 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating the Expressive Appropriateness of Speech in Rich Contexts
May 10, 2026Evaluating expressive speech remains challenging, as existing methods mainly assess emotional intensity and overlook whether a speech sample is expressively appropriate for its contextual setting. This limitation hinders reliable evaluation of speech systems used in narrative-driven and interactive applications, such as audiobooks and conversational agents. We introduce CEAEval, a Context-rich framework for Evaluating Expressive Appropriateness in speech, which assesses whether a speech sample expressively aligns with the underlying communicative intent implied by its discourse-level narrative context. To support this task, we construct CEAEval-D, the first context-rich speech dataset with real human performances in Mandarin conversational speech, providing narrative descriptions together with fifteen dimensions of human annotations covering expressive attributes and expressive appropriateness. We further develop CEAEval-M, a model that integrates knowledge distillation, planner-based multi-model collaboration, adaptive audio attention bias, and reinforcement learning to perform context-rich expressive appropriateness evaluation. Experiments on a human-annotated test set demonstrate that CEAEval-M substantially outperforms existing speech evaluation and analysis systems.
UniSonate: A Unified Model for Speech, Music, and Sound Effect Generation with Text Instructions
Apr 24, 2026Generative audio modeling has largely been fragmented into specialized tasks, text-to-speech (TTS), text-to-music (TTM), and text-to-audio (TTA), each operating under heterogeneous control paradigms. Unifying these modalities remains a fundamental challenge due to the intrinsic dissonance between structured semantic representations (speech/music) and unstructured acoustic textures (sound effects). In this paper, we introduce UniSonate, a unified flow-matching framework capable of synthesizing speech, music, and sound effects through a standardized, reference-free natural language instruction interface. To reconcile structural disparities, we propose a novel dynamic token injection mechanism that projects unstructured environmental sounds into a structured temporal latent space, enabling precise duration control within a phoneme-driven Multimodal Diffusion Transformer (MM-DiT). Coupled with a multi-stage curriculum learning strategy, this approach effectively mitigates cross-modal optimization conflicts. Extensive experiments demonstrate that UniSonate achieves state-of-the-art performance in instruction-based TTS (WER 1.47%) and TTM (SongEval Coherence 3.18), while maintaining competitive fidelity in TTA. Crucially, we observe positive transfer, where joint training on diverse audio data significantly enhances structural coherence and prosodic expressiveness compared to single-task baselines. Audio samples are available at https://qiangchunyu.github.io/UniSonate/.
CoVe: Training Interactive Tool-Use Agents via Constraint-Guided Verification
Mar 02, 2026Developing multi-turn interactive tool-use agents is challenging because real-world user needs are often complex and ambiguous, yet agents must execute deterministic actions to satisfy them. To address this gap, we introduce \textbf{CoVe} (\textbf{Co}nstraint-\textbf{Ve}rification), a post-training data synthesis framework designed for training interactive tool-use agents while ensuring both data complexity and correctness. CoVe begins by defining explicit task constraints, which serve a dual role: they guide the generation of complex trajectories and act as deterministic verifiers for assessing trajectory quality. This enables the creation of high-quality training trajectories for supervised fine-tuning (SFT) and the derivation of accurate reward signals for reinforcement learning (RL). Our evaluation on the challenging $τ^2$-bench benchmark demonstrates the effectiveness of the framework. Notably, our compact \textbf{CoVe-4B} model achieves success rates of 43.0\% and 59.4\% in the Airline and Retail domains, respectively; its overall performance significantly outperforms strong baselines of similar scale and remains competitive with models up to $17\times$ its size. These results indicate that CoVe provides an effective and efficient pathway for synthesizing training data for state-of-the-art interactive tool-use agents. To support future research, we open-source our code, trained model, and the full set of 12K high-quality trajectories used for training.
High-Fidelity Generative Audio Compression at 0.275kbps
Jan 31, 2026High-fidelity general audio compression at ultra-low bitrates is crucial for applications ranging from low-bandwidth communication to generative audio-language modeling. Traditional audio compression methods and contemporary neural codecs are fundamentally designed for waveform reconstruction. As a result, when operating at ultra-low bitrates, these methods degrade rapidly and often fail to preserve essential information, leading to severe acoustic artifacts and pronounced semantic distortion. To overcome these limitations, we introduce Generative Audio Compression (GAC), a novel paradigm shift from signal fidelity to task-oriented effectiveness. Implemented within the AI Flow framework, GAC is theoretically grounded in the Law of Information Capacity. These foundations posit that abundant computational power can be leveraged at the receiver to offset extreme communication bottlenecks--exemplifying the More Computation, Less Bandwidth philosophy. By integrating semantic understanding at the transmitter with scalable generative synthesis at the receiver, GAC offloads the information burden to powerful model priors. Our 1.8B-parameter model achieves high-fidelity reconstruction of 32kHz general audio at an unprecedented bitrate of 0.275kbps. Even at 0.175kbps, it still preserves a strong intelligible audio transmission capability, which represents an about 3000x compression ratio, significantly outperforming current state-of-the-art neural codecs in maintaining both perceptual quality and semantic consistency.
Rare Word Recognition and Translation Without Fine-Tuning via Task Vector in Speech Models
Dec 26, 2025Rare words remain a critical bottleneck for speech-to-text systems. While direct fine-tuning improves recognition of target words, it often incurs high cost, catastrophic forgetting, and limited scalability. To address these challenges, we propose a training-free paradigm based on task vectors for rare word recognition and translation. By defining task vectors as parameter differences and introducing word-level task vector arithmetic, our approach enables flexible composition of rare-word capabilities, greatly enhancing scalability and reusability. Extensive experiments across multiple domains show that the proposed method matches or surpasses fine-tuned models on target words, improves general performance by about 5 BLEU, and mitigates catastrophic forgetting.
Efficient Reasoning via Reward Model
Nov 12, 2025Reinforcement learning with verifiable rewards (RLVR) has been shown to enhance the reasoning capabilities of large language models (LLMs), enabling the development of large reasoning models (LRMs). However, LRMs such as DeepSeek-R1 and OpenAI o1 often generate verbose responses containing redundant or irrelevant reasoning step-a phenomenon known as overthinking-which substantially increases computational costs. Prior efforts to mitigate this issue commonly incorporate length penalties into the reward function, but we find they frequently suffer from two critical issues: length collapse and training collapse, resulting in sub-optimal performance. To address them, we propose a pipeline for training a Conciseness Reward Model (CRM) that scores the conciseness of reasoning path. Additionally, we introduce a novel reward formulation named Conciseness Reward Function (CRF) with explicit dependency between the outcome reward and conciseness score, thereby fostering both more effective and more efficient reasoning. From a theoretical standpoint, we demonstrate the superiority of the new reward from the perspective of variance reduction and improved convergence properties. Besides, on the practical side, extensive experiments on five mathematical benchmark datasets demonstrate the method's effectiveness and token efficiency, which achieves an 8.1% accuracy improvement and a 19.9% reduction in response token length on Qwen2.5-7B. Furthermore, the method generalizes well to other LLMs including Llama and Mistral. The implementation code and datasets are publicly available for reproduction: https://anonymous.4open.science/r/CRM.
Complementary Learning System Empowers Online Continual Learning of Vehicle Motion Forecasting in Smart Cities
Aug 27, 2025



Artificial intelligence underpins most smart city services, yet deep neural network (DNN) that forecasts vehicle motion still struggle with catastrophic forgetting, the loss of earlier knowledge when models are updated. Conventional fixes enlarge the training set or replay past data, but these strategies incur high data collection costs, sample inefficiently and fail to balance long- and short-term experience, leaving them short of human-like continual learning. Here we introduce Dual-LS, a task-free, online continual learning paradigm for DNN-based motion forecasting that is inspired by the complementary learning system of the human brain. Dual-LS pairs two synergistic memory rehearsal replay mechanisms to accelerate experience retrieval while dynamically coordinating long-term and short-term knowledge representations. Tests on naturalistic data spanning three countries, over 772,000 vehicles and cumulative testing mileage of 11,187 km show that Dual-LS mitigates catastrophic forgetting by up to 74.31\% and reduces computational resource demand by up to 94.02\%, markedly boosting predictive stability in vehicle motion forecasting without inflating data requirements. Meanwhile, it endows DNN-based vehicle motion forecasting with computation efficient and human-like continual learning adaptability fit for smart cities.
ASVspoof 5: Design, Collection and Validation of Resources for Spoofing, Deepfake, and Adversarial Attack Detection Using Crowdsourced Speech
Feb 13, 2025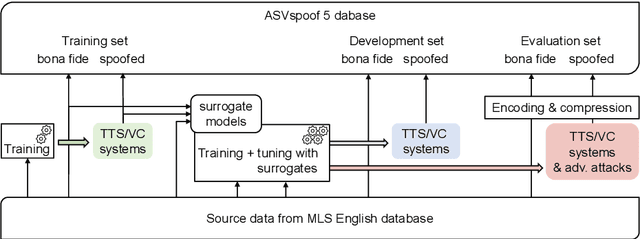

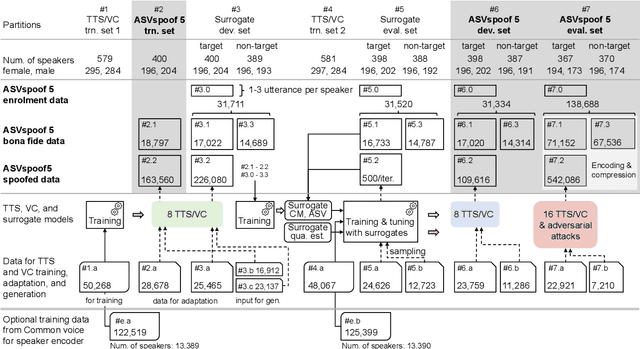
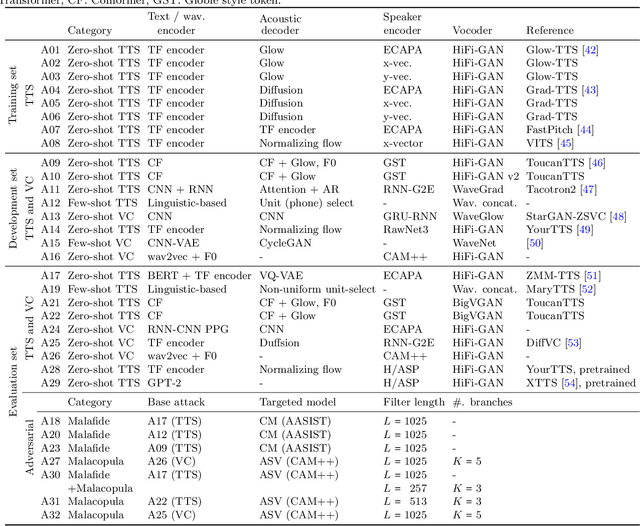
ASVspoof 5 is the fifth edition in a series of challenges which promote the study of speech spoofing and deepfake attacks as well as the design of detection solutions. We introduce the ASVspoof 5 database which is generated in crowdsourced fashion from data collected in diverse acoustic conditions (cf. studio-quality data for earlier ASVspoof databases) and from ~2,000 speakers (cf. ~100 earlier). The database contains attacks generated with 32 different algorithms, also crowdsourced, and optimised to varying degrees using new surrogate detection models. Among them are attacks generated with a mix of legacy and contemporary text-to-speech synthesis and voice conversion models, in addition to adversarial attacks which are incorporated for the first time. ASVspoof 5 protocols comprise seven speaker-disjoint partitions. They include two distinct partitions for the training of different sets of attack models, two more for the development and evaluation of surrogate detection models, and then three additional partitions which comprise the ASVspoof 5 training, development and evaluation sets. An auxiliary set of data collected from an additional 30k speakers can also be used to train speaker encoders for the implementation of attack algorithms. Also described herein is an experimental validation of the new ASVspoof 5 database using a set of automatic speaker verification and spoof/deepfake baseline detectors. With the exception of protocols and tools for the generation of spoofed/deepfake speech, the resources described in this paper, already used by participants of the ASVspoof 5 challenge in 2024, are now all freely available to the community.
Characteristic-Specific Partial Fine-Tuning for Efficient Emotion and Speaker Adaptation in Codec Language Text-to-Speech Models
Jan 24, 2025



Recently, emotional speech generation and speaker cloning have garnered significant interest in text-to-speech (TTS). With the open-sourcing of codec language TTS models trained on massive datasets with large-scale parameters, adapting these general pre-trained TTS models to generate speech with specific emotional expressions and target speaker characteristics has become a topic of great attention. Common approaches, such as full and adapter-based fine-tuning, often overlook the specific contributions of model parameters to emotion and speaker control. Treating all parameters uniformly during fine-tuning, especially when the target data has limited content diversity compared to the pre-training corpus, results in slow training speed and an increased risk of catastrophic forgetting. To address these challenges, we propose a characteristic-specific partial fine-tuning strategy, short as CSP-FT. First, we use a weighted-sum approach to analyze the contributions of different Transformer layers in a pre-trained codec language TTS model for emotion and speaker control in the generated speech. We then selectively fine-tune the layers with the highest and lowest characteristic-specific contributions to generate speech with target emotional expression and speaker identity. Experimental results demonstrate that our method achieves performance comparable to, or even surpassing, full fine-tuning in generating speech with specific emotional expressions and speaker identities. Additionally, CSP-FT delivers approximately 2x faster training speeds, fine-tunes only around 8% of parameters, and significantly reduces catastrophic forgetting. Furthermore, we show that codec language TTS models perform competitively with self-supervised models in speaker identification and emotion classification tasks, offering valuable insights for developing universal speech processing models.
MOS-Attack: A Scalable Multi-objective Adversarial Attack Framework
Jan 13, 2025Crafting adversarial examples is crucial for evaluating and enhancing the robustness of Deep Neural Networks (DNNs), presenting a challenge equivalent to maximizing a non-differentiable 0-1 loss function. However, existing single objective methods, namely adversarial attacks focus on a surrogate loss function, do not fully harness the benefits of engaging multiple loss functions, as a result of insufficient understanding of their synergistic and conflicting nature. To overcome these limitations, we propose the Multi-Objective Set-based Attack (MOS Attack), a novel adversarial attack framework leveraging multiple loss functions and automatically uncovering their interrelations. The MOS Attack adopts a set-based multi-objective optimization strategy, enabling the incorporation of numerous loss functions without additional parameters. It also automatically mines synergistic patterns among various losses, facilitating the generation of potent adversarial attacks with fewer objectives. Extensive experiments have shown that our MOS Attack outperforms single-objective attacks. Furthermore, by harnessing the identified synergistic patterns, MOS Attack continues to show superior results with a reduced number of loss functions.