 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoulX-Transcriber: A Robust End-to-End Framework for Multi-Speaker Speech Transcription
Jun 01, 2026Recent advances in Automatic Speech Recognition (ASR) and Large Language Models (LLMs) have significantly improved speech understanding capabilities. However, multi-speaker speech transcription remains challenging task, constrained by highly similar speaker voices, rapid turn-taking transitions, overlapping utterances and inaccurate speaker boundary segmentation. These challenges become particularly pronounced in real-world conversational audio, where speaker dynamics and acoustic conditions are highly variable. This technical report presents SoulX-Transcriber, a unified multi-speaker transcription system that jointly models speaker diarization (SD) and ASR within an LLM-based framework. SoulX-Transcriber adopts a two-stage training strategy to improve both speaker discrimination and transcription robustness. In the first stage, speaker-aware multi-task continuous pre-training enhances speaker representation learning and boundary perception. In the second stage, supervised fine-tuning further optimizes the model for accurate end-to-end speaker-attributed transcription under complex multi-speaker conditions. SoulX-Transcriber delivers strong performance and robustness across multiple public benchmarks, including AliMeeting, AISHELL-4, and AMI, while maintaining high adaptability to multi-domain scenarios.
Video as Natural Augmentation: Towards Unified AI-Generated Image and Video Detection
May 21, 2026AI-generated content (AIGC) is rapidly improving, creating an urgent need for detectors that generalize across data sources, deployment pipelines, and visual modalities. A strongly generalizable detector should remain robust under distributional variations. However, we identify a consistent failure mode: SOTA AI-generated image detectors often collapse when applied to frames extracted from videos. Through systematic analysis, we show that this cross-modal gap arises from both entangled synthesis-agnostic video processing shifts, including color conversion, codec compression, resizing, and blur, and model-specific fingerprints introduced by modern video generators. Motivated by these findings, we propose VINA (Video as Natural Augmentation), a unified AIGC detection framework that jointly trains on image and video data. VINA uses video frames as physically grounded natural augmentations and further introduces a cross-modal supervised contrastive objective to align image and video representations under a shared real/fake decision boundary. Extensive experiments on 14 image, video, and in-the-wild benchmarks show that VINA delivers bidirectional gains, improves robustness and transferability, and achieves state-of-the-art performance across nearly all evaluated settings without complex augmentation or dataset-specific tuning.
SoulX-Duplug: Plug-and-Play Streaming State Prediction Module for Realtime Full-Duplex Speech Conversation
Mar 16, 2026Recent advances in spoken dialogue systems have brought increased attention to human-like full-duplex voice interactions. However, our comprehensive review of this field reveals several challenges, including the difficulty in obtaining training data, catastrophic forgetting, and limited scalability. In this work, we propose SoulX-Duplug, a plug-and-play streaming state prediction module for full-duplex spoken dialogue systems. By jointly performing streaming ASR, SoulX-Duplug explicitly leverages textual information to identify user intent, effectively serving as a semantic VAD. To promote fair evaluation, we introduce SoulX-Duplug-Eval, extending widely used benchmarks with improved bilingual coverage. Experimental results show that SoulX-Duplug enables low-latency streaming dialogue state control, and the system built upon it outperforms existing full-duplex models in overall turn management and latency performance. We have open-sourced SoulX-Duplug and SoulX-Duplug-Eval.
SoulX-LiveAct: Towards Hour-Scale Real-Time Human Animation with Neighbor Forcing and ConvKV Memory
Mar 12, 2026Autoregressive (AR) diffusion models offer a promising framework for sequential generation tasks such as video synthesis by combining diffusion modeling with causal inference. Although they support streaming generation, existing AR diffusion methods struggle to scale efficiently. In this paper, we identify two key challenges in hour-scale real-time human animation. First, most forcing strategies propagate sample-level representations with mismatched diffusion states, causing inconsistent learning signals and unstable convergence. Second, historical representations grow unbounded and lack structure, preventing effective reuse of cached states and severely limiting inference efficiency. To address these challenges, we propose Neighbor Forcing, a diffusion-step-consistent AR formulation that propagates temporally adjacent frames as latent neighbors under the same noise condition. This design provides a distribution-aligned and stable learning signal while preserving drifting throughout the AR chain. Building upon this, we introduce a structured ConvKV memory mechanism that compresses the keys and values in causal attention into a fixed-length representation, enabling constant-memory inference and truly infinite video generation without relying on short-term motion-frame memory. Extensive experiments demonstrate that our approach significantly improves training convergence, hour-scale generation quality, and inference efficiency compared to existing AR diffusion methods. Numerically, LiveAct enables hour-scale real-time human animation and supports 20 FPS real-time streaming inference on as few as two NVIDIA H100 or H200 GPUs. Quantitative results demonstrate that our method attains state-of-the-art performance in lip-sync accuracy, human animation quality, and emotional expressiveness, with the lowest inference cost.
SoulX-Singer: Towards High-Quality Zero-Shot Singing Voice Synthesis
Feb 08, 2026While recent years have witnessed rapid progress in speech synthesis, open-source singing voice synthesis (SVS) systems still face significant barriers to industrial deployment, particularly in terms of robustness and zero-shot generalization. In this report, we introduce SoulX-Singer, a high-quality open-source SVS system designed with practical deployment considerations in mind. SoulX-Singer supports controllable singing generation conditioned on either symbolic musical scores (MIDI) or melodic representations, enabling flexible and expressive control in real-world production workflows. Trained on more than 42,000 hours of vocal data, the system supports Mandarin Chinese, English, and Cantonese and consistently achieves state-of-the-art synthesis quality across languages under diverse musical conditions. Furthermore, to enable reliable evaluation of zero-shot SVS performance in practical scenarios, we construct SoulX-Singer-Eval, a dedicated benchmark with strict training-test disentanglement, facilitating systematic assessment in zero-shot settings.
SoulX-FlashTalk: Real-Time Infinite Streaming of Audio-Driven Avatars via Self-Correcting Bidirectional Distillation
Jan 06, 2026Deploying massive diffusion models for real-time, infinite-duration, audio-driven avatar generation presents a significant engineering challenge, primarily due to the conflict between computational load and strict latency constraints. Existing approaches often compromise visual fidelity by enforcing strictly unidirectional attention mechanisms or reducing model capacity. To address this problem, we introduce \textbf{SoulX-FlashTalk}, a 14B-parameter framework optimized for high-fidelity real-time streaming. Diverging from conventional unidirectional paradigms, we use a \textbf{Self-correcting Bidirectional Distillation} strategy that retains bidirectional attention within video chunks. This design preserves critical spatiotemporal correlations, significantly enhancing motion coherence and visual detail. To ensure stability during infinite generation, we incorporate a \textbf{Multi-step Retrospective Self-Correction Mechanism}, enabling the model to autonomously recover from accumulated errors and preventing collapse. Furthermore, we engineered a full-stack inference acceleration suite incorporating hybrid sequence parallelism, Parallel VAE, and kernel-level optimizations. Extensive evaluations confirm that SoulX-FlashTalk is the first 14B-scale system to achieve a \textbf{sub-second start-up latency (0.87s)} while reaching a real-time throughput of \textbf{32 FPS}, setting a new standard for high-fidelity interactive digital human synthesis.
SoulX-LiveTalk: Real-Time Infinite Streaming of Audio-Driven Avatars via Self-Correcting Bidirectional Distillation
Dec 31, 2025Deploying massive diffusion models for real-time, infinite-duration, audio-driven avatar generation presents a significant engineering challenge, primarily due to the conflict between computational load and strict latency constraints. Existing approaches often compromise visual fidelity by enforcing strictly unidirectional attention mechanisms or reducing model capacity. To address this problem, we introduce \textbf{SoulX-LiveTalk}, a 14B-parameter framework optimized for high-fidelity real-time streaming. Diverging from conventional unidirectional paradigms, we use a \textbf{Self-correcting Bidirectional Distillation} strategy that retains bidirectional attention within video chunks. This design preserves critical spatiotemporal correlations, significantly enhancing motion coherence and visual detail. To ensure stability during infinite generation, we incorporate a \textbf{Multi-step Retrospective Self-Correction Mechanism}, enabling the model to autonomously recover from accumulated errors and preventing collapse. Furthermore, we engineered a full-stack inference acceleration suite incorporating hybrid sequence parallelism, Parallel VAE, and kernel-level optimizations. Extensive evaluations confirm that SoulX-LiveTalk is the first 14B-scale system to achieve a \textbf{sub-second start-up latency (0.87s)} while reaching a real-time throughput of \textbf{32 FPS}, setting a new standard for high-fidelity interactive digital human synthesis.
Marrying Autoregressive Transformer and Diffusion with Multi-Reference Autoregression
Jun 11, 2025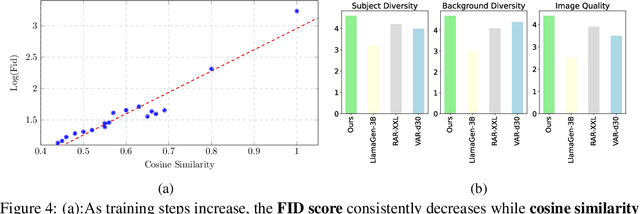

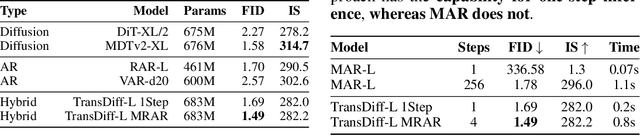
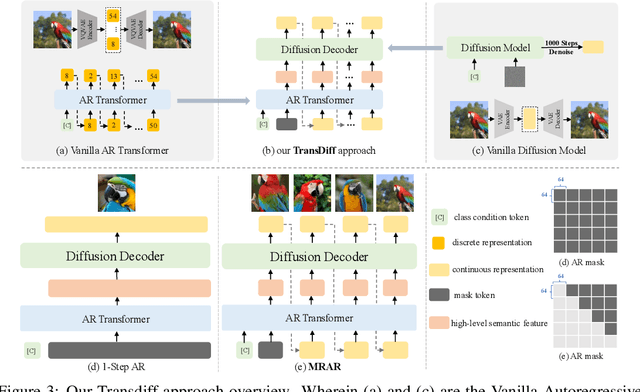
We introduce TransDiff, the first image generation model that marries Autoregressive (AR) Transformer with diffusion models. In this joint modeling framework, TransDiff encodes labels and images into high-level semantic features and employs a diffusion model to estimate the distribution of image samples. On the ImageNet 256x256 benchmark, TransDiff significantly outperforms other image generation models based on standalone AR Transformer or diffusion models. Specifically, TransDiff achieves a Fr\'echet Inception Distance (FID) of 1.61 and an Inception Score (IS) of 293.4, and further provides x2 faster inference latency compared to state-of-the-art methods based on AR Transformer and x112 faster inference compared to diffusion-only models. Furthermore, building on the TransDiff model, we introduce a novel image generation paradigm called Multi-Reference Autoregression (MRAR), which performs autoregressive generation by predicting the next image. MRAR enables the model to reference multiple previously generated images, thereby facilitating the learning of more diverse representations and improving the quality of generated images in subsequent iterations. By applying MRAR, the performance of TransDiff is improved, with the FID reduced from 1.61 to 1.42. We expect TransDiff to open up a new frontier in the field of image generation.
Replace in Translation: Boost Concept Alignment in Counterfactual Text-to-Image
May 20, 2025



Text-to-Image (T2I) has been prevalent in recent years, with most common condition tasks having been optimized nicely. Besides, counterfactual Text-to-Image is obstructing us from a more versatile AIGC experience. For those scenes that are impossible to happen in real world and anti-physics, we should spare no efforts in increasing the factual feel, which means synthesizing images that people think very likely to be happening, and concept alignment, which means all the required objects should be in the same frame. In this paper, we focus on concept alignment. As controllable T2I models have achieved satisfactory performance for real applications, we utilize this technology to replace the objects in a synthesized image in latent space step-by-step to change the image from a common scene to a counterfactual scene to meet the prompt. We propose a strategy to instruct this replacing process, which is called as Explicit Logical Narrative Prompt (ELNP), by using the newly SoTA language model DeepSeek to generate the instructions. Furthermore, to evaluate models' performance in counterfactual T2I, we design a metric to calculate how many required concepts in the prompt can be covered averagely in the synthesized images. The extensive experiments and qualitative comparisons demonstrate that our strategy can boost the concept alignment in counterfactual T2I.
Do We Need to Design Specific Diffusion Models for Different Tasks? Try ONE-PIC
Dec 07, 2024Large pretrained diffusion models have demonstrated impressive generation capabilities and have been adapted to various downstream tasks. However, unlike Large Language Models (LLMs) that can learn multiple tasks in a single model based on instructed data, diffusion models always require additional branches, task-specific training strategies, and losses for effective adaptation to different downstream tasks. This task-specific fine-tuning approach brings two drawbacks. 1) The task-specific additional networks create gaps between pretraining and fine-tuning which hinders the transfer of pretrained knowledge. 2) It necessitates careful additional network design, raising the barrier to learning and implementation, and making it less user-friendly. Thus, a question arises: Can we achieve a simple, efficient, and general approach to fine-tune diffusion models? To this end, we propose ONE-PIC. It enhances the inherited generative ability in the pretrained diffusion models without introducing additional modules. Specifically, we propose In-Visual-Context Tuning, which constructs task-specific training data by arranging source images and target images into a single image. This approach makes downstream fine-tuning closer to the pertaining, allowing our model to adapt more quickly to various downstream tasks. Moreover, we propose a Masking Strategy to unify different generative tasks. This strategy transforms various downstream fine-tuning tasks into predictions of the masked portions. The extensive experimental results demonstrate that our method is simple and efficient which streamlines the adaptation process and achieves excellent performance with lower costs. Code is available at https://github.com/tobran/ONE-PIC.