 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation of Winning Solutions of 2025 Low Power Computer Vision Challenge
Apr 22, 2026The IEEE Low-Power Computer Vision Challenge (LPCVC) aims to promote the development of efficient vision models for edge devices, balancing accuracy with constraints such as latency, memory capacity, and energy use. The 2025 challenge featured three tracks: (1) Image classification under various lighting conditions and styles, (2) Open-Vocabulary Segmentation with Text Prompt, and (3) Monocular Depth Estimation. This paper presents the design of LPCVC 2025, including its competition structure and evaluation framework, which integrates the Qualcomm AI Hub for consistent and reproducible benchmarking. The paper also introduces the top-performing solutions from each track and outlines key trends and observations. The paper concludes with suggestions for future computer vision competitions.
DiSa: Saliency-Aware Foreground-Background Disentangled Framework for Open-Vocabulary Semantic Segmentation
Jan 27, 2026Open-vocabulary semantic segmentation aims to assign labels to every pixel in an image based on text labels. Existing approaches typically utilize vision-language models (VLMs), such as CLIP, for dense prediction. However, VLMs, pre-trained on image-text pairs, are biased toward salient, object-centric regions and exhibit two critical limitations when adapted to segmentation: (i) Foreground Bias, which tends to ignore background regions, and (ii) Limited Spatial Localization, resulting in blurred object boundaries. To address these limitations, we introduce DiSa, a novel saliency-aware foreground-background disentangled framework. By explicitly incorporating saliency cues in our designed Saliency-aware Disentanglement Module (SDM), DiSa separately models foreground and background ensemble features in a divide-and-conquer manner. Additionally, we propose a Hierarchical Refinement Module (HRM) that leverages pixel-wise spatial contexts and enables channel-wise feature refinement through multi-level updates. Extensive experiments on six benchmarks demonstrate that DiSa consistently outperforms state-of-the-art methods.
Probabilistic Modeling of Spiking Neural Networks with Contract-Based Verification
Jun 16, 2025Spiking Neural Networks (SNN) are models for "realistic" neuronal computation, which makes them somehow different in scope from "ordinary" deep-learning models widely used in AI platforms nowadays. SNNs focus on timed latency (and possibly probability) of neuronal reactive activation/response, more than numerical computation of filters. So, an SNN model must provide modeling constructs for elementary neural bundles and then for synaptic connections to assemble them into compound data flow network patterns. These elements are to be parametric patterns, with latency and probability values instantiated on particular instances (while supposedly constant "at runtime"). Designers could also use different values to represent "tired" neurons, or ones impaired by external drugs, for instance. One important challenge in such modeling is to study how compound models could meet global reaction requirements (in stochastic timing challenges), provided similar provisions on individual neural bundles. A temporal language of logic to express such assume/guarantee contracts is thus needed. This may lead to formal verification on medium-sized models and testing observations on large ones. In the current article, we make preliminary progress at providing a simple model framework to express both elementary SNN neural bundles and their connecting constructs, which translates readily into both a model-checker and a simulator (both already existing and robust) to conduct experiments.
Rethinking RGB-Event Semantic Segmentation with a Novel Bidirectional Motion-enhanced Event Representation
May 02, 2025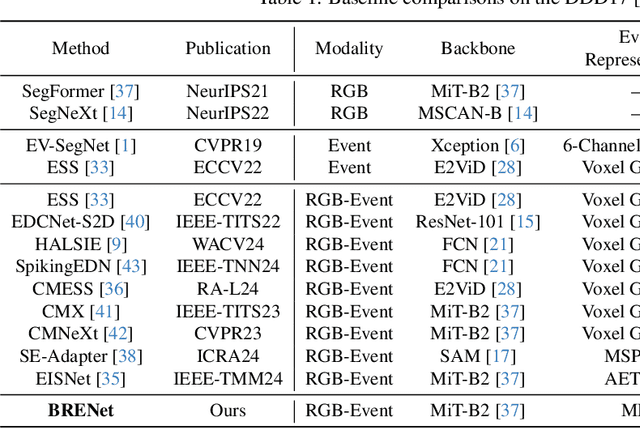
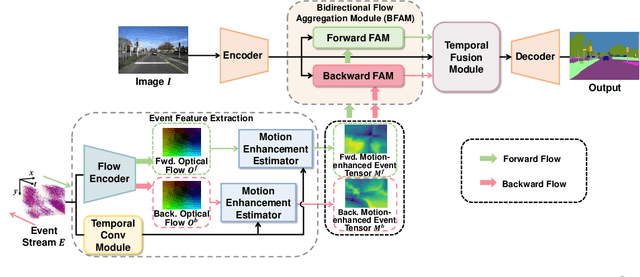
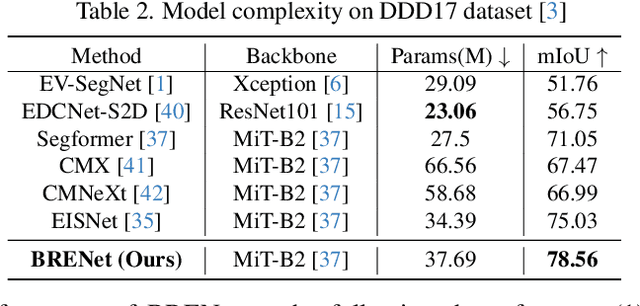
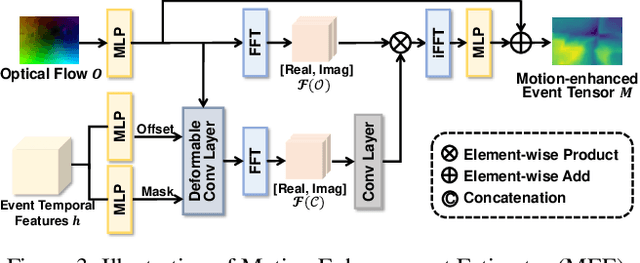
Event cameras capture motion dynamics, offering a unique modality with great potential in various computer vision tasks. However, RGB-Event fusion faces three intrinsic misalignments: (i) temporal, (ii) spatial, and (iii) modal misalignment. Existing voxel grid representations neglect temporal correlations between consecutive event windows, and their formulation with simple accumulation of asynchronous and sparse events is incompatible with the synchronous and dense nature of RGB modality. To tackle these challenges, we propose a novel event representation, Motion-enhanced Event Tensor (MET), which transforms sparse event voxels into a dense and temporally coherent form by leveraging dense optical flows and event temporal features. In addition, we introduce a Frequency-aware Bidirectional Flow Aggregation Module (BFAM) and a Temporal Fusion Module (TFM). BFAM leverages the frequency domain and MET to mitigate modal misalignment, while bidirectional flow aggregation and temporal fusion mechanisms resolve spatiotemporal misalignment. Experimental results on two large-scale datasets demonstrate that our framework significantly outperforms state-of-the-art RGB-Event semantic segmentation approaches. Our code is available at: https://github.com/zyaocoder/BRENet.
Event-guided Low-light Video Semantic Segmentation
Nov 01, 2024
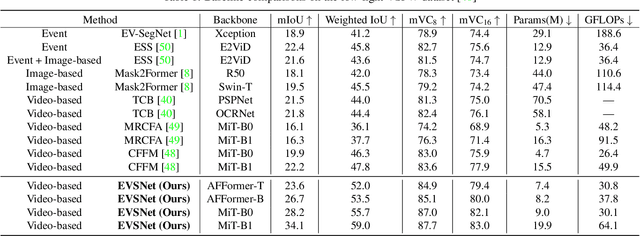
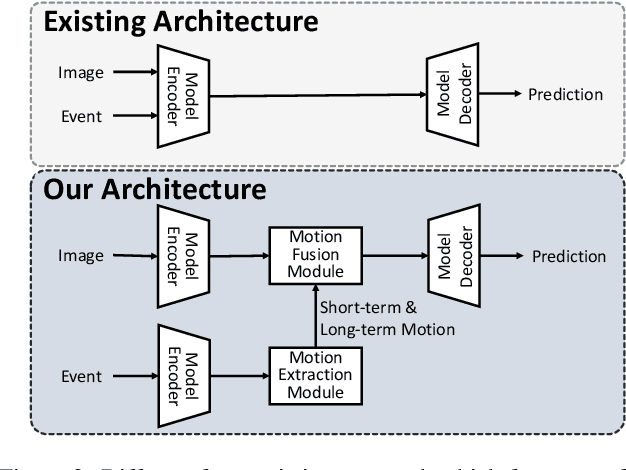
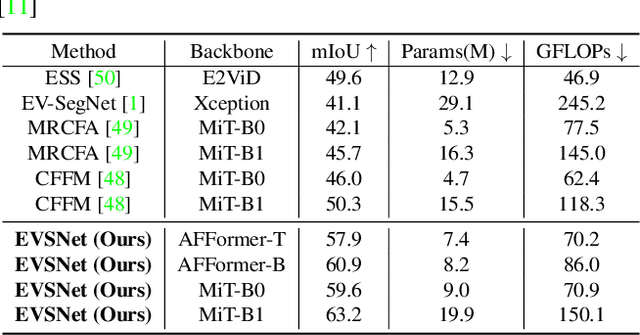
Recent video semantic segmentation (VSS) methods have demonstrated promising results in well-lit environments. However, their performance significantly drops in low-light scenarios due to limited visibility and reduced contextual details. In addition, unfavorable low-light conditions make it harder to incorporate temporal consistency across video frames and thus, lead to video flickering effects. Compared with conventional cameras, event cameras can capture motion dynamics, filter out temporal-redundant information, and are robust to lighting conditions. To this end, we propose EVSNet, a lightweight framework that leverages event modality to guide the learning of a unified illumination-invariant representation. Specifically, we leverage a Motion Extraction Module to extract short-term and long-term temporal motions from event modality and a Motion Fusion Module to integrate image features and motion features adaptively. Furthermore, we use a Temporal Decoder to exploit video contexts and generate segmentation predictions. Such designs in EVSNet result in a lightweight architecture while achieving SOTA performance. Experimental results on 3 large-scale datasets demonstrate our proposed EVSNet outperforms SOTA methods with up to 11x higher parameter efficiency.
Identification and Estimation of the Bi-Directional MR with Some Invalid Instruments
Jul 10, 2024



We consider the challenging problem of estimating causal effects from purely observational data in the bi-directional Mendelian randomization (MR), where some invalid instruments, as well as unmeasured confounding, usually exist. To address this problem, most existing methods attempt to find proper valid instrumental variables (IVs) for the target causal effect by expert knowledge or by assuming that the causal model is a one-directional MR model. As such, in this paper, we first theoretically investigate the identification of the bi-directional MR from observational data. In particular, we provide necessary and sufficient conditions under which valid IV sets are correctly identified such that the bi-directional MR model is identifiable, including the causal directions of a pair of phenotypes (i.e., the treatment and outcome). Moreover, based on the identification theory, we develop a cluster fusion-like method to discover valid IV sets and estimate the causal effects of interest. We theoretically demonstrate the correctness of the proposed algorithm. Experimental results show the effectiveness of our method for estimating causal effects in bi-directional MR.
SF-GNN: Self Filter for Message Lossless Propagation in Deep Graph Neural Network
Jul 03, 2024



Graph Neural Network (GNN), with the main idea of encoding graph structure information of graphs by propagation and aggregation, has developed rapidly. It achieved excellent performance in representation learning of multiple types of graphs such as homogeneous graphs, heterogeneous graphs, and more complex graphs like knowledge graphs. However, merely stacking GNN layers may not improve the model's performance and can even be detrimental. For the phenomenon of performance degradation in deep GNNs, we propose a new perspective. Unlike the popular explanations of over-smoothing or over-squashing, we think the issue arises from the interference of low-quality node representations during message propagation. We introduce a simple and general method, SF-GNN, to address this problem. In SF-GNN, we define two representations for each node, one is the node representation that represents the feature of the node itself, and the other is the message representation specifically for propagating messages to neighbor nodes. A self-filter module evaluates the quality of the node representation and decides whether to integrate it into the message propagation based on this quality assessment. Experiments on node classification tasks for both homogeneous and heterogeneous graphs, as well as link prediction tasks on knowledge graphs, demonstrate that our method can be applied to various GNN models and outperforms state-of-the-art baseline methods in addressing deep GNN degradation.
CrackNex: a Few-shot Low-light Crack Segmentation Model Based on Retinex Theory for UAV Inspections
Mar 05, 2024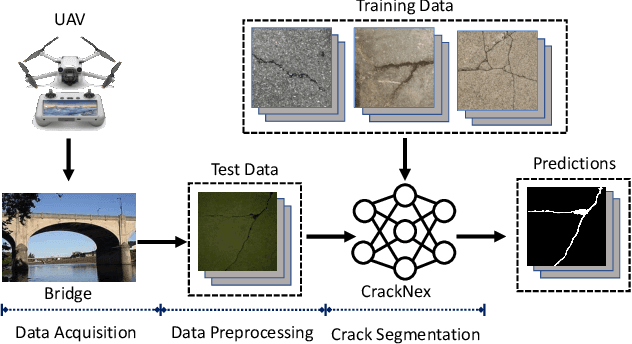
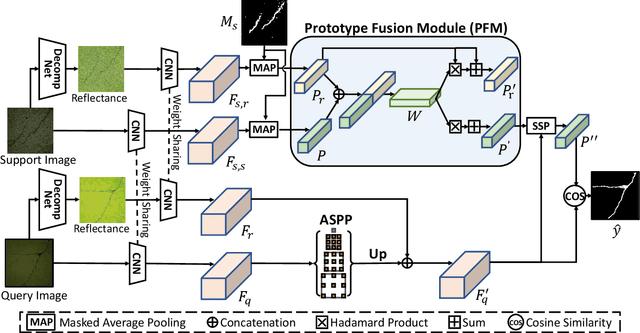
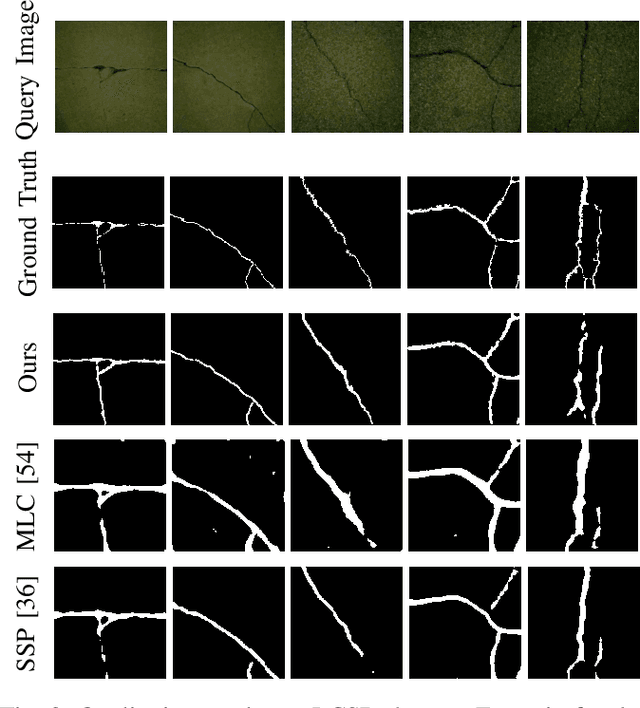

Routine visual inspections of concrete structures are imperative for upholding the safety and integrity of critical infrastructure. Such visual inspections sometimes happen under low-light conditions, e.g., checking for bridge health. Crack segmentation under such conditions is challenging due to the poor contrast between cracks and their surroundings. However, most deep learning methods are designed for well-illuminated crack images and hence their performance drops dramatically in low-light scenes. In addition, conventional approaches require many annotated low-light crack images which is time-consuming. In this paper, we address these challenges by proposing CrackNex, a framework that utilizes reflectance information based on Retinex Theory to help the model learn a unified illumination-invariant representation. Furthermore, we utilize few-shot segmentation to solve the inefficient training data problem. In CrackNex, both a support prototype and a reflectance prototype are extracted from the support set. Then, a prototype fusion module is designed to integrate the features from both prototypes. CrackNex outperforms the SOTA methods on multiple datasets. Additionally, we present the first benchmark dataset, LCSD, for low-light crack segmentation. LCSD consists of 102 well-illuminated crack images and 41 low-light crack images. The dataset and code are available at https://github.com/zy1296/CrackNex.
Negative Sampling with Adaptive Denoising Mixup for Knowledge Graph Embedding
Oct 15, 2023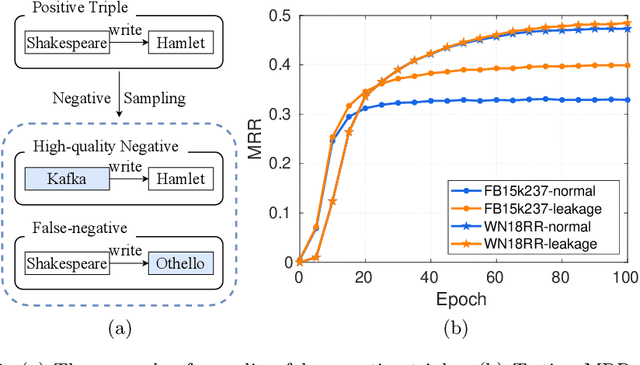

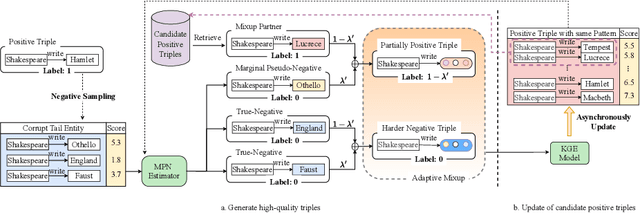
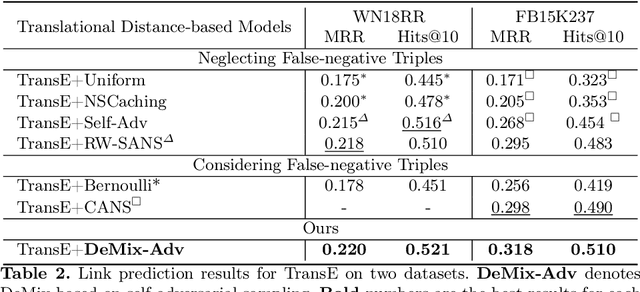
Knowledge graph embedding (KGE) aims to map entities and relations of a knowledge graph (KG) into a low-dimensional and dense vector space via contrasting the positive and negative triples. In the training process of KGEs, negative sampling is essential to find high-quality negative triples since KGs only contain positive triples. Most existing negative sampling methods assume that non-existent triples with high scores are high-quality negative triples. However, negative triples sampled by these methods are likely to contain noise. Specifically, they ignore that non-existent triples with high scores might also be true facts due to the incompleteness of KGs, which are usually called false negative triples. To alleviate the above issue, we propose an easily pluggable denoising mixup method called DeMix, which generates high-quality triples by refining sampled negative triples in a self-supervised manner. Given a sampled unlabeled triple, DeMix firstly classifies it into a marginal pseudo-negative triple or a negative triple based on the judgment of the KGE model itself. Secondly, it selects an appropriate mixup partner for the current triple to synthesize a partially positive or a harder negative triple. Experimental results on the knowledge graph completion task show that the proposed DeMix is superior to other negative sampling techniques, ensuring corresponding KGEs a faster convergence and better link prediction results.
A Comprehensive Study on Knowledge Graph Embedding over Relational Patterns Based on Rule Learning
Aug 15, 2023Knowledge Graph Embedding (KGE) has proven to be an effective approach to solving the Knowledge Graph Completion (KGC) task. Relational patterns which refer to relations with specific semantics exhibiting graph patterns are an important factor in the performance of KGE models. Though KGE models' capabilities are analyzed over different relational patterns in theory and a rough connection between better relational patterns modeling and better performance of KGC has been built, a comprehensive quantitative analysis on KGE models over relational patterns remains absent so it is uncertain how the theoretical support of KGE to a relational pattern contributes to the performance of triples associated to such a relational pattern. To address this challenge, we evaluate the performance of 7 KGE models over 4 common relational patterns on 2 benchmarks, then conduct an analysis in theory, entity frequency, and part-to-whole three aspects and get some counterintuitive conclusions. Finally, we introduce a training-free method Score-based Patterns Adaptation (SPA) to enhance KGE models' performance over various relational patterns. This approach is simple yet effective and can be applied to KGE models without additional training. Our experimental results demonstrate that our method generally enhances performance over specific relational patterns. Our source code is available from GitHub at https://github.com/zjukg/Comprehensive-Study-over-Relational-Patterns.