 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKeep Rehearsing and Refining: Lifelong Learning Vehicle Routing under Continually Drifting Tasks
Jan 30, 2026Existing neural solvers for vehicle routing problems (VRPs) are typically trained either in a one-off manner on a fixed set of pre-defined tasks or in a lifelong manner on several tasks arriving sequentially, assuming sufficient training on each task. Both settings overlook a common real-world property: problem patterns may drift continually over time, yielding massive tasks sequentially arising while offering only limited training resources per task. In this paper, we study a novel lifelong learning paradigm for neural VRP solvers under continually drifting tasks over learning time steps, where sufficient training for any given task at any time is not available. We propose Dual Replay with Experience Enhancement (DREE), a general framework to improve learning efficiency and mitigate catastrophic forgetting under such drift. Extensive experiments show that, under such continual drift, DREE effectively learns new tasks, preserves prior knowledge, improves generalization to unseen tasks, and can be applied to diverse existing neural solvers.
Posterior Distribution-assisted Evolutionary Dynamic Optimization as an Online Calibrator for Complex Social Simulations
Jan 27, 2026The calibration of simulators for complex social systems aims to identify the optimal parameter that drives the output of the simulator best matching the target data observed from the system. As many social systems may change internally over time, calibration naturally becomes an online task, requiring parameters to be updated continuously to maintain the simulator's fidelity. In this work, the online setting is first formulated as a dynamic optimization problem (DOP), requiring the search for a sequence of optimal parameters that fit the simulator to real system changes. However, in contrast to traditional DOP formulations, online calibration explicitly incorporates the observational data as the driver of environmental dynamics. Due to this fundamental difference, existing Evolutionary Dynamic Optimization (EDO) methods, despite being extensively studied for black-box DOPs, are ill-equipped to handle such a scenario. As a result, online calibration problems constitute a new set of challenging DOPs. Here, we propose to explicitly learn the posterior distributions of the parameters and the observational data, thereby facilitating both change detection and environmental adaptation of existing EDOs for this scenario. We thus present a pretrained posterior model for implementation, and fine-tune it during the optimization. Extensive tests on both economic and financial simulators verify that the posterior distribution strongly promotes EDOs in such DOPs widely existed in social science.
Integrating Knowledge Distillation Methods: A Sequential Multi-Stage Framework
Jan 22, 2026Knowledge distillation (KD) transfers knowledge from large teacher models to compact student models, enabling efficient deployment on resource constrained devices. While diverse KD methods, including response based, feature based, and relation based approaches, capture different aspects of teacher knowledge, integrating multiple methods or knowledge sources is promising but often hampered by complex implementation, inflexible combinations, and catastrophic forgetting, which limits practical effectiveness. This work proposes SMSKD (Sequential Multi Stage Knowledge Distillation), a flexible framework that sequentially integrates heterogeneous KD methods. At each stage, the student is trained with a specific distillation method, while a frozen reference model from the previous stage anchors learned knowledge to mitigate forgetting. In addition, we introduce an adaptive weighting mechanism based on the teacher true class probability (TCP) that dynamically adjusts the reference loss per sample to balance knowledge retention and integration. By design, SMSKD supports arbitrary method combinations and stage counts with negligible computational overhead. Extensive experiments show that SMSKD consistently improves student accuracy across diverse teacher student architectures and method combinations, outperforming existing baselines. Ablation studies confirm that stage wise distillation and reference model supervision are primary contributors to performance gains, with TCP based adaptive weighting providing complementary benefits. Overall, SMSKD is a practical and resource efficient solution for integrating heterogeneous KD methods.
ReaSeq: Unleashing World Knowledge via Reasoning for Sequential Modeling
Dec 24, 2025Industrial recommender systems face two fundamental limitations under the log-driven paradigm: (1) knowledge poverty in ID-based item representations that causes brittle interest modeling under data sparsity, and (2) systemic blindness to beyond-log user interests that constrains model performance within platform boundaries. These limitations stem from an over-reliance on shallow interaction statistics and close-looped feedback while neglecting the rich world knowledge about product semantics and cross-domain behavioral patterns that Large Language Models have learned from vast corpora. To address these challenges, we introduce ReaSeq, a reasoning-enhanced framework that leverages world knowledge in Large Language Models to address both limitations through explicit and implicit reasoning. Specifically, ReaSeq employs explicit Chain-of-Thought reasoning via multi-agent collaboration to distill structured product knowledge into semantically enriched item representations, and latent reasoning via Diffusion Large Language Models to infer plausible beyond-log behaviors. Deployed on Taobao's ranking system serving hundreds of millions of users, ReaSeq achieves substantial gains: >6.0% in IPV and CTR, >2.9% in Orders, and >2.5% in GMV, validating the effectiveness of world-knowledge-enhanced reasoning over purely log-driven approaches.
Estimate Hitting Time by Hitting Probability for Elitist Evolutionary Algorithms
Jun 18, 2025



Drift analysis is a powerful tool for analyzing the time complexity of evolutionary algorithms. However, it requires manual construction of drift functions to bound hitting time for each specific algorithm and problem. To address this limitation, general linear drift functions were introduced for elitist evolutionary algorithms. But calculating linear bound coefficients effectively remains a problem. This paper proposes a new method called drift analysis of hitting probability to compute these coefficients. Each coefficient is interpreted as a bound on the hitting probability of a fitness level, transforming the task of estimating hitting time into estimating hitting probability. A novel drift analysis method is then developed to estimate hitting probability, where paths are introduced to handle multimodal fitness landscapes. Explicit expressions are constructed to compute hitting probability, significantly simplifying the estimation process. One advantage of the proposed method is its ability to estimate both the lower and upper bounds of hitting time and to compare the performance of two algorithms in terms of hitting time. To demonstrate this application, two algorithms for the knapsack problem, each incorporating feasibility rules and greedy repair respectively, are compared. The analysis indicates that neither constraint handling technique consistently outperforms the other.
AutoSchemaKG: Autonomous Knowledge Graph Construction through Dynamic Schema Induction from Web-Scale Corpora
May 29, 2025
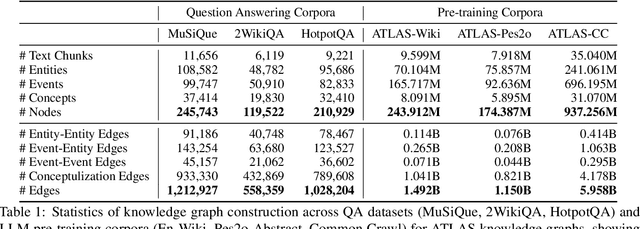
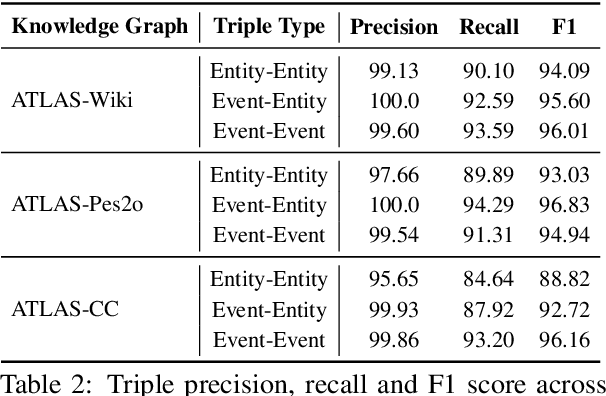

We present AutoSchemaKG, a framework for fully autonomous knowledge graph construction that eliminates the need for predefined schemas. Our system leverages large language models to simultaneously extract knowledge triples and induce comprehensive schemas directly from text, modeling both entities and events while employing conceptualization to organize instances into semantic categories. Processing over 50 million documents, we construct ATLAS (Automated Triple Linking And Schema induction), a family of knowledge graphs with 900+ million nodes and 5.9 billion edges. This approach outperforms state-of-the-art baselines on multi-hop QA tasks and enhances LLM factuality. Notably, our schema induction achieves 95\% semantic alignment with human-crafted schemas with zero manual intervention, demonstrating that billion-scale knowledge graphs with dynamically induced schemas can effectively complement parametric knowledge in large language models.
MoE Parallel Folding: Heterogeneous Parallelism Mappings for Efficient Large-Scale MoE Model Training with Megatron Core
Apr 21, 2025



Mixture of Experts (MoE) models enhance neural network scalability by dynamically selecting relevant experts per input token, enabling larger model sizes while maintaining manageable computation costs. However, efficient training of large-scale MoE models across thousands of GPUs presents significant challenges due to limitations in existing parallelism strategies. We introduce an end-to-end training framework for large-scale MoE models that utilizes five-dimensional hybrid parallelism: Tensor Parallelism, Expert Parallelism, Context Parallelism, Data Parallelism, and Pipeline Parallelism. Central to our approach is MoE Parallel Folding, a novel strategy that decouples the parallelization of attention and MoE layers in Transformer models, allowing each layer type to adopt optimal parallel configurations. Additionally, we develop a flexible token-level dispatcher that supports both token-dropping and token-dropless MoE training across all five dimensions of parallelism. This dispatcher accommodates dynamic tensor shapes and coordinates different parallelism schemes for Attention and MoE layers, facilitating complex parallelism implementations. Our experiments demonstrate significant improvements in training efficiency and scalability. We achieve up to 49.3% Model Flops Utilization (MFU) for the Mixtral 8x22B model and 39.0% MFU for the Qwen2-57B-A14B model on H100 GPUs, outperforming existing methods. The framework scales efficiently up to 1,024 GPUs and maintains high performance with sequence lengths up to 128K tokens, validating its effectiveness for large-scale MoE model training. The code is available in Megatron-Core.
Procedural Fairness and Its Relationship with Distributive Fairness in Machine Learning
Jan 12, 2025Fairness in machine learning (ML) has garnered significant attention in recent years. While existing research has predominantly focused on the distributive fairness of ML models, there has been limited exploration of procedural fairness. This paper proposes a novel method to achieve procedural fairness during the model training phase. The effectiveness of the proposed method is validated through experiments conducted on one synthetic and six real-world datasets. Additionally, this work studies the relationship between procedural fairness and distributive fairness in ML models. On one hand, the impact of dataset bias and the procedural fairness of ML model on its distributive fairness is examined. The results highlight a significant influence of both dataset bias and procedural fairness on distributive fairness. On the other hand, the distinctions between optimizing procedural and distributive fairness metrics are analyzed. Experimental results demonstrate that optimizing procedural fairness metrics mitigates biases introduced or amplified by the decision-making process, thereby ensuring fairness in the decision-making process itself, as well as improving distributive fairness. In contrast, optimizing distributive fairness metrics encourages the ML model's decision-making process to favor disadvantaged groups, counterbalancing the inherent preferences for advantaged groups present in the dataset and ultimately achieving distributive fairness.
Artificial Intelligence without Restriction Surpassing Human Intelligence with Probability One: Theoretical Insight into Secrets of the Brain with AI Twins of the Brain
Dec 04, 2024



Artificial Intelligence (AI) has apparently become one of the most important techniques discovered by humans in history while the human brain is widely recognized as one of the most complex systems in the universe. One fundamental critical question which would affect human sustainability remains open: Will artificial intelligence (AI) evolve to surpass human intelligence in the future? This paper shows that in theory new AI twins with fresh cellular level of AI techniques for neuroscience could approximate the brain and its functioning systems (e.g. perception and cognition functions) with any expected small error and AI without restrictions could surpass human intelligence with probability one in the end. This paper indirectly proves the validity of the conjecture made by Frank Rosenblatt 70 years ago about the potential capabilities of AI, especially in the realm of artificial neural networks. Intelligence is just one of fortuitous but sophisticated creations of the nature which has not been fully discovered. Like mathematics and physics, with no restrictions artificial intelligence would lead to a new subject with its self-contained systems and principles. We anticipate that this paper opens new doors for 1) AI twins and other AI techniques to be used in cellular level of efficient neuroscience dynamic analysis, functioning analysis of the brain and brain illness solutions; 2) new worldwide collaborative scheme for interdisciplinary teams concurrently working on and modelling different types of neurons and synapses and different level of functioning subsystems of the brain with AI techniques; 3) development of low energy of AI techniques with the aid of fundamental neuroscience properties; and 4) new controllable, explainable and safe AI techniques with reasoning capabilities of discovering principles in nature.
PFAttack: Stealthy Attack Bypassing Group Fairness in Federated Learning
Oct 09, 2024



Federated learning (FL), integrating group fairness mechanisms, allows multiple clients to collaboratively train a global model that makes unbiased decisions for different populations grouped by sensitive attributes (e.g., gender and race). Due to its distributed nature, previous studies have demonstrated that FL systems are vulnerable to model poisoning attacks. However, these studies primarily focus on perturbing accuracy, leaving a critical question unexplored: Can an attacker bypass the group fairness mechanisms in FL and manipulate the global model to be biased? The motivations for such an attack vary; an attacker might seek higher accuracy, yet fairness considerations typically limit the accuracy of the global model or aim to cause ethical disruption. To address this question, we design a novel form of attack in FL, termed Profit-driven Fairness Attack (PFATTACK), which aims not to degrade global model accuracy but to bypass fairness mechanisms. Our fundamental insight is that group fairness seeks to weaken the dependence of outputs on input attributes related to sensitive information. In the proposed PFATTACK, an attacker can recover this dependence through local fine-tuning across various sensitive groups, thereby creating a biased yet accuracy-preserving malicious model and injecting it into FL through model replacement. Compared to attacks targeting accuracy, PFATTACK is more stealthy. The malicious model in PFATTACK exhibits subtle parameter variations relative to the original global model, making it robust against detection and filtering by Byzantine-resilient aggregations. Extensive experiments on benchmark datasets are conducted for four fair FL frameworks and three Byzantine-resilient aggregations against model poisoning, demonstrating the effectiveness and stealth of PFATTACK in bypassing group fairness mechanisms in FL.