 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Emotion Recognition with Vision-language Prompting and Modality Dropout
Sep 11, 2024In this paper, we present our solution for the Second Multimodal Emotion Recognition Challenge Track 1(MER2024-SEMI). To enhance the accuracy and generalization performance of emotion recognition, we propose several methods for Multimodal Emotion Recognition. Firstly, we introduce EmoVCLIP, a model fine-tuned based on CLIP using vision-language prompt learning, designed for video-based emotion recognition tasks. By leveraging prompt learning on CLIP, EmoVCLIP improves the performance of pre-trained CLIP on emotional videos. Additionally, to address the issue of modality dependence in multimodal fusion, we employ modality dropout for robust information fusion. Furthermore, to aid Baichuan in better extracting emotional information, we suggest using GPT-4 as the prompt for Baichuan. Lastly, we utilize a self-training strategy to leverage unlabeled videos. In this process, we use unlabeled videos with high-confidence pseudo-labels generated by our model and incorporate them into the training set. Experimental results demonstrate that our model ranks 1st in the MER2024-SEMI track, achieving an accuracy of 90.15% on the test set.
Enriching Source Style Transfer in Recognition-Synthesis based Non-Parallel Voice Conversion
Jun 26, 2021
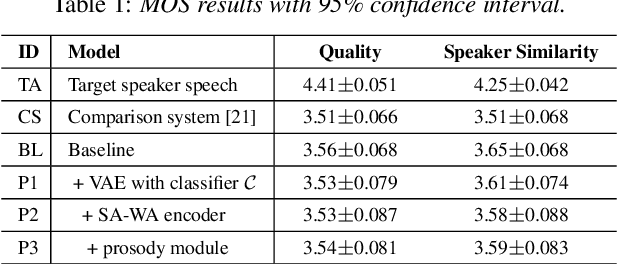
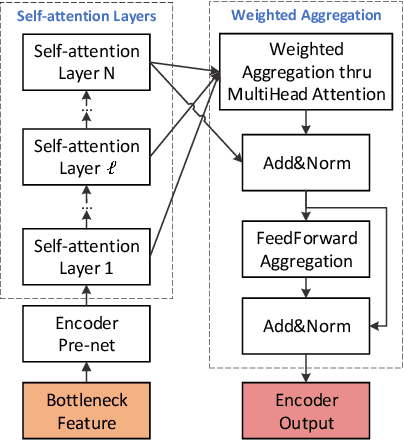
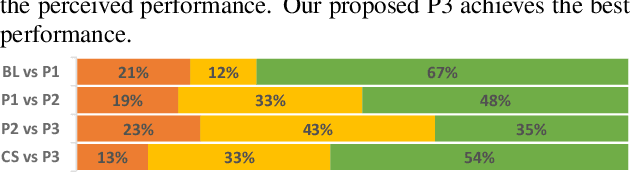
Current voice conversion (VC) methods can successfully convert timbre of the audio. As modeling source audio's prosody effectively is a challenging task, there are still limitations of transferring source style to the converted speech. This study proposes a source style transfer method based on recognition-synthesis framework. Previously in speech generation task, prosody can be modeled explicitly with prosodic features or implicitly with a latent prosody extractor. In this paper, taking advantages of both, we model the prosody in a hybrid manner, which effectively combines explicit and implicit methods in a proposed prosody module. Specifically, prosodic features are used to explicit model prosody, while VAE and reference encoder are used to implicitly model prosody, which take Mel spectrum and bottleneck feature as input respectively. Furthermore, adversarial training is introduced to remove speaker-related information from the VAE outputs, avoiding leaking source speaker information while transferring style. Finally, we use a modified self-attention based encoder to extract sentential context from bottleneck features, which also implicitly aggregates the prosodic aspects of source speech from the layered representations. Experiments show that our approach is superior to the baseline and a competitive system in terms of style transfer; meanwhile, the speech quality and speaker similarity are well maintained.
a novel cross-lingual voice cloning approach with a few text-free samples
Oct 30, 2019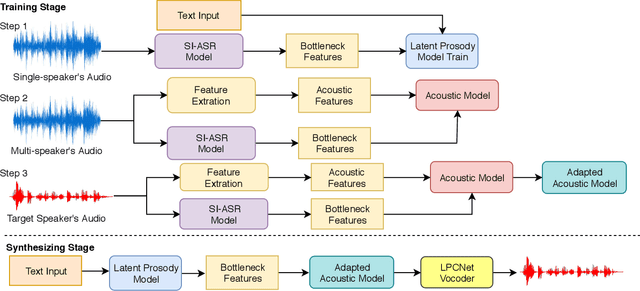
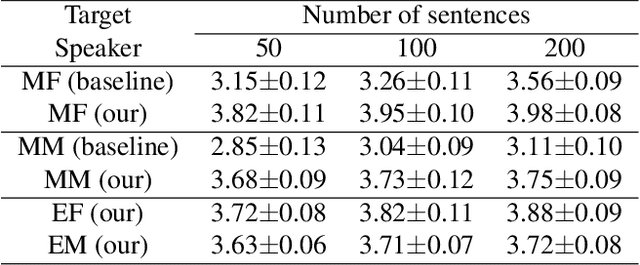
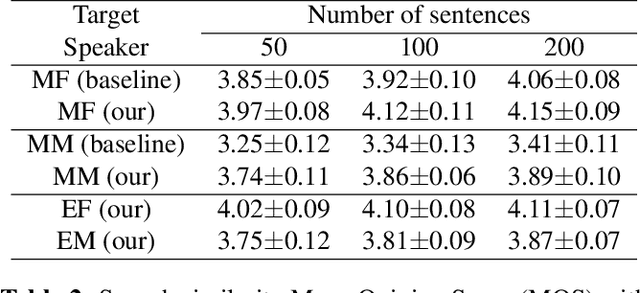
In this paper, we present a cross-lingual voice cloning approach. BN features obtained by SI-ASR model are used as a bridge across speakers and language boundaries. The relationships between text and BN features are modeled by the latent prosody model. The acoustic model learns the translation from BN features to acoustic features. The acoustic model is fine-tuned with a few samples of the target speaker to realize voice cloning. This system can generate speech of arbitrary utterance of target language in cross-lingual speakers' voice. We verify that with small amount of audio data, our proposed approach can well handle cross-lingual tasks. And in intra-lingual tasks, our proposed approach also performs better than baseline approach in naturalness and similarity.