 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCRAFTQA: A Code-Driven Adaptive Framework for Complex Structured Data Reasoning
Jun 01, 2026Real-world scenarios involve massive heterogeneous structured data (e.g., tables, knowledge graphs), making effective reasoning over such diverse data increasingly important. Unified structured data question answering has emerged as a prominent research trend, aiming to answer natural language questions across different structured data types within a single framework. However, existing unified methods share a common limitation: they rely on a set of predefined functions, which restricts their ability to perform complex reasoning beyond these predefined operations. To overcome this fundamental limitation, we propose CRAFTQA, a novel adaptive code-driven framework comprising two core modules, CodeSTEP and CRAFT. The CodeSTEP module is a paradigm that generates a complete executable Python code sequence, which contains step-by-step code-based reasoning operations based on the question. The CRAFT module dynamically generates custom code functions for operations beyond the predefined function set, and seamlessly integrates with CodeSTEP to significantly enhance flexibility in handling complex reasoning. Comprehensive experiments on multiple structured datasets demonstrate that CRAFTQA achieves remarkable improvements in complex reasoning scenarios compared to existing unified methods.
Self-Correction Distillation for Structured Data Question Answering
Nov 17, 2025Structured data question answering (QA), including table QA, Knowledge Graph (KG) QA, and temporal KG QA, is a pivotal research area. Advances in large language models (LLMs) have driven significant progress in unified structural QA frameworks like TrustUQA. However, these frameworks face challenges when applied to small-scale LLMs since small-scale LLMs are prone to errors in generating structured queries. To improve the structured data QA ability of small-scale LLMs, we propose a self-correction distillation (SCD) method. In SCD, an error prompt mechanism (EPM) is designed to detect errors and provide customized error messages during inference, and a two-stage distillation strategy is designed to transfer large-scale LLMs' query-generation and error-correction capabilities to small-scale LLM. Experiments across 5 benchmarks with 3 structured data types demonstrate that our SCD achieves the best performance and superior generalization on small-scale LLM (8B) compared to other distillation methods, and closely approaches the performance of GPT4 on some datasets. Furthermore, large-scale LLMs equipped with EPM surpass the state-of-the-art results on most datasets.
A Method for Enhancing Generalization of Adam by Multiple Integrations
Dec 17, 2024



The insufficient generalization of adaptive moment estimation (Adam) has hindered its broader application. Recent studies have shown that flat minima in loss landscapes are highly associated with improved generalization. Inspired by the filtering effect of integration operations on high-frequency signals, we propose multiple integral Adam (MIAdam), a novel optimizer that integrates a multiple integral term into Adam. This multiple integral term effectively filters out sharp minima encountered during optimization, guiding the optimizer towards flatter regions and thereby enhancing generalization capability. We provide a theoretical explanation for the improvement in generalization through the diffusion theory framework and analyze the impact of the multiple integral term on the optimizer's convergence. Experimental results demonstrate that MIAdam not only enhances generalization and robustness against label noise but also maintains the rapid convergence characteristic of Adam, outperforming Adam and its variants in state-of-the-art benchmarks.
STAR: A Simple Training-free Approach for Recommendations using Large Language Models
Oct 21, 2024Recent progress in large language models (LLMs) offers promising new approaches for recommendation system (RecSys) tasks. While the current state-of-the-art methods rely on fine-tuning LLMs to achieve optimal results, this process is costly and introduces significant engineering complexities. Conversely, methods that bypass fine-tuning and use LLMs directly are less resource-intensive but often fail to fully capture both semantic and collaborative information, resulting in sub-optimal performance compared to their fine-tuned counterparts. In this paper, we propose a Simple Training-free Approach for Recommendation (STAR), a framework that utilizes LLMs and can be applied to various recommendation tasks without the need for fine-tuning. Our approach involves a retrieval stage that uses semantic embeddings from LLMs combined with collaborative user information to retrieve candidate items. We then apply an LLM for pairwise ranking to enhance next-item prediction. Experimental results on the Amazon Review dataset show competitive performance for next item prediction, even with our retrieval stage alone. Our full method achieves Hits@10 performance of +23.8% on Beauty, +37.5% on Toys and Games, and -1.8% on Sports and Outdoors relative to the best supervised models. This framework offers an effective alternative to traditional supervised models, highlighting the potential of LLMs in recommendation systems without extensive training or custom architectures.
Leveraging LLM Reasoning Enhances Personalized Recommender Systems
Jul 22, 2024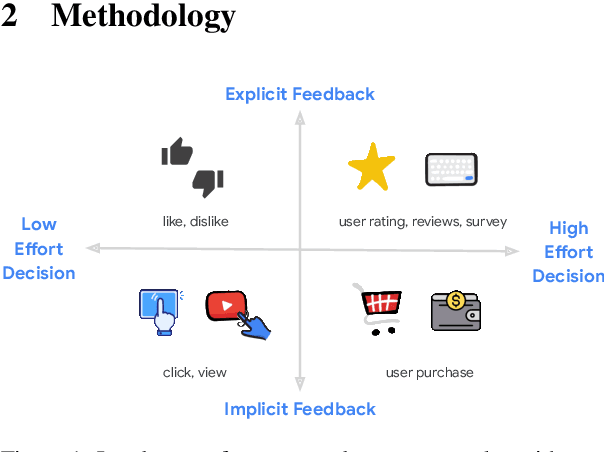



Recent advancements have showcased the potential of Large Language Models (LLMs) in executing reasoning tasks, particularly facilitated by Chain-of-Thought (CoT) prompting. While tasks like arithmetic reasoning involve clear, definitive answers and logical chains of thought, the application of LLM reasoning in recommendation systems (RecSys) presents a distinct challenge. RecSys tasks revolve around subjectivity and personalized preferences, an under-explored domain in utilizing LLMs' reasoning capabilities. Our study explores several aspects to better understand reasoning for RecSys and demonstrate how task quality improves by utilizing LLM reasoning in both zero-shot and finetuning settings. Additionally, we propose RecSAVER (Recommender Systems Automatic Verification and Evaluation of Reasoning) to automatically assess the quality of LLM reasoning responses without the requirement of curated gold references or human raters. We show that our framework aligns with real human judgment on the coherence and faithfulness of reasoning responses. Overall, our work shows that incorporating reasoning into RecSys can improve personalized tasks, paving the way for further advancements in recommender system methodologies.
TrustUQA: A Trustful Framework for Unified Structured Data Question Answering
Jun 27, 2024



Natural language question answering (QA) over structured data sources such as tables and knowledge graphs (KGs) have been widely investigated, for example with Large Language Models (LLMs). The main solutions include question to formal query parsing and retrieval-based answer generation. However, current methods of the former often suffer from weak generalization, failing to dealing with multiple sources simultaneously, while the later is limited in trustfulness. In this paper, we propose UnifiedTQA, a trustful QA framework that can simultaneously support multiple types of structured data in a unified way. To this end, it adopts an LLM-friendly and unified knowledge representation method called Condition Graph (CG), and uses an LLM and demonstration-based two-level method for CG querying. For enhancement, it is also equipped with dynamic demonstration retrieval. We have evaluated UnifiedTQA with 5 benchmarks covering 3 types of structured data. It outperforms 2 existing unified structured data QA methods and in comparison with the baselines that are specific to a data type, it achieves state-of-the-art on 2 of them. Further more, we demonstrates potential of our method for more general QA tasks, QA over mixed structured data and QA across structured data.
NodeMixup: Tackling Under-Reaching for Graph Neural Networks
Dec 21, 2023Graph Neural Networks (GNNs) have become mainstream methods for solving the semi-supervised node classification problem. However, due to the uneven location distribution of labeled nodes in the graph, labeled nodes are only accessible to a small portion of unlabeled nodes, leading to the \emph{under-reaching} issue. In this study, we firstly reveal under-reaching by conducting an empirical investigation on various well-known graphs. Then, we demonstrate that under-reaching results in unsatisfactory distribution alignment between labeled and unlabeled nodes through systematic experimental analysis, significantly degrading GNNs' performance. To tackle under-reaching for GNNs, we propose an architecture-agnostic method dubbed NodeMixup. The fundamental idea is to (1) increase the reachability of labeled nodes by labeled-unlabeled pairs mixup, (2) leverage graph structures via fusing the neighbor connections of intra-class node pairs to improve performance gains of mixup, and (3) use neighbor label distribution similarity incorporating node degrees to determine sampling weights for node mixup. Extensive experiments demonstrate the efficacy of NodeMixup in assisting GNNs in handling under-reaching. The source code is available at \url{https://github.com/WeigangLu/NodeMixup}.
Hiformer: Heterogeneous Feature Interactions Learning with Transformers for Recommender Systems
Nov 10, 2023



Learning feature interaction is the critical backbone to building recommender systems. In web-scale applications, learning feature interaction is extremely challenging due to the sparse and large input feature space; meanwhile, manually crafting effective feature interactions is infeasible because of the exponential solution space. We propose to leverage a Transformer-based architecture with attention layers to automatically capture feature interactions. Transformer architectures have witnessed great success in many domains, such as natural language processing and computer vision. However, there has not been much adoption of Transformer architecture for feature interaction modeling in industry. We aim at closing the gap. We identify two key challenges for applying the vanilla Transformer architecture to web-scale recommender systems: (1) Transformer architecture fails to capture the heterogeneous feature interactions in the self-attention layer; (2) The serving latency of Transformer architecture might be too high to be deployed in web-scale recommender systems. We first propose a heterogeneous self-attention layer, which is a simple yet effective modification to the self-attention layer in Transformer, to take into account the heterogeneity of feature interactions. We then introduce \textsc{Hiformer} (\textbf{H}eterogeneous \textbf{I}nteraction Trans\textbf{former}) to further improve the model expressiveness. With low-rank approximation and model pruning, \hiformer enjoys fast inference for online deployment. Extensive offline experiment results corroborates the effectiveness and efficiency of the \textsc{Hiformer} model. We have successfully deployed the \textsc{Hiformer} model to a real world large scale App ranking model at Google Play, with significant improvement in key engagement metrics (up to +2.66\%).
Reliable Academic Conference Question Answering: A Study Based on Large Language Model
Oct 19, 2023



The rapid growth of computer science has led to a proliferation of research presented at academic conferences, fostering global scholarly communication. Researchers consistently seek accurate, current information about these events at all stages. This data surge necessitates an intelligent question-answering system to efficiently address researchers' queries and ensure awareness of the latest advancements. The information of conferences is usually published on their official website, organized in a semi-structured way with a lot of text. To address this need, we have developed the ConferenceQA dataset for 7 diverse academic conferences with human annotations. Firstly, we employ a combination of manual and automated methods to organize academic conference data in a semi-structured JSON format. Subsequently, we annotate nearly 100 question-answer pairs for each conference. Each pair is classified into four different dimensions. To ensure the reliability of the data, we manually annotate the source of each answer. In light of recent advancements, Large Language Models (LLMs) have demonstrated impressive performance in various NLP tasks. They have demonstrated impressive capabilities in information-seeking question answering after instruction fine-tuning, and as such, we present our conference QA study based on LLM. Due to hallucination and outdated knowledge of LLMs, we adopt retrieval based methods to enhance LLMs' question-answering abilities. We have proposed a structure-aware retrieval method, specifically designed to leverage inherent structural information during the retrieval process. Empirical validation on the ConferenceQA dataset has demonstrated the effectiveness of this method. The dataset and code are readily accessible on https://github.com/zjukg/ConferenceQA.
Asymmetric Co-Training with Explainable Cell Graph Ensembling for Histopathological Image Classification
Aug 24, 2023



Convolutional neural networks excel in histopathological image classification, yet their pixel-level focus hampers explainability. Conversely, emerging graph convolutional networks spotlight cell-level features and medical implications. However, limited by their shallowness and suboptimal use of high-dimensional pixel data, GCNs underperform in multi-class histopathological image classification. To make full use of pixel-level and cell-level features dynamically, we propose an asymmetric co-training framework combining a deep graph convolutional network and a convolutional neural network for multi-class histopathological image classification. To improve the explainability of the entire framework by embedding morphological and topological distribution of cells, we build a 14-layer deep graph convolutional network to handle cell graph data. For the further utilization and dynamic interactions between pixel-level and cell-level information, we also design a co-training strategy to integrate the two asymmetric branches. Notably, we collect a private clinically acquired dataset termed LUAD7C, including seven subtypes of lung adenocarcinoma, which is rare and more challenging. We evaluated our approach on the private LUAD7C and public colorectal cancer datasets, showcasing its superior performance, explainability, and generalizability in multi-class histopathological image classification.