 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Pareto Set for Multi-Objective Continuous Robot Control
Jun 27, 2024



For a control problem with multiple conflicting objectives, there exists a set of Pareto-optimal policies called the Pareto set instead of a single optimal policy. When a multi-objective control problem is continuous and complex, traditional multi-objective reinforcement learning (MORL) algorithms search for many Pareto-optimal deep policies to approximate the Pareto set, which is quite resource-consuming. In this paper, we propose a simple and resource-efficient MORL algorithm that learns a continuous representation of the Pareto set in a high-dimensional policy parameter space using a single hypernet. The learned hypernet can directly generate various well-trained policy networks for different user preferences. We compare our method with two state-of-the-art MORL algorithms on seven multi-objective continuous robot control problems. Experimental results show that our method achieves the best overall performance with the least training parameters. An interesting observation is that the Pareto set is well approximated by a curved line or surface in a high-dimensional parameter space. This observation will provide insight for researchers to design new MORL algorithms.
State Space Closure: Revisiting Endless Online Level Generation via Reinforcement Learning
Dec 06, 2022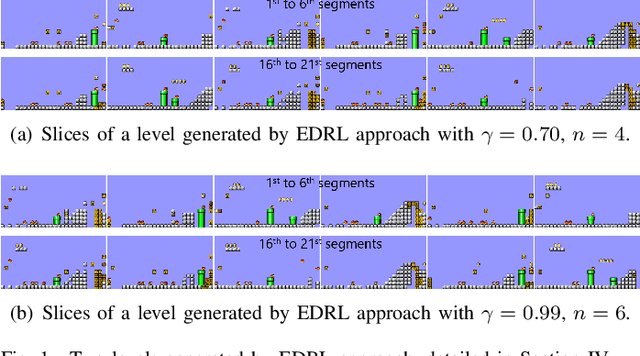
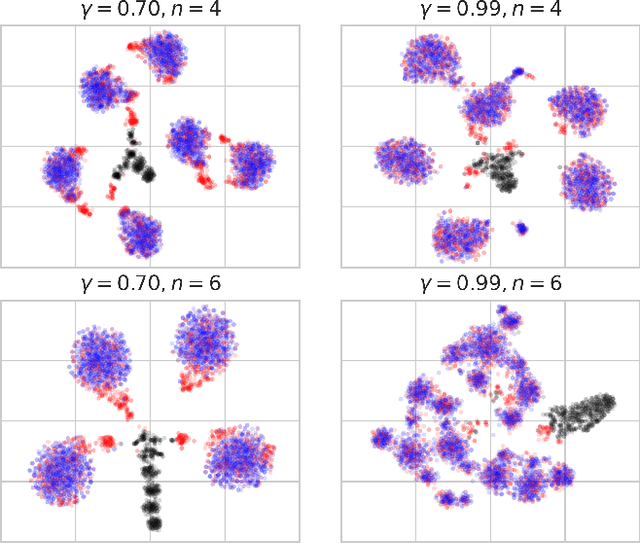
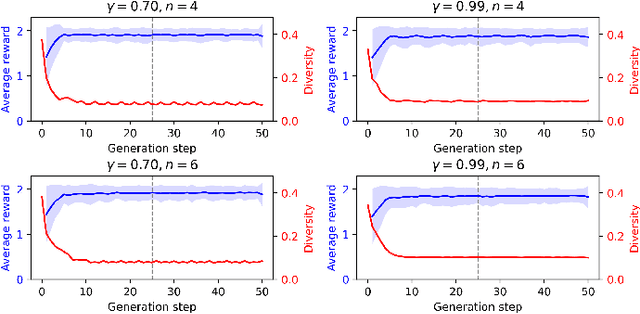
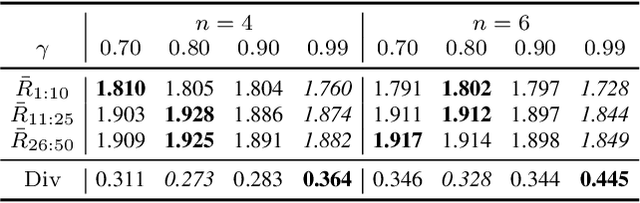
In this paper we revisit endless online level generation with the recently proposed experience-driven procedural content generation via reinforcement learning (EDRL) framework, from an observation that EDRL tends to generate recurrent patterns. Inspired by this phenomenon, we formulate a notion of state space closure, which means that any state that may appear in an infinite-horizon online generation process can be found in a finite horizon. Through theoretical analysis we find that though state space closure arises a concern about diversity, it makes the EDRL trained on a finite-horizon generalised to the infinite-horizon scenario without deterioration of content quality. Moreover, we verify the quality and diversity of contents generated by EDRL via empirical studies on the widely used Super Mario Bros. benchmark. Experimental results reveal that the current EDRL approach's ability of generating diverse game levels is limited due to the state space closure, whereas it does not suffer from reward deterioration given a horizon longer than the one of training. Concluding our findings and analysis, we argue that future works in generating online diverse and high-quality contents via EDRL should address the issue of diversity on the premise of state space closure which ensures the quality.
Effects of Archive Size on Computation Time and Solution Quality for Multi-Objective Optimization
Sep 07, 2022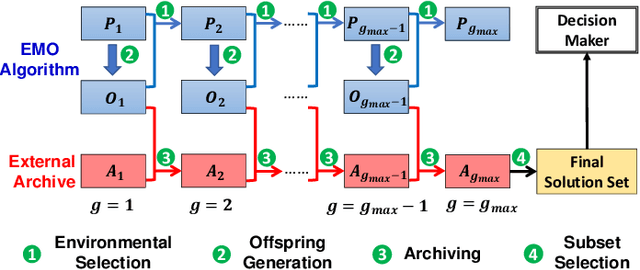
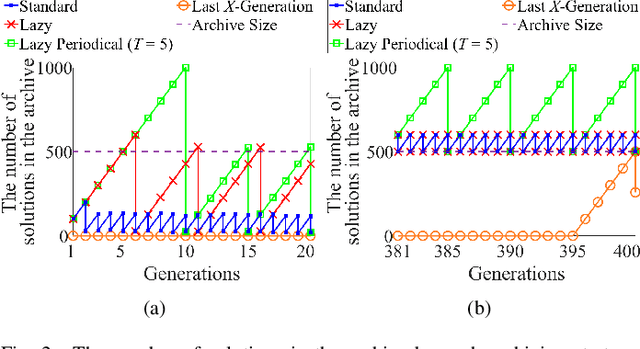
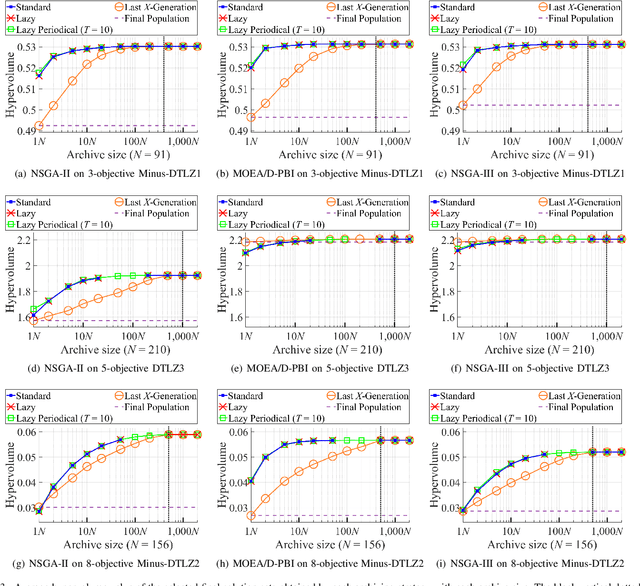
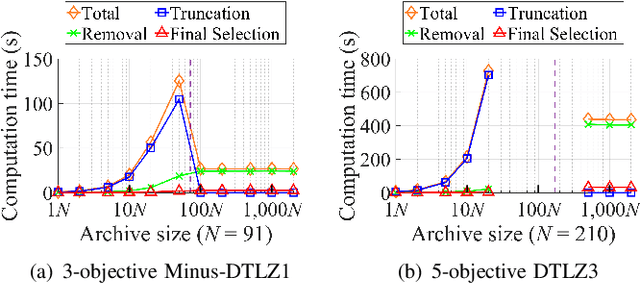
An unbounded external archive has been used to store all nondominated solutions found by an evolutionary multi-objective optimization algorithm in some studies. It has been shown that a selected solution subset from the stored solutions is often better than the final population. However, the use of the unbounded archive is not always realistic. When the number of examined solutions is huge, we must pre-specify the archive size. In this study, we examine the effects of the archive size on three aspects: (i) the quality of the selected final solution set, (ii) the total computation time for the archive maintenance and the final solution set selection, and (iii) the required memory size. Unsurprisingly, the increase of the archive size improves the final solution set quality. Interestingly, the total computation time of a medium-size archive is much larger than that of a small-size archive and a huge-size archive (e.g., an unbounded archive). To decrease the computation time, we examine two ideas: periodical archive update and archiving only in later generations. Compared with updating the archive at every generation, the first idea can obtain almost the same final solution set quality using a much shorter computation time at the cost of a slight increase of the memory size. The second idea drastically decreases the computation time at the cost of a slight deterioration of the final solution set quality. Based on our experimental results, some suggestions are given about how to appropriately choose an archiving strategy and an archive size.
Learning to Approximate: Auto Direction Vector Set Generation for Hypervolume Contribution Approximation
Jan 18, 2022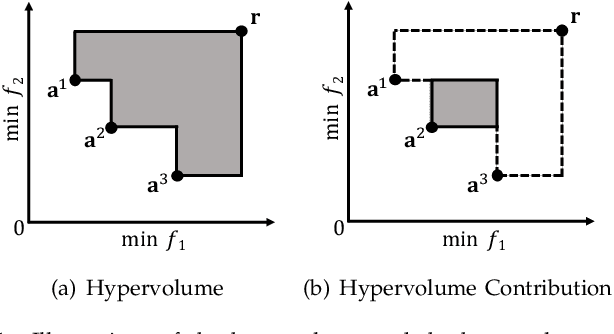

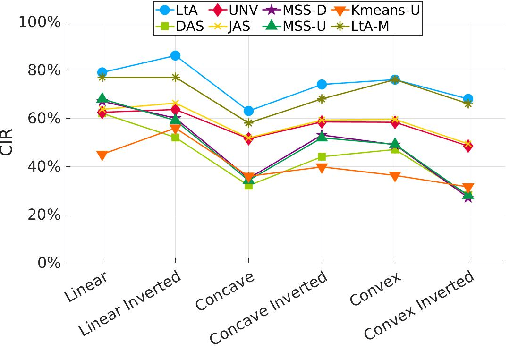
Hypervolume contribution is an important concept in evolutionary multi-objective optimization (EMO). It involves in hypervolume-based EMO algorithms and hypervolume subset selection algorithms. Its main drawback is that it is computationally expensive in high-dimensional spaces, which limits its applicability to many-objective optimization. Recently, an R2 indicator variant (i.e., $R_2^{\text{HVC}}$ indicator) is proposed to approximate the hypervolume contribution. The $R_2^{\text{HVC}}$ indicator uses line segments along a number of direction vectors for hypervolume contribution approximation. It has been shown that different direction vector sets lead to different approximation quality. In this paper, we propose \textit{Learning to Approximate (LtA)}, a direction vector set generation method for the $R_2^{\text{HVC}}$ indicator. The direction vector set is automatically learned from training data. The learned direction vector set can then be used in the $R_2^{\text{HVC}}$ indicator to improve its approximation quality. The usefulness of the proposed LtA method is examined by comparing it with other commonly-used direction vector set generation methods for the $R_2^{\text{HVC}}$ indicator. Experimental results suggest the superiority of LtA over the other methods for generating high quality direction vector sets.
Benchmarking Subset Selection from Large Candidate Solution Sets in Evolutionary Multi-objective Optimization
Jan 18, 2022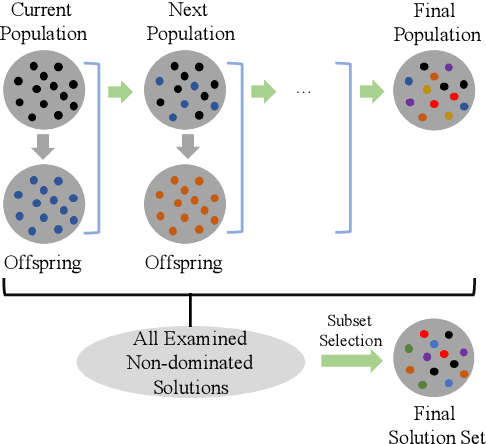
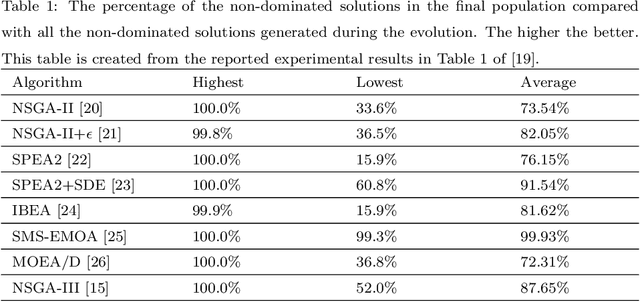

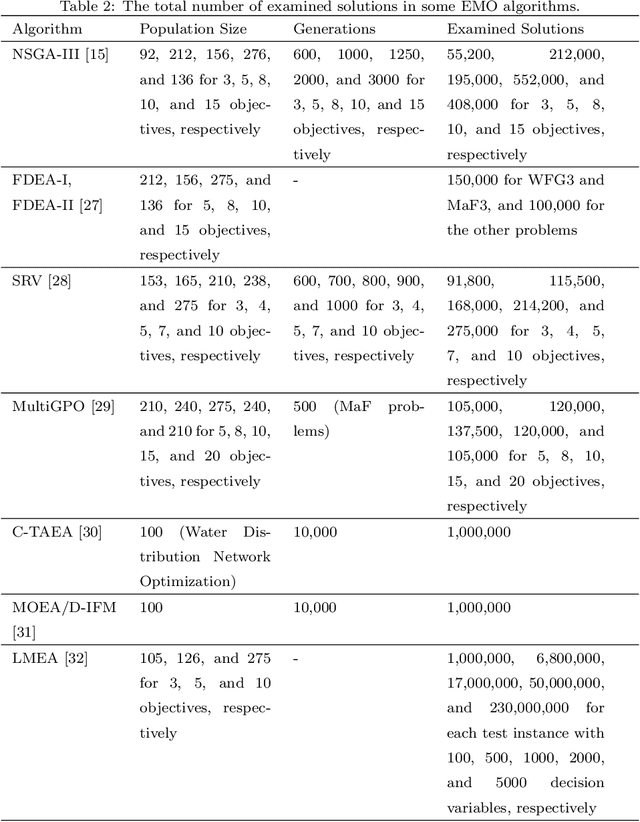
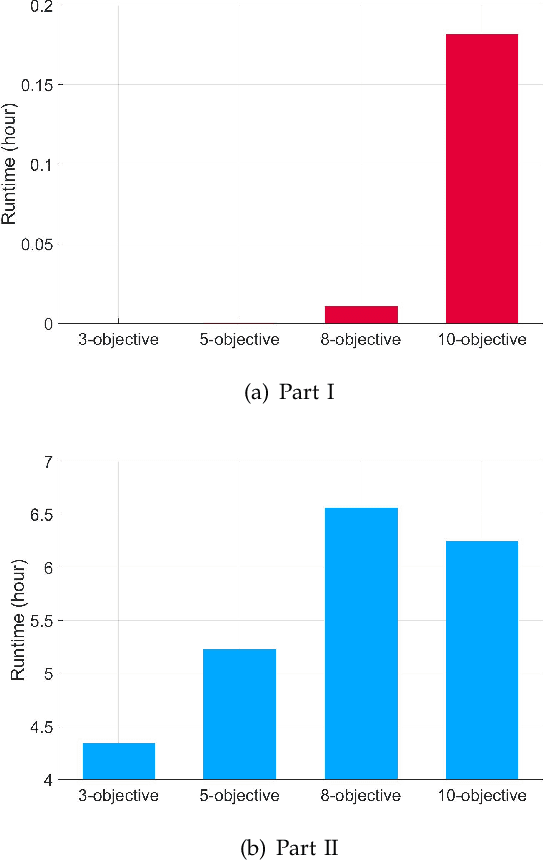
In the evolutionary multi-objective optimization (EMO) field, the standard practice is to present the final population of an EMO algorithm as the output. However, it has been shown that the final population often includes solutions which are dominated by other solutions generated and discarded in previous generations. Recently, a new EMO framework has been proposed to solve this issue by storing all the non-dominated solutions generated during the evolution in an archive and selecting a subset of solutions from the archive as the output. The key component in this framework is the subset selection from the archive which usually stores a large number of candidate solutions. However, most studies on subset selection focus on small candidate solution sets for environmental selection. There is no benchmark test suite for large-scale subset selection. This paper aims to fill this research gap by proposing a benchmark test suite for subset selection from large candidate solution sets, and comparing some representative methods using the proposed test suite. The proposed test suite together with the benchmarking studies provides a baseline for researchers to understand, use, compare, and develop subset selection methods in the EMO field.
Experience-Driven PCG via Reinforcement Learning: A Super Mario Bros Study
Jul 05, 2021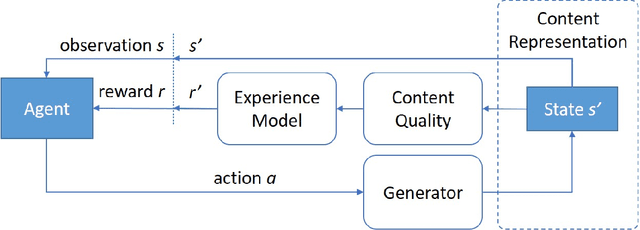
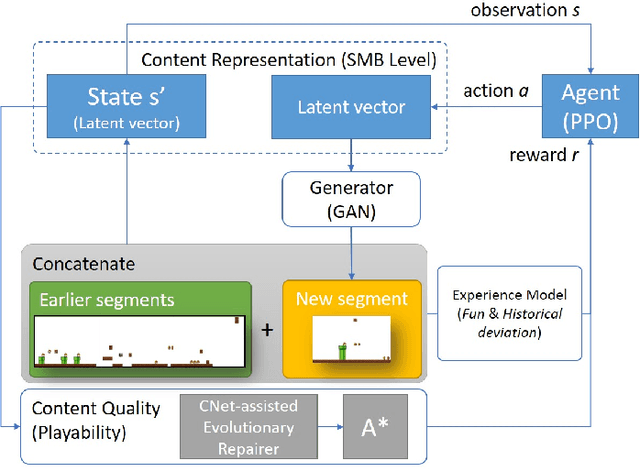
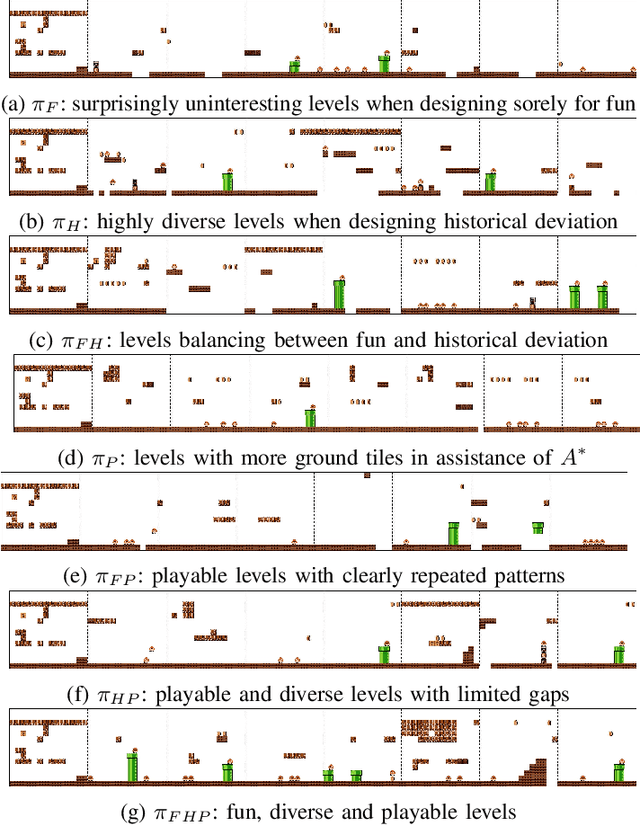
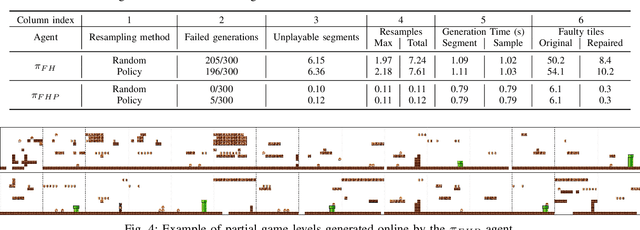
We introduce a procedural content generation (PCG) framework at the intersections of experience-driven PCG and PCG via reinforcement learning, named ED(PCG)RL, EDRL in short. EDRL is able to teach RL designers to generate endless playable levels in an online manner while respecting particular experiences for the player as designed in the form of reward functions. The framework is tested initially in the Super Mario Bros game. In particular, the RL designers of Super Mario Bros generate and concatenate level segments while considering the diversity among the segments. The correctness of the generation is ensured by a neural net-assisted evolutionary level repairer and the playability of the whole level is determined through AI-based testing. Our agents in this EDRL implementation learn to maximise a quantification of Koster's principle of fun by moderating the degree of diversity across level segments. Moreover, we test their ability to design fun levels that are diverse over time and playable. Our proposed framework is capable of generating endless, playable Super Mario Bros levels with varying degrees of fun, deviation from earlier segments, and playability. EDRL can be generalised to any game that is built as a segment-based sequential process and features a built-in compressed representation of its game content.
Robust Reinforcement Learning for General Video Game Playing
Nov 11, 2020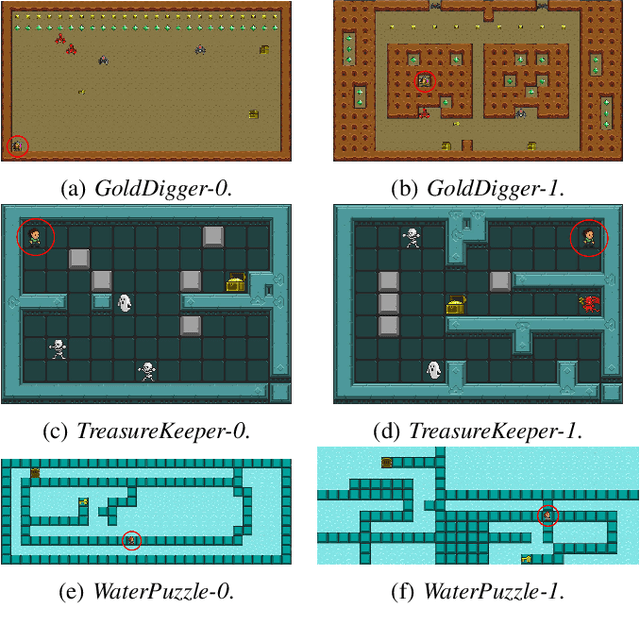
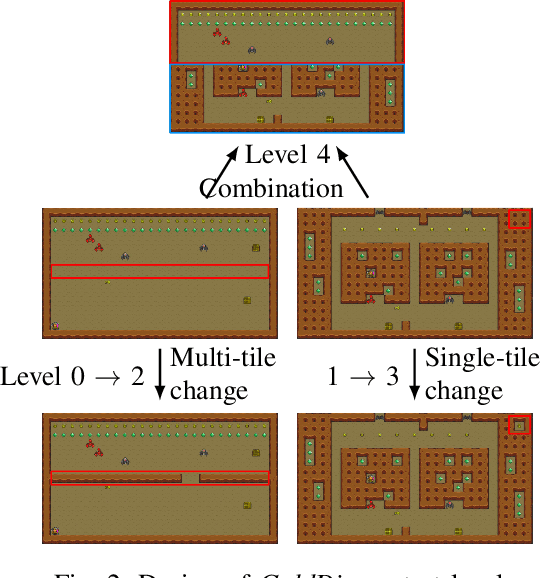
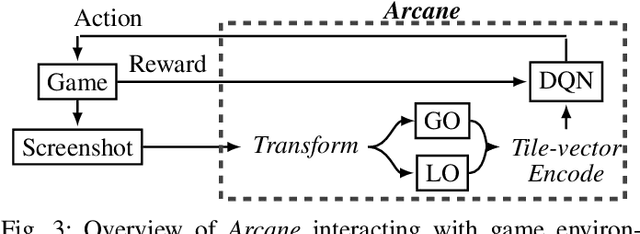
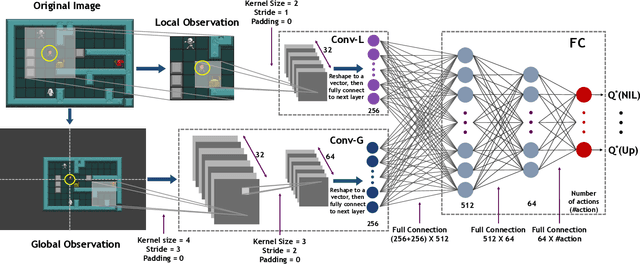
Reinforcement learning has successfully learned to play challenging board and video games. However, its generalization ability remains under-explored. The General Video Game AI Learning Competition aims at designing agents that are capable of learning to play different games levels that were unseen during training. This paper presents the games, entries and results of the 2020 General Video Game AI Learning Competition, held at the Sixteenth International Conference on Parallel Problem Solving from Nature and the 2020 IEEE Conference on Games. Three new games with sparse, periodic and dense rewards, respectively, were designed for this competition and the test levels were generated by adding minor perturbations to training levels or combining training levels. In this paper, we also design a reinforcement learning agent, called Arcane, for general video game playing. We assume that it is more likely to observe similar local information in different levels rather than global information. Therefore, instead of directly inputting a single, raw pixel-based screenshot of current game screen, Arcane takes the encoded, transformed global and local observations of the game screen as two simultaneous inputs, aiming at learning local information for playing new levels. Two versions of Arcane, using a stochastic or deterministic policy for decision-making during test, both show robust performance on the game set of the 2020 General Video Game AI Learning Competition.
A Novel CNet-assisted Evolutionary Level Repairer and Its Applications to Super Mario Bros
May 14, 2020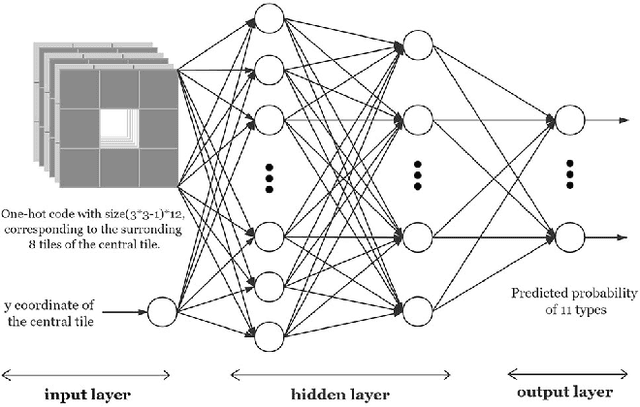

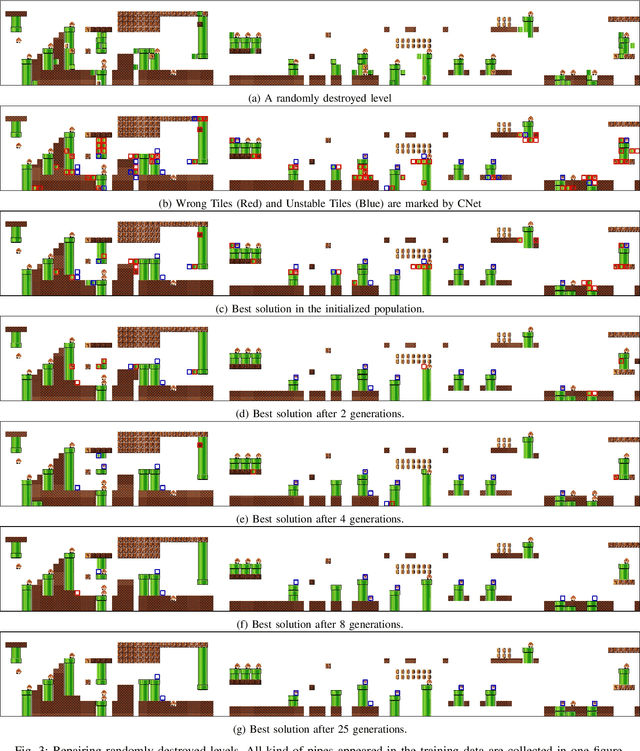
Applying latent variable evolution to game level design has become more and more popular as little human expert knowledge is required. However, defective levels with illegal patterns may be generated due to the violation of constraints for level design. A traditional way of repairing the defective levels is programming specific rule-based repairers to patch the flaw. However, programming these constraints is sometimes complex and not straightforward. An autonomous level repairer which is capable of learning the constraints is needed. In this paper, we propose a novel approach, CNet, to learn the probability distribution of tiles giving its surrounding tiles on a set of real levels, and then detect the illegal tiles in generated new levels. Then, an evolutionary repairer is designed to search for optimal replacement schemes equipped with a novel search space being constructed with the help of CNet and a novel heuristic function. The proposed approaches are proved to be effective in our case study of repairing GAN-generated and artificially destroyed levels of Super Mario Bros. game. Our CNet-assisted evolutionary repairer can also be easily applied to other games of which the levels can be represented by a matrix of objects or tiles.