reduce discrepancies in influence scores arising from varying degrees of fitting during the training process through smoothing techniques. Experimental results demonstrate that our method significantly outperforms existing approaches, achieving an averaged AUC of 91.64%. Moreover, DDA exhibits strong generality and scalability across various sources and different-scale models like LLaMA2, QWEN2, and Mistral.
LLMDet: A Large Language Models Detection Tool
May 24, 2023



With the advancement of generative language models, the generated text has come remarkably close to high-quality human-authored text in terms of fluency and diversity. This calls for a highly practical detection tool that can identify the source of text, preferably pinpointing the language model it originates from. However, existing detection tools typically require access to language models and can only differentiate between machine-generated and human-authored text, failing to meet the requirements of rapid detection and text tracing. Therefore, in this paper, we propose an efficient, secure, and scalable detection tool called LLMDet, which calculates the proxy perplexity of text by utilizing the prior information of the model's next-token probabilities, obtained through pre-training. Subsequently, we use the self-watermarking information of the model, as measured by proxy perplexity, to detect the source of the text. We found that our method demonstrates impressive detection performance while ensuring speed and security, particularly achieving a recognition accuracy of 97.97\% for human-authored text. Furthermore, our detection tool also shows promising results in identifying the large language model (e.g., GPT-2, OPT, LLaMA, Vicuna...) responsible for the text. We release the code and processed data at \url{https://github.com/TrustedLLM/LLMDet}.
Cross-Model Comparative Loss for Enhancing Neuronal Utility in Language Understanding
Jan 10, 2023



Current natural language understanding (NLU) models have been continuously scaling up, both in terms of model size and input context, introducing more hidden and input neurons. While this generally improves performance on average, the extra neurons do not yield a consistent improvement for all instances. This is because some hidden neurons are redundant, and the noise mixed in input neurons tends to distract the model. Previous work mainly focuses on extrinsically reducing low-utility neurons by additional post- or pre-processing, such as network pruning and context selection, to avoid this problem. Beyond that, can we make the model reduce redundant parameters and suppress input noise by intrinsically enhancing the utility of each neuron? If a model can efficiently utilize neurons, no matter which neurons are ablated (disabled), the ablated submodel should perform no better than the original full model. Based on such a comparison principle between models, we propose a cross-model comparative loss for a broad range of tasks. Comparative loss is essentially a ranking loss on top of the task-specific losses of the full and ablated models, with the expectation that the task-specific loss of the full model is minimal. We demonstrate the universal effectiveness of comparative loss through extensive experiments on 14 datasets from 3 distinct NLU tasks based on 4 widely used pretrained language models, and find it particularly superior for models with few parameters or long input.