 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking RGB-Event Semantic Segmentation with a Novel Bidirectional Motion-enhanced Event Representation
May 02, 2025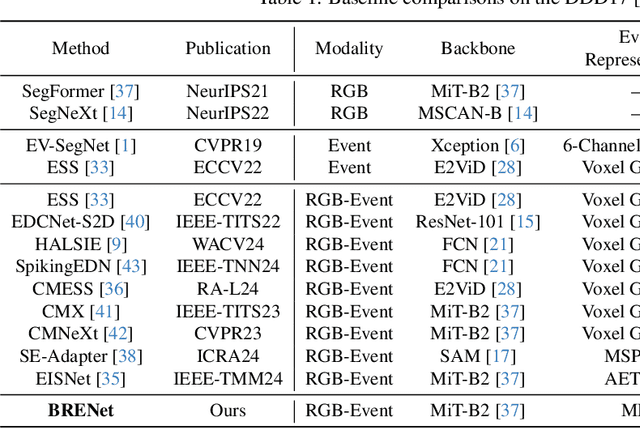
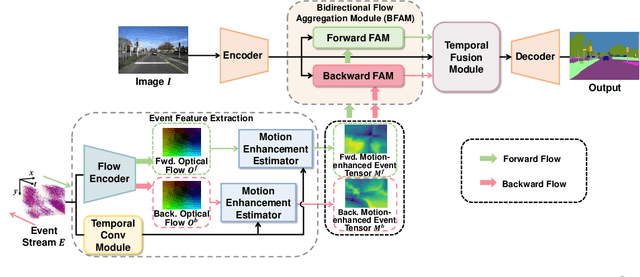
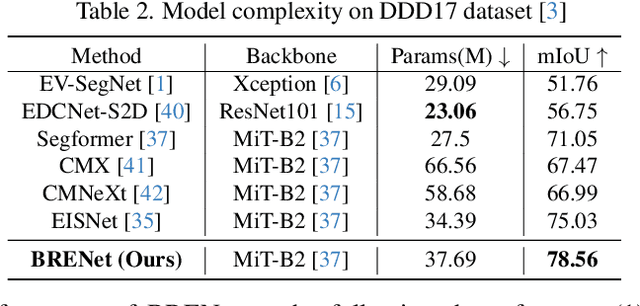
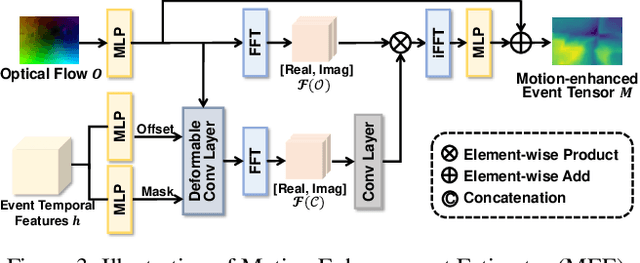
Event cameras capture motion dynamics, offering a unique modality with great potential in various computer vision tasks. However, RGB-Event fusion faces three intrinsic misalignments: (i) temporal, (ii) spatial, and (iii) modal misalignment. Existing voxel grid representations neglect temporal correlations between consecutive event windows, and their formulation with simple accumulation of asynchronous and sparse events is incompatible with the synchronous and dense nature of RGB modality. To tackle these challenges, we propose a novel event representation, Motion-enhanced Event Tensor (MET), which transforms sparse event voxels into a dense and temporally coherent form by leveraging dense optical flows and event temporal features. In addition, we introduce a Frequency-aware Bidirectional Flow Aggregation Module (BFAM) and a Temporal Fusion Module (TFM). BFAM leverages the frequency domain and MET to mitigate modal misalignment, while bidirectional flow aggregation and temporal fusion mechanisms resolve spatiotemporal misalignment. Experimental results on two large-scale datasets demonstrate that our framework significantly outperforms state-of-the-art RGB-Event semantic segmentation approaches. Our code is available at: https://github.com/zyaocoder/BRENet.
MobileInst: Video Instance Segmentation on the Mobile
Mar 30, 2023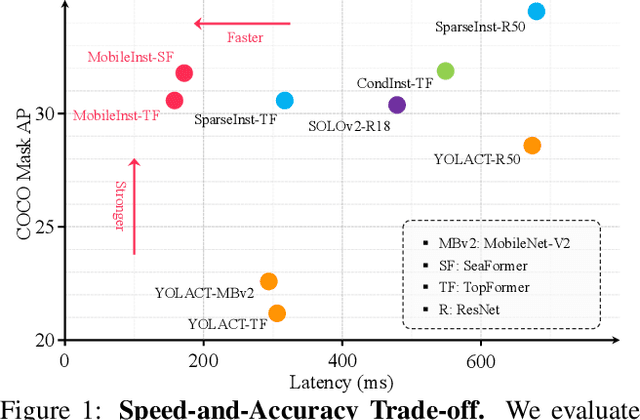
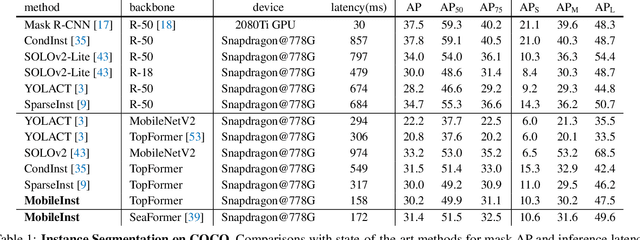

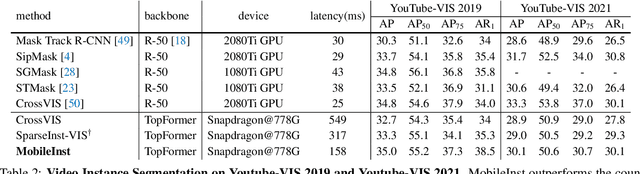
Although recent approaches aiming for video instance segmentation have achieved promising results, it is still difficult to employ those approaches for real-world applications on mobile devices, which mainly suffer from (1) heavy computation and memory cost and (2) complicated heuristics for tracking objects. To address those issues, we present MobileInst, a lightweight and mobile-friendly framework for video instance segmentation on mobile devices. Firstly, MobileInst adopts a mobile vision transformer to extract multi-level semantic features and presents an efficient query-based dual-transformer instance decoder for mask kernels and a semantic-enhanced mask decoder to generate instance segmentation per frame. Secondly, MobileInst exploits simple yet effective kernel reuse and kernel association to track objects for video instance segmentation. Further, we propose temporal query passing to enhance the tracking ability for kernels. We conduct experiments on COCO and YouTube-VIS datasets to demonstrate the superiority of MobileInst and evaluate the inference latency on a mobile CPU core of Qualcomm Snapdragon-778G, without other methods of acceleration. On the COCO dataset, MobileInst achieves 30.5 mask AP and 176 ms on the mobile CPU, which reduces the latency by 50% compared to the previous SOTA. For video instance segmentation, MobileInst achieves 35.0 AP on YouTube-VIS 2019 and 30.1 AP on YouTube-VIS 2021. Code will be available to facilitate real-world applications and future research.
GRIP: Graph-based Interaction-aware Trajectory Prediction
Jul 17, 2019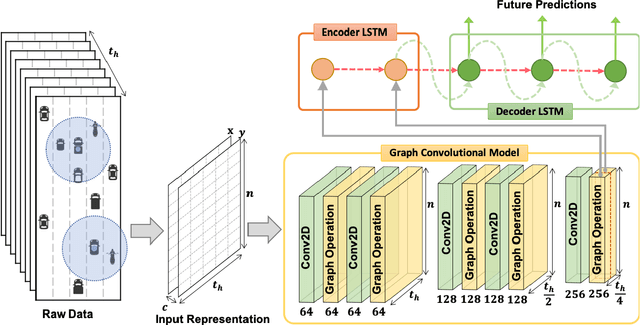
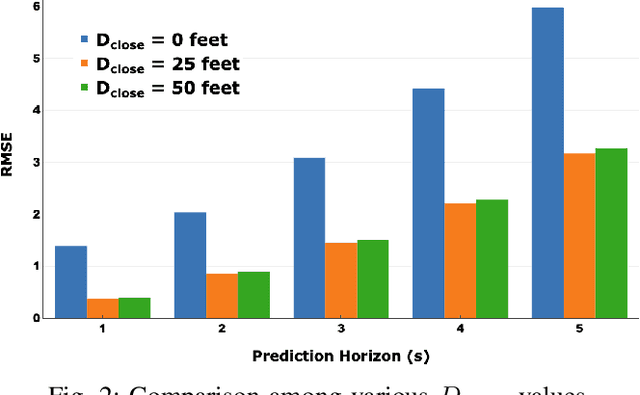
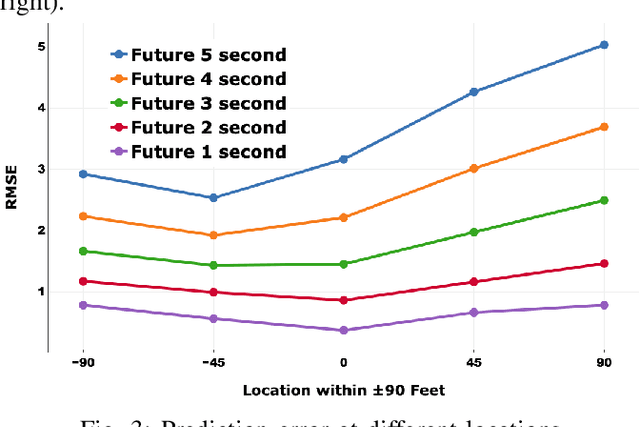
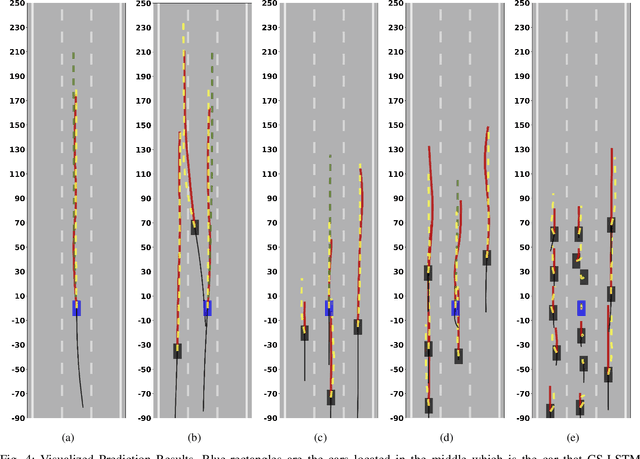
Nowadays, autonomous driving cars have become commercially available. However, the safety of a self-driving car is still a challenging problem that has not been well studied. Motion prediction is one of the core functions of an autonomous driving car. In this paper, we propose a novel scheme called GRIP which is designed to predict trajectories for traffic agents around an autonomous car efficiently. GRIP uses a graph to represent the interactions of close objects, applies several graph convolutional blocks to extract features, and subsequently uses an encoder-decoder long short-term memory (LSTM) model to make predictions. The experimental results on two well-known public datasets show that our proposed model improves the prediction accuracy of the state-of-the-art solution by 30%. The prediction error of GRIP is one meter shorter than existing schemes. Such an improvement can help autonomous driving cars avoid many traffic accidents. In addition, the proposed GRIP runs 5x faster than state-of-the-art schemes.