 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVQ-CTAP: Cross-Modal Fine-Grained Sequence Representation Learning for Speech Processing
Aug 11, 2024Deep learning has brought significant improvements to the field of cross-modal representation learning. For tasks such as text-to-speech (TTS), voice conversion (VC), and automatic speech recognition (ASR), a cross-modal fine-grained (frame-level) sequence representation is desired, emphasizing the semantic content of the text modality while de-emphasizing the paralinguistic information of the speech modality. We propose a method called "Vector Quantized Contrastive Token-Acoustic Pre-training (VQ-CTAP)", which uses the cross-modal aligned sequence transcoder to bring text and speech into a joint multimodal space, learning how to connect text and speech at the frame level. The proposed VQ-CTAP is a paradigm for cross-modal sequence representation learning, offering a promising solution for fine-grained generation and recognition tasks in speech processing. The VQ-CTAP can be directly applied to VC and ASR tasks without fine-tuning or additional structures. We propose a sequence-aware semantic connector, which connects multiple frozen pre-trained modules for the TTS task, exhibiting a plug-and-play capability. We design a stepping optimization strategy to ensure effective model convergence by gradually injecting and adjusting the influence of various loss components. Furthermore, we propose a semantic-transfer-wise paralinguistic consistency loss to enhance representational capabilities, allowing the model to better generalize to unseen data and capture the nuances of paralinguistic information. In addition, VQ-CTAP achieves high-compression speech coding at a rate of 25Hz from 24kHz input waveforms, which is a 960-fold reduction in the sampling rate. The audio demo is available at https://qiangchunyu.github.io/VQCTAP/
Improving Prosody for Cross-Speaker Style Transfer by Semi-Supervised Style Extractor and Hierarchical Modeling in Speech Synthesis
Mar 14, 2023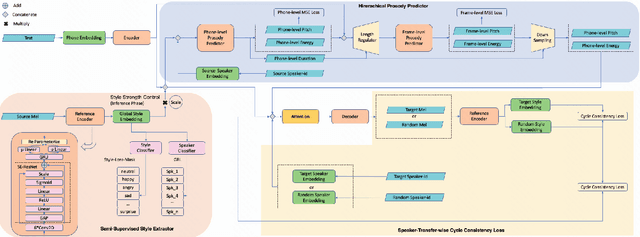
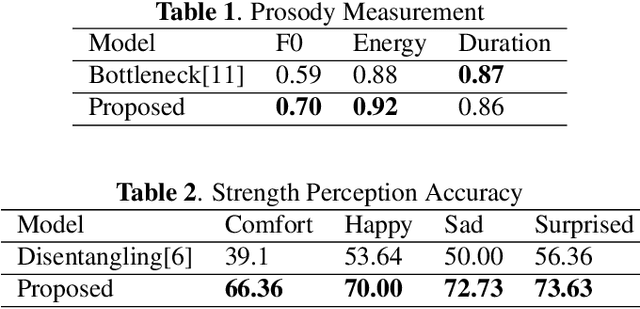
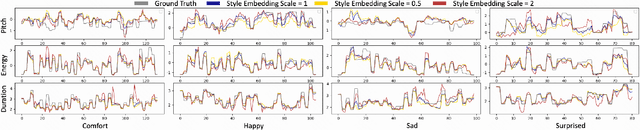
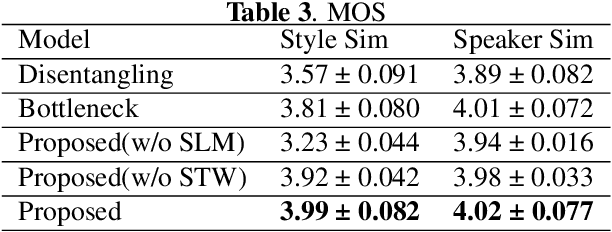
Cross-speaker style transfer in speech synthesis aims at transferring a style from source speaker to synthesized speech of a target speaker's timbre. In most previous methods, the synthesized fine-grained prosody features often represent the source speaker's average style, similar to the one-to-many problem(i.e., multiple prosody variations correspond to the same text). In response to this problem, a strength-controlled semi-supervised style extractor is proposed to disentangle the style from content and timbre, improving the representation and interpretability of the global style embedding, which can alleviate the one-to-many mapping and data imbalance problems in prosody prediction. A hierarchical prosody predictor is proposed to improve prosody modeling. We find that better style transfer can be achieved by using the source speaker's prosody features that are easily predicted. Additionally, a speaker-transfer-wise cycle consistency loss is proposed to assist the model in learning unseen style-timbre combinations during the training phase. Experimental results show that the method outperforms the baseline. We provide a website with audio samples.
Style-Label-Free: Cross-Speaker Style Transfer by Quantized VAE and Speaker-wise Normalization in Speech Synthesis
Dec 13, 2022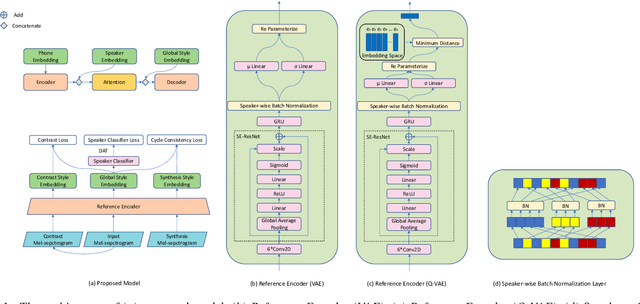

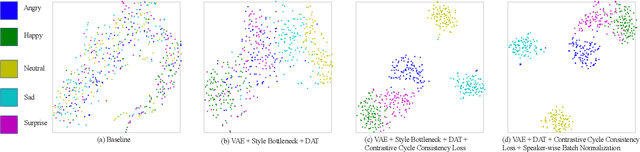
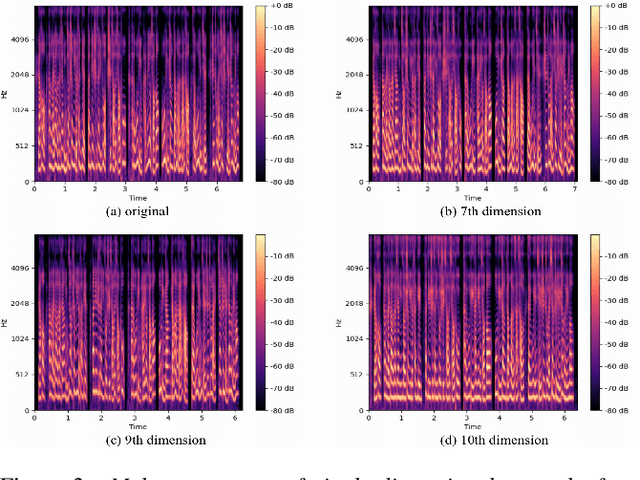
Cross-speaker style transfer in speech synthesis aims at transferring a style from source speaker to synthesised speech of a target speaker's timbre. Most previous approaches rely on data with style labels, but manually-annotated labels are expensive and not always reliable. In response to this problem, we propose Style-Label-Free, a cross-speaker style transfer method, which can realize the style transfer from source speaker to target speaker without style labels. Firstly, a reference encoder structure based on quantized variational autoencoder (Q-VAE) and style bottleneck is designed to extract discrete style representations. Secondly, a speaker-wise batch normalization layer is proposed to reduce the source speaker leakage. In order to improve the style extraction ability of the reference encoder, a style invariant and contrastive data augmentation method is proposed. Experimental results show that the method outperforms the baseline. We provide a website with audio samples.
Back-Translation-Style Data Augmentation for Mandarin Chinese Polyphone Disambiguation
Nov 17, 2022Conversion of Chinese Grapheme-to-Phoneme (G2P) plays an important role in Mandarin Chinese Text-To-Speech (TTS) systems, where one of the biggest challenges is the task of polyphone disambiguation. Most of the previous polyphone disambiguation models are trained on manually annotated datasets, and publicly available datasets for polyphone disambiguation are scarce. In this paper we propose a simple back-translation-style data augmentation method for mandarin Chinese polyphone disambiguation, utilizing a large amount of unlabeled text data. Inspired by the back-translation technique proposed in the field of machine translation, we build a Grapheme-to-Phoneme (G2P) model to predict the pronunciation of polyphonic character, and a Phoneme-to-Grapheme (P2G) model to predict pronunciation into text. Meanwhile, a window-based matching strategy and a multi-model scoring strategy are proposed to judge the correctness of the pseudo-label. We design a data balance strategy to improve the accuracy of some typical polyphonic characters in the training set with imbalanced distribution or data scarcity. The experimental result shows the effectiveness of the proposed back-translation-style data augmentation method.
Multi-layered Semantic Representation Network for Multi-label Image Classification
Jun 22, 2021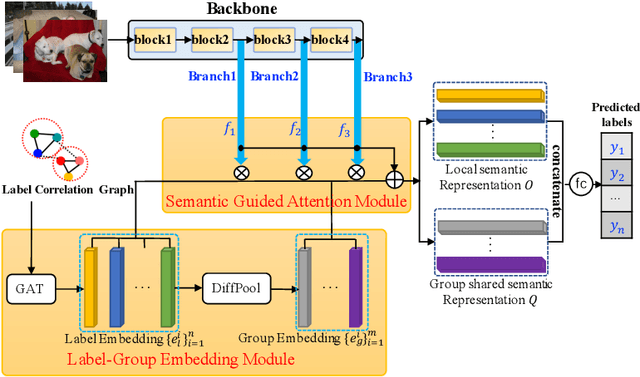
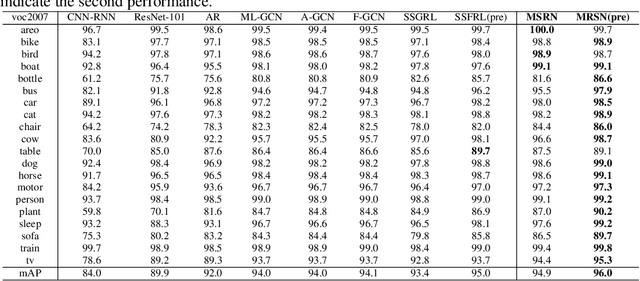
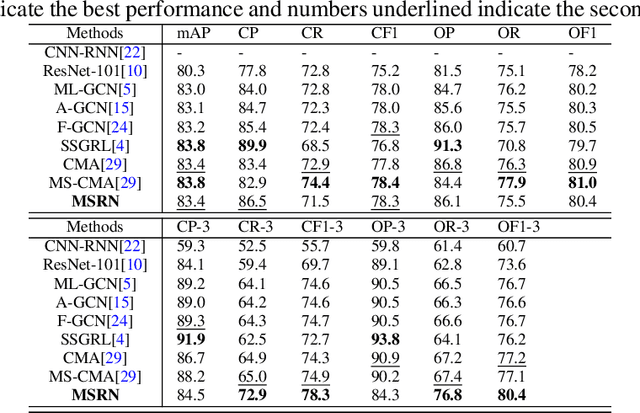
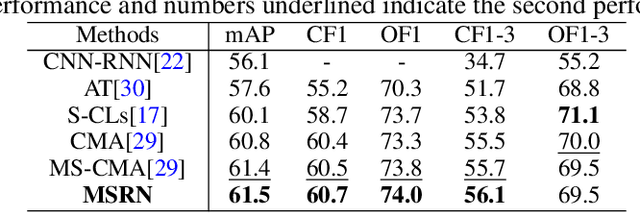
Multi-label image classification (MLIC) is a fundamental and practical task, which aims to assign multiple possible labels to an image. In recent years, many deep convolutional neural network (CNN) based approaches have been proposed which model label correlations to discover semantics of labels and learn semantic representations of images. This paper advances this research direction by improving both the modeling of label correlations and the learning of semantic representations. On the one hand, besides the local semantics of each label, we propose to further explore global semantics shared by multiple labels. On the other hand, existing approaches mainly learn the semantic representations at the last convolutional layer of a CNN. But it has been noted that the image representations of different layers of CNN capture different levels or scales of features and have different discriminative abilities. We thus propose to learn semantic representations at multiple convolutional layers. To this end, this paper designs a Multi-layered Semantic Representation Network (MSRN) which discovers both local and global semantics of labels through modeling label correlations and utilizes the label semantics to guide the semantic representations learning at multiple layers through an attention mechanism. Extensive experiments on four benchmark datasets including VOC 2007, COCO, NUS-WIDE, and Apparel show a competitive performance of the proposed MSRN against state-of-the-art models.
a novel cross-lingual voice cloning approach with a few text-free samples
Oct 30, 2019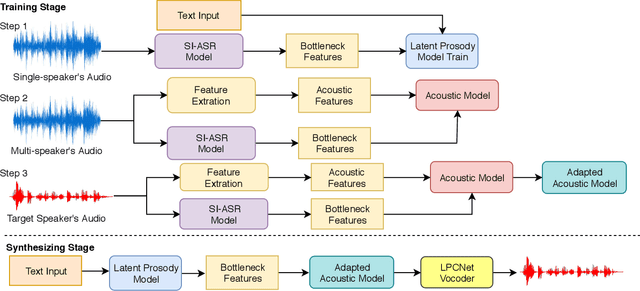
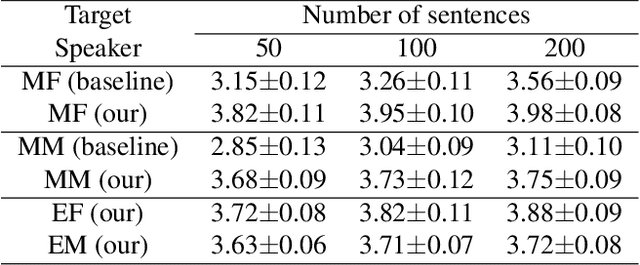
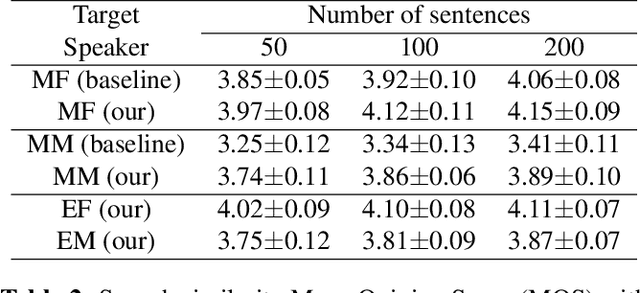
In this paper, we present a cross-lingual voice cloning approach. BN features obtained by SI-ASR model are used as a bridge across speakers and language boundaries. The relationships between text and BN features are modeled by the latent prosody model. The acoustic model learns the translation from BN features to acoustic features. The acoustic model is fine-tuned with a few samples of the target speaker to realize voice cloning. This system can generate speech of arbitrary utterance of target language in cross-lingual speakers' voice. We verify that with small amount of audio data, our proposed approach can well handle cross-lingual tasks. And in intra-lingual tasks, our proposed approach also performs better than baseline approach in naturalness and similarity.