 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStyle-Label-Free: Cross-Speaker Style Transfer by Quantized VAE and Speaker-wise Normalization in Speech Synthesis
Paper and Code
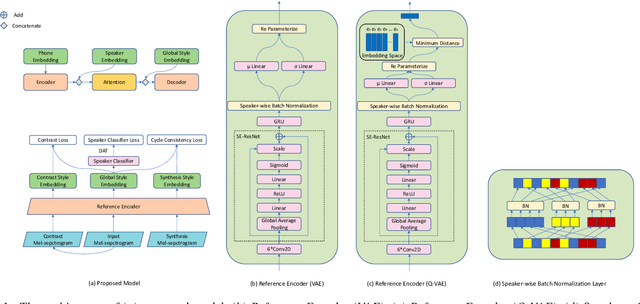

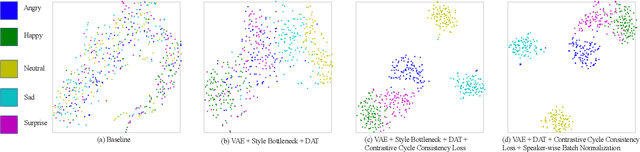
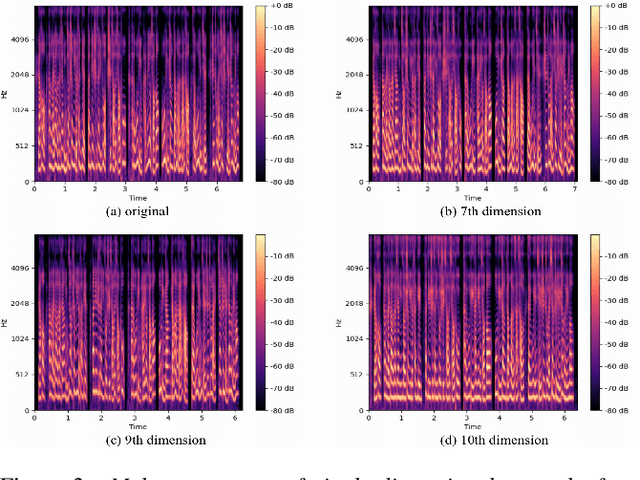
Cross-speaker style transfer in speech synthesis aims at transferring a style from source speaker to synthesised speech of a target speaker's timbre. Most previous approaches rely on data with style labels, but manually-annotated labels are expensive and not always reliable. In response to this problem, we propose Style-Label-Free, a cross-speaker style transfer method, which can realize the style transfer from source speaker to target speaker without style labels. Firstly, a reference encoder structure based on quantized variational autoencoder (Q-VAE) and style bottleneck is designed to extract discrete style representations. Secondly, a speaker-wise batch normalization layer is proposed to reduce the source speaker leakage. In order to improve the style extraction ability of the reference encoder, a style invariant and contrastive data augmentation method is proposed. Experimental results show that the method outperforms the baseline. We provide a website with audio samples.