 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Bridge: Feature Delta Prediction for Efficient Dual-System Vision-Language-Action Model Inference
May 04, 2026Dual-system Vision-Language-Action (VLA) models achieve state-of-the-art robotic manipulation but are bottlenecked by the VLM backbone, which must execute at every control step while producing temporally redundant features. We propose Latent Bridge, a lightweight model that predicts VLM output deltas between timesteps, enabling the action head to operate on predicted outputs while the expensive VLM backbone is called only periodically. We instantiate Latent Bridge on two architecturally distinct VLAs: GR00T-N1.6 (feature-space bridge) and π0.5 (KV-cache bridge), demonstrating that the approach generalizes across VLA designs. Our task-agnostic DAgger training pipeline transfers across benchmarks without modification. Across four LIBERO suites, 24 RoboCasa kitchen tasks, and the ALOHA sim transfer-cube task, Latent Bridge achieves 95-100% performance retention while reducing VLM calls by 50-75%, yielding 1.65-1.73x net per-episode speedup.
ForeSea: AI Forensic Search with Multi-modal Queries for Video Surveillance
Mar 24, 2026Despite decades of work, surveillance still struggles to find specific targets across long, multi-camera video. Prior methods -- tracking pipelines, CLIP based models, and VideoRAG -- require heavy manual filtering, capture only shallow attributes, and fail at temporal reasoning. Real-world searches are inherently multimodal (e.g., "When does this person join the fight?" with the person's image), yet this setting remains underexplored. Also, there are no proper benchmarks to evaluate those setting - asking video with multimodal queries. To address this gap, we introduce ForeSeaQA, a new benchmark specifically designed for video QA with image-and-text queries and timestamped annotations of key events. The dataset consists of long-horizon surveillance footage paired with diverse multimodal questions, enabling systematic evaluation of retrieval, temporal grounding, and multimodal reasoning in realistic forensic conditions. Not limited to this benchmark, we propose ForeSea, an AI forensic search system with a 3-stage, plug-and-play pipeline. (1) A tracking module filters irrelevant footage; (2) a multimodal embedding module indexes the remaining clips; and (3) during inference, the system retrieves top-K candidate clips for a Video Large Language Model (VideoLLM) to answer queries and localize events. On ForeSeaQA, ForeSea improves accuracy by 3.5% and temporal IoU by 11.0 over prior VideoRAG models. To our knowledge, ForeSeaQA is the first benchmark to support complex multimodal queries with precise temporal grounding, and ForeSea is the first VideoRAG system built to excel in this setting.
EgoPrivacy: What Your First-Person Camera Says About You?
Jun 13, 2025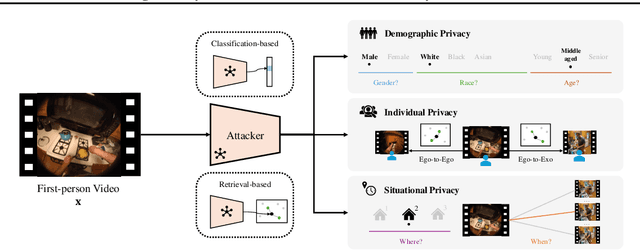
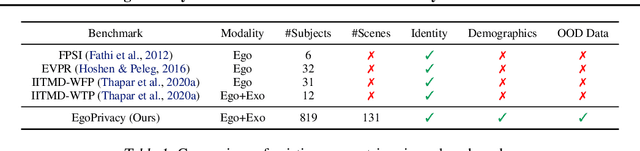
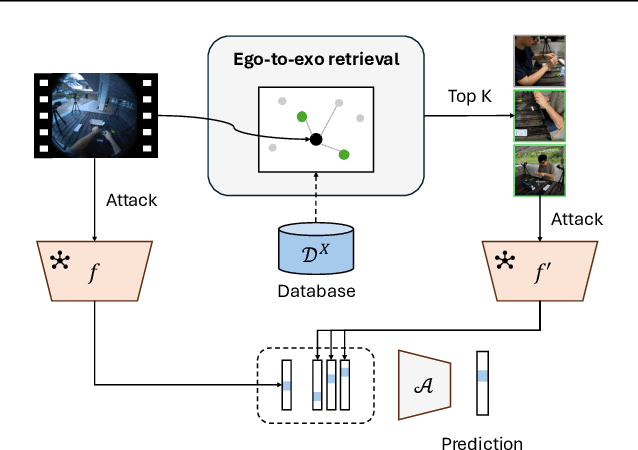
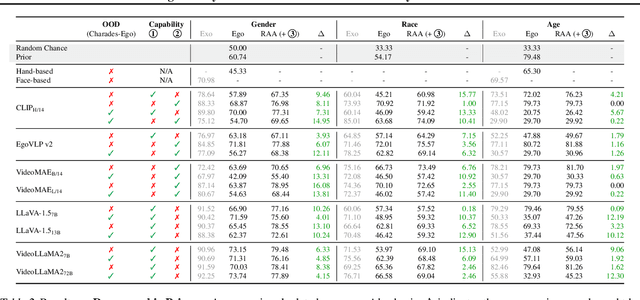
While the rapid proliferation of wearable cameras has raised significant concerns about egocentric video privacy, prior work has largely overlooked the unique privacy threats posed to the camera wearer. This work investigates the core question: How much privacy information about the camera wearer can be inferred from their first-person view videos? We introduce EgoPrivacy, the first large-scale benchmark for the comprehensive evaluation of privacy risks in egocentric vision. EgoPrivacy covers three types of privacy (demographic, individual, and situational), defining seven tasks that aim to recover private information ranging from fine-grained (e.g., wearer's identity) to coarse-grained (e.g., age group). To further emphasize the privacy threats inherent to egocentric vision, we propose Retrieval-Augmented Attack, a novel attack strategy that leverages ego-to-exo retrieval from an external pool of exocentric videos to boost the effectiveness of demographic privacy attacks. An extensive comparison of the different attacks possible under all threat models is presented, showing that private information of the wearer is highly susceptible to leakage. For instance, our findings indicate that foundation models can effectively compromise wearer privacy even in zero-shot settings by recovering attributes such as identity, scene, gender, and race with 70-80% accuracy. Our code and data are available at https://github.com/williamium3000/ego-privacy.
POP: Prompt Of Prompts for Continual Learning
Jun 14, 2023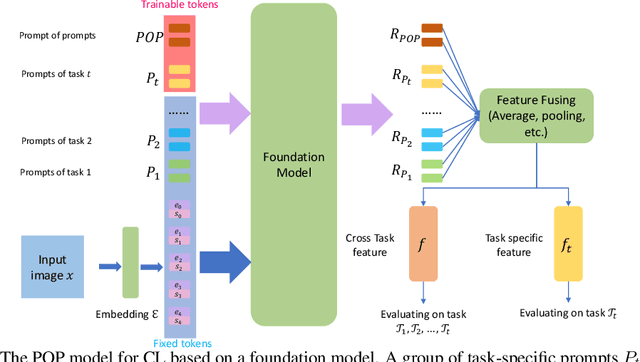
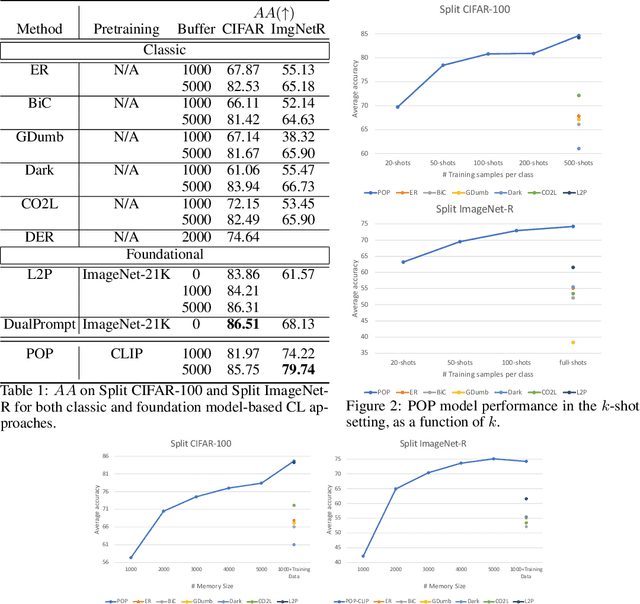
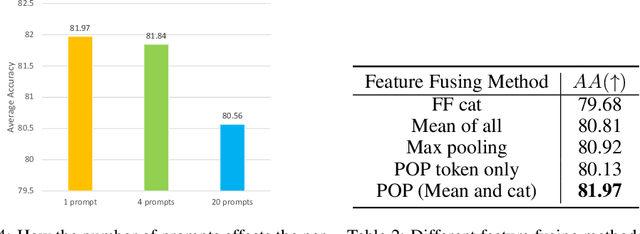
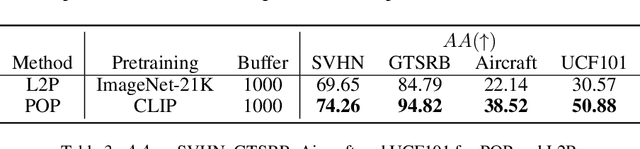
Continual learning (CL) has attracted increasing attention in the recent past. It aims to mimic the human ability to learn new concepts without catastrophic forgetting. While existing CL methods accomplish this to some extent, they are still prone to semantic drift of the learned feature space. Foundation models, which are endowed with a robust feature representation, learned from very large datasets, provide an interesting substrate for the solution of the CL problem. Recent work has also shown that they can be adapted to specific tasks by prompt tuning techniques that leave the generality of the representation mostly unscathed. An open question is, however, how to learn both prompts that are task specific and prompts that are global, i.e. capture cross-task information. In this work, we propose the Prompt Of Prompts (POP) model, which addresses this goal by progressively learning a group of task-specified prompts and a group of global prompts, denoted as POP, to integrate information from the former. We show that a foundation model equipped with POP learning is able to outperform classic CL methods by a significant margin. Moreover, as prompt tuning only requires a small set of training samples, POP is able to perform CL in the few-shot setting, while still outperforming competing methods trained on the entire dataset.
FedPDD: A Privacy-preserving Double Distillation Framework for Cross-silo Federated Recommendation
May 09, 2023Cross-platform recommendation aims to improve recommendation accuracy by gathering heterogeneous features from different platforms. However, such cross-silo collaborations between platforms are restricted by increasingly stringent privacy protection regulations, thus data cannot be aggregated for training. Federated learning (FL) is a practical solution to deal with the data silo problem in recommendation scenarios. Existing cross-silo FL methods transmit model information to collaboratively build a global model by leveraging the data of overlapped users. However, in reality, the number of overlapped users is often very small, thus largely limiting the performance of such approaches. Moreover, transmitting model information during training requires high communication costs and may cause serious privacy leakage. In this paper, we propose a novel privacy-preserving double distillation framework named FedPDD for cross-silo federated recommendation, which efficiently transfers knowledge when overlapped users are limited. Specifically, our double distillation strategy enables local models to learn not only explicit knowledge from the other party but also implicit knowledge from its past predictions. Moreover, to ensure privacy and high efficiency, we employ an offline training scheme to reduce communication needs and privacy leakage risk. In addition, we adopt differential privacy to further protect the transmitted information. The experiments on two real-world recommendation datasets, HetRec-MovieLens and Criteo, demonstrate the effectiveness of FedPDD compared to the state-of-the-art approaches.
Robust Deep Learning Models Against Semantic-Preserving Adversarial Attack
Apr 08, 2023



Deep learning models can be fooled by small $l_p$-norm adversarial perturbations and natural perturbations in terms of attributes. Although the robustness against each perturbation has been explored, it remains a challenge to address the robustness against joint perturbations effectively. In this paper, we study the robustness of deep learning models against joint perturbations by proposing a novel attack mechanism named Semantic-Preserving Adversarial (SPA) attack, which can then be used to enhance adversarial training. Specifically, we introduce an attribute manipulator to generate natural and human-comprehensible perturbations and a noise generator to generate diverse adversarial noises. Based on such combined noises, we optimize both the attribute value and the diversity variable to generate jointly-perturbed samples. For robust training, we adversarially train the deep learning model against the generated joint perturbations. Empirical results on four benchmarks show that the SPA attack causes a larger performance decline with small $l_{\infty}$ norm-ball constraints compared to existing approaches. Furthermore, our SPA-enhanced training outperforms existing defense methods against such joint perturbations.
MobileInst: Video Instance Segmentation on the Mobile
Mar 30, 2023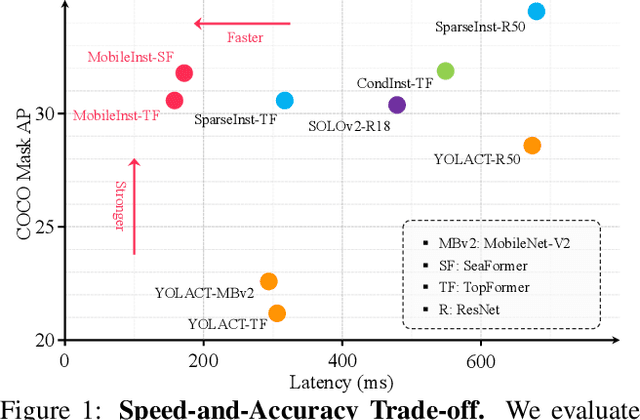
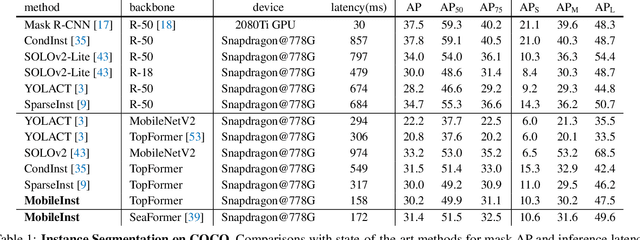

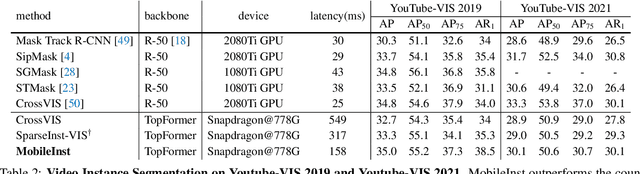
Although recent approaches aiming for video instance segmentation have achieved promising results, it is still difficult to employ those approaches for real-world applications on mobile devices, which mainly suffer from (1) heavy computation and memory cost and (2) complicated heuristics for tracking objects. To address those issues, we present MobileInst, a lightweight and mobile-friendly framework for video instance segmentation on mobile devices. Firstly, MobileInst adopts a mobile vision transformer to extract multi-level semantic features and presents an efficient query-based dual-transformer instance decoder for mask kernels and a semantic-enhanced mask decoder to generate instance segmentation per frame. Secondly, MobileInst exploits simple yet effective kernel reuse and kernel association to track objects for video instance segmentation. Further, we propose temporal query passing to enhance the tracking ability for kernels. We conduct experiments on COCO and YouTube-VIS datasets to demonstrate the superiority of MobileInst and evaluate the inference latency on a mobile CPU core of Qualcomm Snapdragon-778G, without other methods of acceleration. On the COCO dataset, MobileInst achieves 30.5 mask AP and 176 ms on the mobile CPU, which reduces the latency by 50% compared to the previous SOTA. For video instance segmentation, MobileInst achieves 35.0 AP on YouTube-VIS 2019 and 30.1 AP on YouTube-VIS 2021. Code will be available to facilitate real-world applications and future research.
Dense Network Expansion for Class Incremental Learning
Mar 22, 2023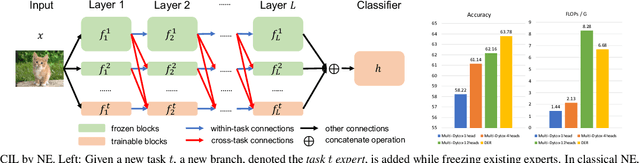
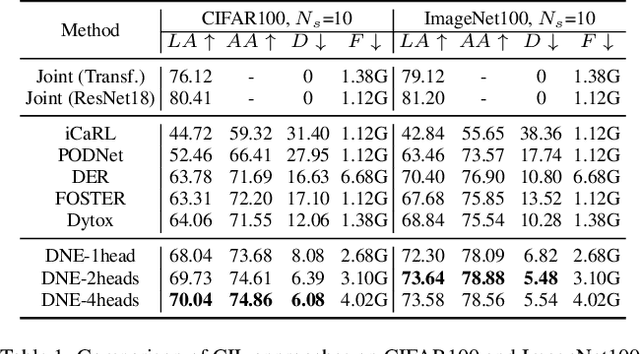
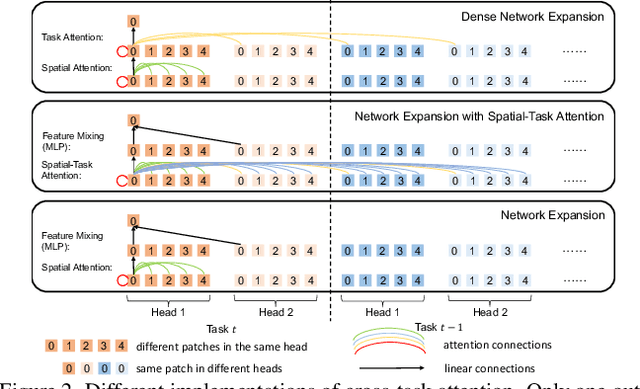
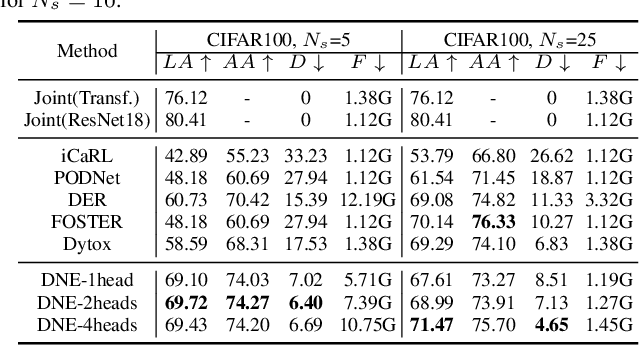
The problem of class incremental learning (CIL) is considered. State-of-the-art approaches use a dynamic architecture based on network expansion (NE), in which a task expert is added per task. While effective from a computational standpoint, these methods lead to models that grow quickly with the number of tasks. A new NE method, dense network expansion (DNE), is proposed to achieve a better trade-off between accuracy and model complexity. This is accomplished by the introduction of dense connections between the intermediate layers of the task expert networks, that enable the transfer of knowledge from old to new tasks via feature sharing and reusing. This sharing is implemented with a cross-task attention mechanism, based on a new task attention block (TAB), that fuses information across tasks. Unlike traditional attention mechanisms, TAB operates at the level of the feature mixing and is decoupled with spatial attentions. This is shown more effective than a joint spatial-and-task attention for CIL. The proposed DNE approach can strictly maintain the feature space of old classes while growing the network and feature scale at a much slower rate than previous methods. In result, it outperforms the previous SOTA methods by a margin of 4\% in terms of accuracy, with similar or even smaller model scale.
A Survey on Heterogeneous Federated Learning
Oct 10, 2022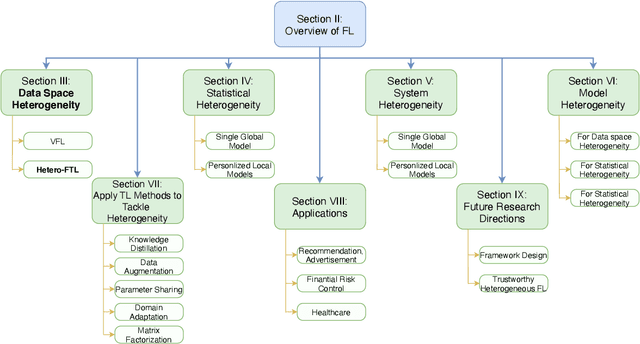
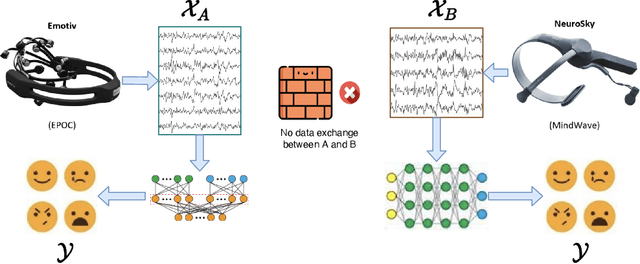
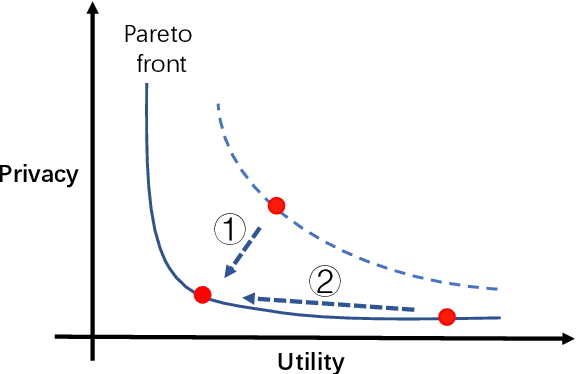
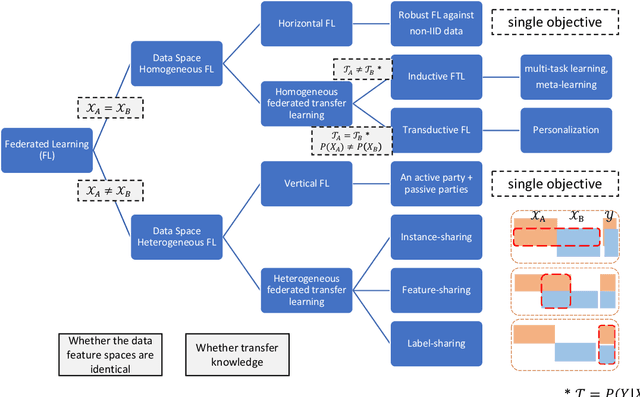
Federated learning (FL) has been proposed to protect data privacy and virtually assemble the isolated data silos by cooperatively training models among organizations without breaching privacy and security. However, FL faces heterogeneity from various aspects, including data space, statistical, and system heterogeneity. For example, collaborative organizations without conflict of interest often come from different areas and have heterogeneous data from different feature spaces. Participants may also want to train heterogeneous personalized local models due to non-IID and imbalanced data distribution and various resource-constrained devices. Therefore, heterogeneous FL is proposed to address the problem of heterogeneity in FL. In this survey, we comprehensively investigate the domain of heterogeneous FL in terms of data space, statistical, system, and model heterogeneity. We first give an overview of FL, including its definition and categorization. Then, We propose a precise taxonomy of heterogeneous FL settings for each type of heterogeneity according to the problem setting and learning objective. We also investigate the transfer learning methodologies to tackle the heterogeneity in FL. We further present the applications of heterogeneous FL. Finally, we highlight the challenges and opportunities and envision promising future research directions toward new framework design and trustworthy approaches.
Privacy Threats Against Federated Matrix Factorization
Jul 03, 2020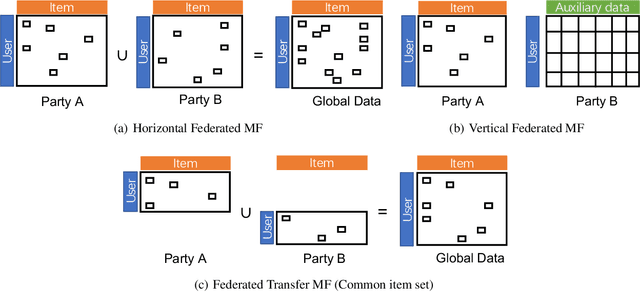
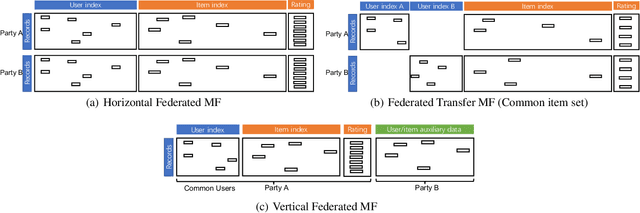
Matrix Factorization has been very successful in practical recommendation applications and e-commerce. Due to data shortage and stringent regulations, it can be hard to collect sufficient data to build performant recommender systems for a single company. Federated learning provides the possibility to bridge the data silos and build machine learning models without compromising privacy and security. Participants sharing common users or items collaboratively build a model over data from all the participants. There have been some works exploring the application of federated learning to recommender systems and the privacy issues in collaborative filtering systems. However, the privacy threats in federated matrix factorization are not studied. In this paper, we categorize federated matrix factorization into three types based on the partition of feature space and analyze privacy threats against each type of federated matrix factorization model. We also discuss privacy-preserving approaches. As far as we are aware, this is the first study of privacy threats of the matrix factorization method in the federated learning framework.