 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMM-OPERA: Benchmarking Open-ended Association Reasoning for Large Vision-Language Models
Oct 30, 2025Large Vision-Language Models (LVLMs) have exhibited remarkable progress. However, deficiencies remain compared to human intelligence, such as hallucination and shallow pattern matching. In this work, we aim to evaluate a fundamental yet underexplored intelligence: association, a cornerstone of human cognition for creative thinking and knowledge integration. Current benchmarks, often limited to closed-ended tasks, fail to capture the complexity of open-ended association reasoning vital for real-world applications. To address this, we present MM-OPERA, a systematic benchmark with 11,497 instances across two open-ended tasks: Remote-Item Association (RIA) and In-Context Association (ICA), aligning association intelligence evaluation with human psychometric principles. It challenges LVLMs to resemble the spirit of divergent thinking and convergent associative reasoning through free-form responses and explicit reasoning paths. We deploy tailored LLM-as-a-Judge strategies to evaluate open-ended outputs, applying process-reward-informed judgment to dissect reasoning with precision. Extensive empirical studies on state-of-the-art LVLMs, including sensitivity analysis of task instances, validity analysis of LLM-as-a-Judge strategies, and diversity analysis across abilities, domains, languages, cultures, etc., provide a comprehensive and nuanced understanding of the limitations of current LVLMs in associative reasoning, paving the way for more human-like and general-purpose AI. The dataset and code are available at https://github.com/MM-OPERA-Bench/MM-OPERA.
GAM-Agent: Game-Theoretic and Uncertainty-Aware Collaboration for Complex Visual Reasoning
May 29, 2025We propose GAM-Agent, a game-theoretic multi-agent framework for enhancing vision-language reasoning. Unlike prior single-agent or monolithic models, GAM-Agent formulates the reasoning process as a non-zero-sum game between base agents--each specializing in visual perception subtasks--and a critical agent that verifies logic consistency and factual correctness. Agents communicate via structured claims, evidence, and uncertainty estimates. The framework introduces an uncertainty-aware controller to dynamically adjust agent collaboration, triggering multi-round debates when disagreement or ambiguity is detected. This process yields more robust and interpretable predictions. Experiments on four challenging benchmarks--MMMU, MMBench, MVBench, and V*Bench--demonstrate that GAM-Agent significantly improves performance across various VLM backbones. Notably, GAM-Agent boosts the accuracy of small-to-mid scale models (e.g., Qwen2.5-VL-7B, InternVL3-14B) by 5--6\%, and still enhances strong models like GPT-4o by up to 2--3\%. Our approach is modular, scalable, and generalizable, offering a path toward reliable and explainable multi-agent multimodal reasoning.
GaussTR: Foundation Model-Aligned Gaussian Transformer for Self-Supervised 3D Spatial Understanding
Dec 17, 20243D Semantic Occupancy Prediction is fundamental for spatial understanding as it provides a comprehensive semantic cognition of surrounding environments. However, prevalent approaches primarily rely on extensive labeled data and computationally intensive voxel-based modeling, restricting the scalability and generalizability of 3D representation learning. In this paper, we introduce GaussTR, a novel Gaussian Transformer that leverages alignment with foundation models to advance self-supervised 3D spatial understanding. GaussTR adopts a Transformer architecture to predict sparse sets of 3D Gaussians that represent scenes in a feed-forward manner. Through aligning rendered Gaussian features with diverse knowledge from pre-trained foundation models, GaussTR facilitates the learning of versatile 3D representations and enables open-vocabulary occupancy prediction without explicit annotations. Empirical evaluations on the Occ3D-nuScenes dataset showcase GaussTR's state-of-the-art zero-shot performance, achieving 11.70 mIoU while reducing training duration by approximately 50%. These experimental results highlight the significant potential of GaussTR for scalable and holistic 3D spatial understanding, with promising implications for autonomous driving and embodied agents. Code is available at https://github.com/hustvl/GaussTR.
Symphonize 3D Semantic Scene Completion with Contextual Instance Queries
Jun 27, 2023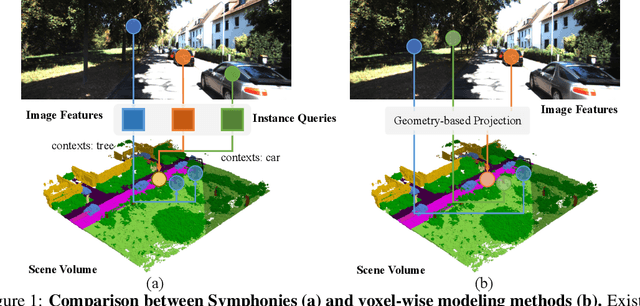
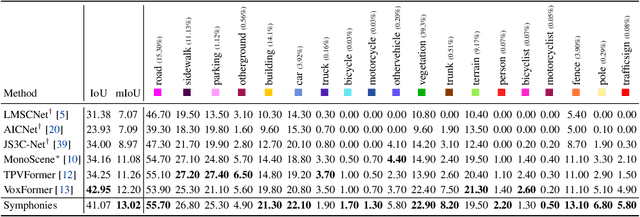
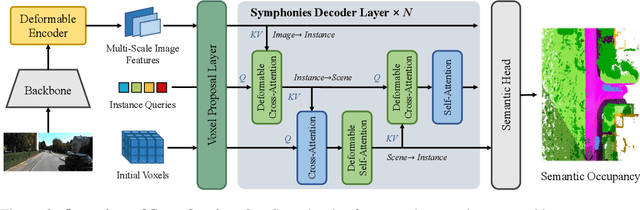
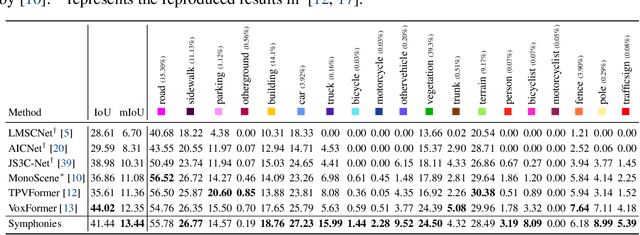
3D Semantic Scene Completion (SSC) has emerged as a nascent and pivotal task for autonomous driving, as it involves predicting per-voxel occupancy within a 3D scene from partial LiDAR or image inputs. Existing methods primarily focus on the voxel-wise feature aggregation, while neglecting the instance-centric semantics and broader context. In this paper, we present a novel paradigm termed Symphonies (Scene-from-Insts) for SSC, which completes the scene volume from a sparse set of instance queries derived from the input with context awareness. By incorporating the queries as the instance feature representations within the scene, Symphonies dynamically encodes the instance-centric semantics to interact with the image and volume features while avoiding the dense voxel-wise modeling. Simultaneously, it orchestrates a more comprehensive understanding of the scenario by capturing context throughout the entire scene, contributing to alleviating the geometric ambiguity derived from occlusion and perspective errors. Symphonies achieves a state-of-the-art result of 13.02 mIoU on the challenging SemanticKITTI dataset, outperforming existing methods and showcasing the promising advancements of the paradigm. The code is available at \url{https://github.com/hustvl/Symphonies}.
MobileInst: Video Instance Segmentation on the Mobile
Mar 30, 2023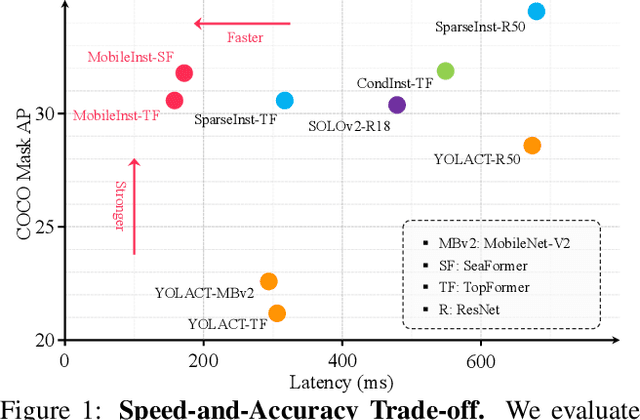
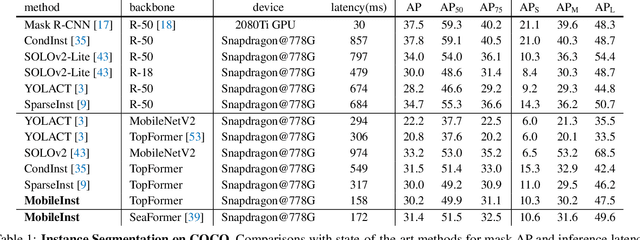

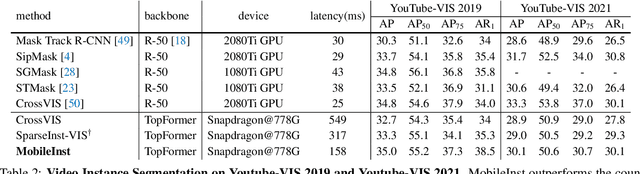
Although recent approaches aiming for video instance segmentation have achieved promising results, it is still difficult to employ those approaches for real-world applications on mobile devices, which mainly suffer from (1) heavy computation and memory cost and (2) complicated heuristics for tracking objects. To address those issues, we present MobileInst, a lightweight and mobile-friendly framework for video instance segmentation on mobile devices. Firstly, MobileInst adopts a mobile vision transformer to extract multi-level semantic features and presents an efficient query-based dual-transformer instance decoder for mask kernels and a semantic-enhanced mask decoder to generate instance segmentation per frame. Secondly, MobileInst exploits simple yet effective kernel reuse and kernel association to track objects for video instance segmentation. Further, we propose temporal query passing to enhance the tracking ability for kernels. We conduct experiments on COCO and YouTube-VIS datasets to demonstrate the superiority of MobileInst and evaluate the inference latency on a mobile CPU core of Qualcomm Snapdragon-778G, without other methods of acceleration. On the COCO dataset, MobileInst achieves 30.5 mask AP and 176 ms on the mobile CPU, which reduces the latency by 50% compared to the previous SOTA. For video instance segmentation, MobileInst achieves 35.0 AP on YouTube-VIS 2019 and 30.1 AP on YouTube-VIS 2021. Code will be available to facilitate real-world applications and future research.