 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvent-guided Low-light Video Semantic Segmentation
Paper and Code
Nov 01, 2024
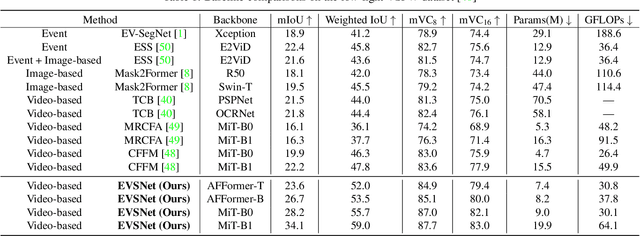
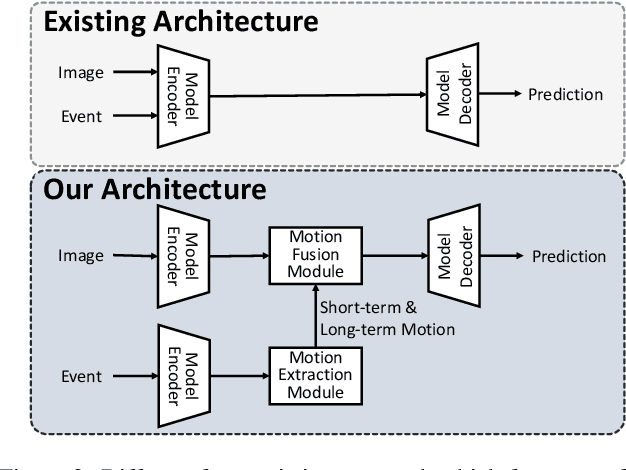
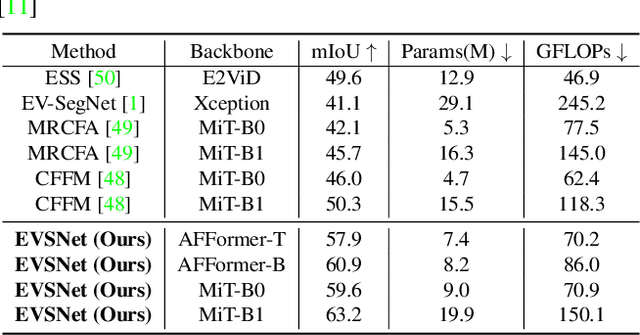
Recent video semantic segmentation (VSS) methods have demonstrated promising results in well-lit environments. However, their performance significantly drops in low-light scenarios due to limited visibility and reduced contextual details. In addition, unfavorable low-light conditions make it harder to incorporate temporal consistency across video frames and thus, lead to video flickering effects. Compared with conventional cameras, event cameras can capture motion dynamics, filter out temporal-redundant information, and are robust to lighting conditions. To this end, we propose EVSNet, a lightweight framework that leverages event modality to guide the learning of a unified illumination-invariant representation. Specifically, we leverage a Motion Extraction Module to extract short-term and long-term temporal motions from event modality and a Motion Fusion Module to integrate image features and motion features adaptively. Furthermore, we use a Temporal Decoder to exploit video contexts and generate segmentation predictions. Such designs in EVSNet result in a lightweight architecture while achieving SOTA performance. Experimental results on 3 large-scale datasets demonstrate our proposed EVSNet outperforms SOTA methods with up to 11x higher parameter efficiency.