 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVulReaD: Knowledge-Graph-guided Software Vulnerability Reasoning and Detection
Feb 11, 2026Software vulnerability detection (SVD) is a critical challenge in modern systems. Large language models (LLMs) offer natural-language explanations alongside predictions, but most work focuses on binary evaluation, and explanations often lack semantic consistency with Common Weakness Enumeration (CWE) categories. We propose VulReaD, a knowledge-graph-guided approach for vulnerability reasoning and detection that moves beyond binary classification toward CWE-level reasoning. VulReaD leverages a security knowledge graph (KG) as a semantic backbone and uses a strong teacher LLM to generate CWE-consistent contrastive reasoning supervision, enabling student model training without manual annotations. Students are fine-tuned with Odds Ratio Preference Optimization (ORPO) to encourage taxonomy-aligned reasoning while suppressing unsupported explanations. Across three real-world datasets, VulReaD improves binary F1 by 8-10% and multi-class classification by 30% Macro-F1 and 18% Micro-F1 compared to state-of-the-art baselines. Results show that LLMs outperform deep learning baselines in binary detection and that KG-guided reasoning enhances CWE coverage and interpretability.
Instructing Text-to-Image Diffusion Models via Classifier-Guided Semantic Optimization
May 20, 2025Text-to-image diffusion models have emerged as powerful tools for high-quality image generation and editing. Many existing approaches rely on text prompts as editing guidance. However, these methods are constrained by the need for manual prompt crafting, which can be time-consuming, introduce irrelevant details, and significantly limit editing performance. In this work, we propose optimizing semantic embeddings guided by attribute classifiers to steer text-to-image models toward desired edits, without relying on text prompts or requiring any training or fine-tuning of the diffusion model. We utilize classifiers to learn precise semantic embeddings at the dataset level. The learned embeddings are theoretically justified as the optimal representation of attribute semantics, enabling disentangled and accurate edits. Experiments further demonstrate that our method achieves high levels of disentanglement and strong generalization across different domains of data.
Alpha and Prejudice: Improving $α$-sized Worst-case Fairness via Intrinsic Reweighting
Nov 05, 2024Worst-case fairness with off-the-shelf demographics achieves group parity by maximizing the model utility of the worst-off group. Nevertheless, demographic information is often unavailable in practical scenarios, which impedes the use of such a direct max-min formulation. Recent advances have reframed this learning problem by introducing the lower bound of minimal partition ratio, denoted as $\alpha$, as side information, referred to as ``$\alpha$-sized worst-case fairness'' in this paper. We first justify the practical significance of this setting by presenting noteworthy evidence from the data privacy perspective, which has been overlooked by existing research. Without imposing specific requirements on loss functions, we propose reweighting the training samples based on their intrinsic importance to fairness. Given the global nature of the worst-case formulation, we further develop a stochastic learning scheme to simplify the training process without compromising model performance. Additionally, we address the issue of outliers and provide a robust variant to handle potential outliers during model training. Our theoretical analysis and experimental observations reveal the connections between the proposed approaches and existing ``fairness-through-reweighting'' studies, with extensive experimental results on fairness benchmarks demonstrating the superiority of our methods.
PROUD: PaRetO-gUided Diffusion Model for Multi-objective Generation
Jul 05, 2024Recent advancements in the realm of deep generative models focus on generating samples that satisfy multiple desired properties. However, prevalent approaches optimize these property functions independently, thus omitting the trade-offs among them. In addition, the property optimization is often improperly integrated into the generative models, resulting in an unnecessary compromise on generation quality (i.e., the quality of generated samples). To address these issues, we formulate a constrained optimization problem. It seeks to optimize generation quality while ensuring that generated samples reside at the Pareto front of multiple property objectives. Such a formulation enables the generation of samples that cannot be further improved simultaneously on the conflicting property functions and preserves good quality of generated samples. Building upon this formulation, we introduce the PaRetO-gUided Diffusion model (PROUD), wherein the gradients in the denoising process are dynamically adjusted to enhance generation quality while the generated samples adhere to Pareto optimality. Experimental evaluations on image generation and protein generation tasks demonstrate that our PROUD consistently maintains superior generation quality while approaching Pareto optimality across multiple property functions compared to various baselines.
Sanitized Clustering against Confounding Bias
Nov 02, 2023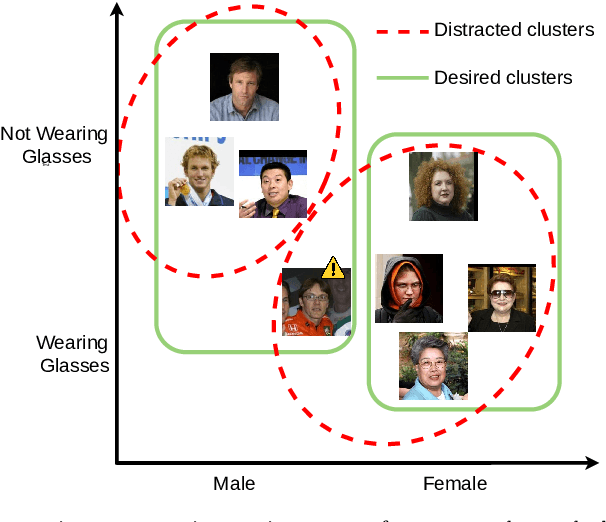
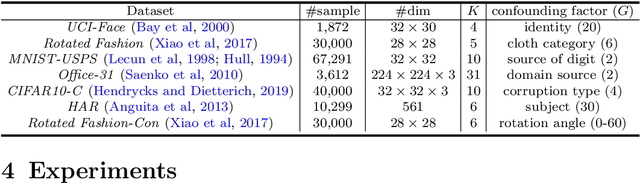
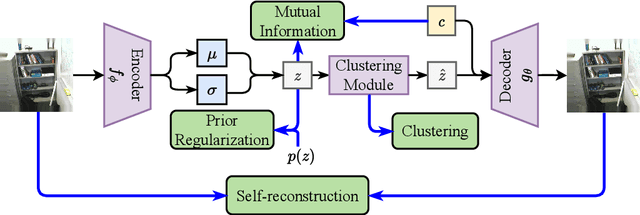
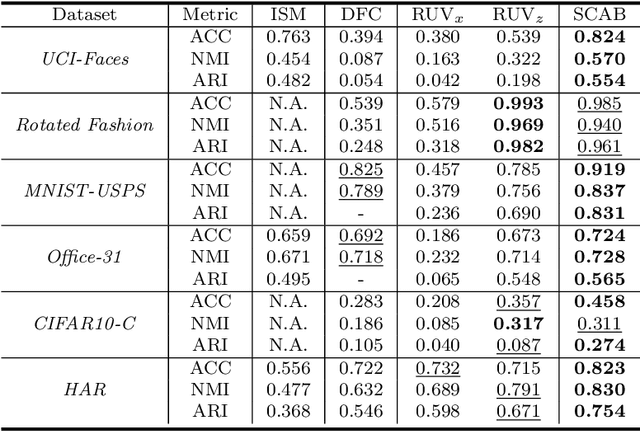
Real-world datasets inevitably contain biases that arise from different sources or conditions during data collection. Consequently, such inconsistency itself acts as a confounding factor that disturbs the cluster analysis. Existing methods eliminate the biases by projecting data onto the orthogonal complement of the subspace expanded by the confounding factor before clustering. Therein, the interested clustering factor and the confounding factor are coarsely considered in the raw feature space, where the correlation between the data and the confounding factor is ideally assumed to be linear for convenient solutions. These approaches are thus limited in scope as the data in real applications is usually complex and non-linearly correlated with the confounding factor. This paper presents a new clustering framework named Sanitized Clustering Against confounding Bias (SCAB), which removes the confounding factor in the semantic latent space of complex data through a non-linear dependence measure. To be specific, we eliminate the bias information in the latent space by minimizing the mutual information between the confounding factor and the latent representation delivered by Variational Auto-Encoder (VAE). Meanwhile, a clustering module is introduced to cluster over the purified latent representations. Extensive experiments on complex datasets demonstrate that our SCAB achieves a significant gain in clustering performance by removing the confounding bias. The code is available at \url{https://github.com/EvaFlower/SCAB}.
Earning Extra Performance from Restrictive Feedbacks
Apr 28, 2023Many machine learning applications encounter a situation where model providers are required to further refine the previously trained model so as to gratify the specific need of local users. This problem is reduced to the standard model tuning paradigm if the target data is permissibly fed to the model. However, it is rather difficult in a wide range of practical cases where target data is not shared with model providers but commonly some evaluations about the model are accessible. In this paper, we formally set up a challenge named \emph{Earning eXtra PerformancE from restriCTive feEDdbacks} (EXPECTED) to describe this form of model tuning problems. Concretely, EXPECTED admits a model provider to access the operational performance of the candidate model multiple times via feedback from a local user (or a group of users). The goal of the model provider is to eventually deliver a satisfactory model to the local user(s) by utilizing the feedbacks. Unlike existing model tuning methods where the target data is always ready for calculating model gradients, the model providers in EXPECTED only see some feedbacks which could be as simple as scalars, such as inference accuracy or usage rate. To enable tuning in this restrictive circumstance, we propose to characterize the geometry of the model performance with regard to model parameters through exploring the parameters' distribution. In particular, for the deep models whose parameters distribute across multiple layers, a more query-efficient algorithm is further tailor-designed that conducts layerwise tuning with more attention to those layers which pay off better. Our theoretical analyses justify the proposed algorithms from the aspects of both efficacy and efficiency. Extensive experiments on different applications demonstrate that our work forges a sound solution to the EXPECTED problem.
Robust Deep Learning Models Against Semantic-Preserving Adversarial Attack
Apr 08, 2023



Deep learning models can be fooled by small $l_p$-norm adversarial perturbations and natural perturbations in terms of attributes. Although the robustness against each perturbation has been explored, it remains a challenge to address the robustness against joint perturbations effectively. In this paper, we study the robustness of deep learning models against joint perturbations by proposing a novel attack mechanism named Semantic-Preserving Adversarial (SPA) attack, which can then be used to enhance adversarial training. Specifically, we introduce an attribute manipulator to generate natural and human-comprehensible perturbations and a noise generator to generate diverse adversarial noises. Based on such combined noises, we optimize both the attribute value and the diversity variable to generate jointly-perturbed samples. For robust training, we adversarially train the deep learning model against the generated joint perturbations. Empirical results on four benchmarks show that the SPA attack causes a larger performance decline with small $l_{\infty}$ norm-ball constraints compared to existing approaches. Furthermore, our SPA-enhanced training outperforms existing defense methods against such joint perturbations.
TRIP: Refining Image-to-Image Translation via Rival Preferences
Nov 26, 2021

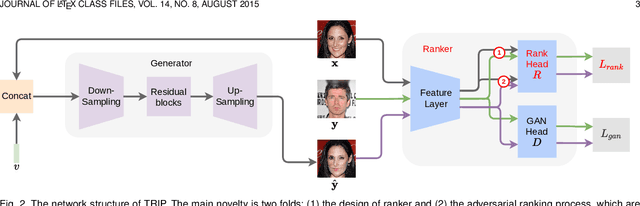
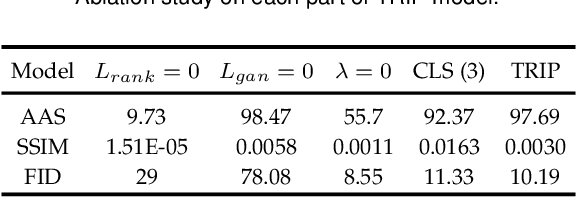
Relative attribute (RA), referring to the preference over two images on the strength of a specific attribute, can enable fine-grained image-to-image translation due to its rich semantic information. Existing work based on RAs however failed to reconcile the goal for fine-grained translation and the goal for high-quality generation. We propose a new model TRIP to coordinate these two goals for high-quality fine-grained translation. In particular, we simultaneously train two modules: a generator that translates an input image to the desired image with smooth subtle changes with respect to the interested attributes; and a ranker that ranks rival preferences consisting of the input image and the desired image. Rival preferences refer to the adversarial ranking process: (1) the ranker thinks no difference between the desired image and the input image in terms of the desired attributes; (2) the generator fools the ranker to believe that the desired image changes the attributes over the input image as desired. RAs over pairs of real images are introduced to guide the ranker to rank image pairs regarding the interested attributes only. With an effective ranker, the generator would "win" the adversarial game by producing high-quality images that present desired changes over the attributes compared to the input image. The experiments on two face image datasets and one shoe image dataset demonstrate that our TRIP achieves state-of-art results in generating high-fidelity images which exhibit smooth changes over the interested attributes.
Differential-Critic GAN: Generating What You Want by a Cue of Preferences
Jul 14, 2021


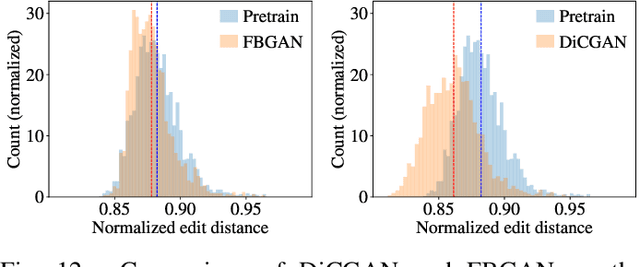
This paper proposes Differential-Critic Generative Adversarial Network (DiCGAN) to learn the distribution of user-desired data when only partial instead of the entire dataset possesses the desired property, which generates desired data that meets user's expectations and can assist in designing biological products with desired properties. Existing approaches select the desired samples first and train regular GANs on the selected samples to derive the user-desired data distribution. However, the selection of the desired data relies on an expert criterion and supervision over the entire dataset. DiCGAN introduces a differential critic that can learn the preference direction from the pairwise preferences, which is amateur knowledge and can be defined on part of the training data. The resultant critic guides the generation of the desired data instead of the whole data. Specifically, apart from the Wasserstein GAN loss, a ranking loss of the pairwise preferences is defined over the critic. It endows the difference of critic values between each pair of samples with the pairwise preference relation. The higher critic value indicates that the sample is preferred by the user. Thus training the generative model for higher critic values encourages the generation of user-preferred samples. Extensive experiments show that our DiCGAN achieves state-of-the-art performance in learning the user-desired data distributions, especially in the cases of insufficient desired data and limited supervision.