 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSKA-Bench: A Fine-Grained Benchmark for Evaluating Structured Knowledge Understanding of LLMs
Jul 23, 2025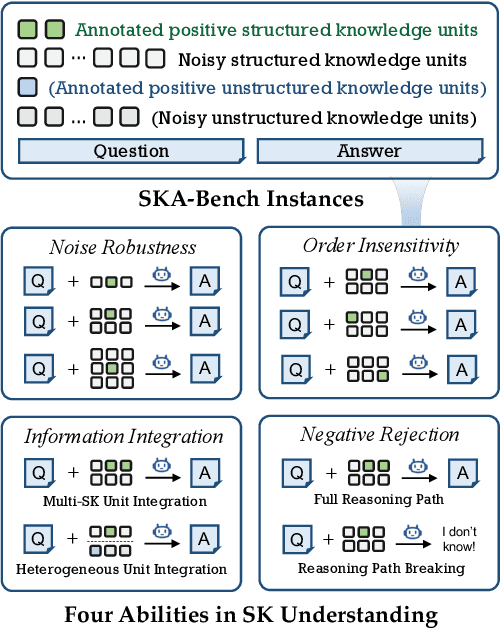

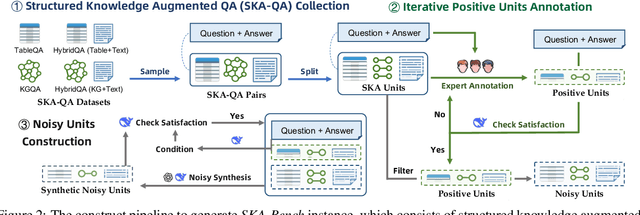
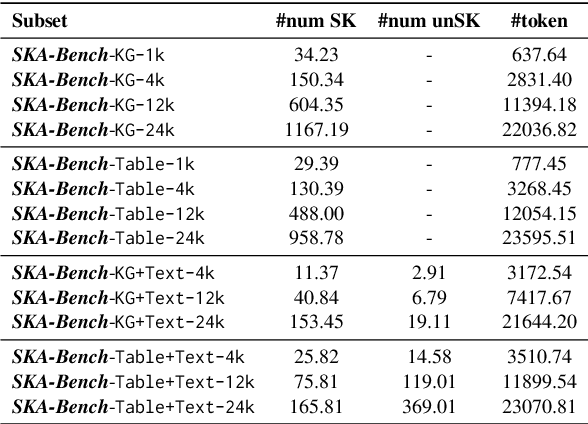
Although large language models (LLMs) have made significant progress in understanding Structured Knowledge (SK) like KG and Table, existing evaluations for SK understanding are non-rigorous (i.e., lacking evaluations of specific capabilities) and focus on a single type of SK. Therefore, we aim to propose a more comprehensive and rigorous structured knowledge understanding benchmark to diagnose the shortcomings of LLMs. In this paper, we introduce SKA-Bench, a Structured Knowledge Augmented QA Benchmark that encompasses four widely used structured knowledge forms: KG, Table, KG+Text, and Table+Text. We utilize a three-stage pipeline to construct SKA-Bench instances, which includes a question, an answer, positive knowledge units, and noisy knowledge units. To evaluate the SK understanding capabilities of LLMs in a fine-grained manner, we expand the instances into four fundamental ability testbeds: Noise Robustness, Order Insensitivity, Information Integration, and Negative Rejection. Empirical evaluations on 8 representative LLMs, including the advanced DeepSeek-R1, indicate that existing LLMs still face significant challenges in understanding structured knowledge, and their performance is influenced by factors such as the amount of noise, the order of knowledge units, and hallucination phenomenon. Our dataset and code are available at https://github.com/Lza12a/SKA-Bench.
Beyond Completion: A Foundation Model for General Knowledge Graph Reasoning
May 28, 2025In natural language processing (NLP) and computer vision (CV), the successful application of foundation models across diverse tasks has demonstrated their remarkable potential. However, despite the rich structural and textual information embedded in knowledge graphs (KGs), existing research of foundation model for KG has primarily focused on their structural aspects, with most efforts restricted to in-KG tasks (e.g., knowledge graph completion, KGC). This limitation has hindered progress in addressing more challenging out-of-KG tasks. In this paper, we introduce MERRY, a foundation model for general knowledge graph reasoning, and investigate its performance across two task categories: in-KG reasoning tasks (e.g., KGC) and out-of-KG tasks (e.g., KG question answering, KGQA). We not only utilize the structural information, but also the textual information in KGs. Specifically, we propose a multi-perspective Conditional Message Passing (CMP) encoding architecture to bridge the gap between textual and structural modalities, enabling their seamless integration. Additionally, we introduce a dynamic residual fusion module to selectively retain relevant textual information and a flexible edge scoring mechanism to adapt to diverse downstream tasks. Comprehensive evaluations on 28 datasets demonstrate that MERRY outperforms existing baselines in most scenarios, showcasing strong reasoning capabilities within KGs and excellent generalization to out-of-KG tasks such as KGQA.
UniHR: Hierarchical Representation Learning for Unified Knowledge Graph Link Prediction
Nov 11, 2024
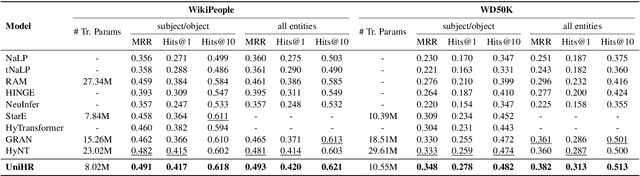
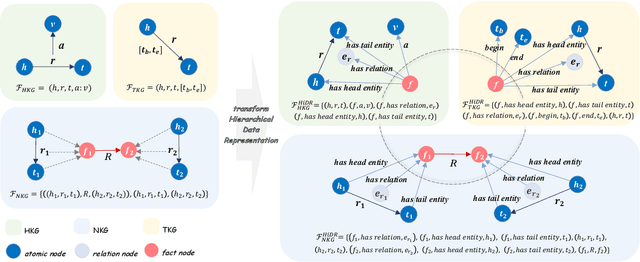
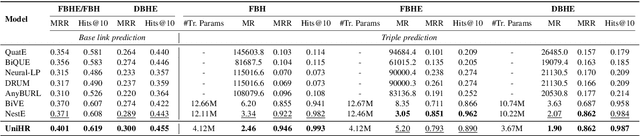
Beyond-triple fact representations including hyper-relational facts with auxiliary key-value pairs, temporal facts with additional timestamps, and nested facts implying relationships between facts, are gaining significant attention. However, existing link prediction models are usually designed for one specific type of facts, making it difficult to generalize to other fact representations. To overcome this limitation, we propose a Unified Hierarchical Representation learning framework (UniHR) for unified knowledge graph link prediction. It consists of a unified Hierarchical Data Representation (HiDR) module and a unified Hierarchical Structure Learning (HiSL) module as graph encoder. The HiDR module unifies hyper-relational KGs, temporal KGs, and nested factual KGs into triple-based representations. Then HiSL incorporates intra-fact and inter-fact message passing, focusing on enhancing the semantic information within individual facts and enriching the structural information between facts. Experimental results across 7 datasets from 3 types of KGs demonstrate that our UniHR outperforms baselines designed for one specific kind of KG, indicating strong generalization capability of HiDR form and the effectiveness of HiSL module. Code and data are available at https://github.com/Lza12a/UniHR.
TrustUQA: A Trustful Framework for Unified Structured Data Question Answering
Jun 27, 2024



Natural language question answering (QA) over structured data sources such as tables and knowledge graphs (KGs) have been widely investigated, for example with Large Language Models (LLMs). The main solutions include question to formal query parsing and retrieval-based answer generation. However, current methods of the former often suffer from weak generalization, failing to dealing with multiple sources simultaneously, while the later is limited in trustfulness. In this paper, we propose UnifiedTQA, a trustful QA framework that can simultaneously support multiple types of structured data in a unified way. To this end, it adopts an LLM-friendly and unified knowledge representation method called Condition Graph (CG), and uses an LLM and demonstration-based two-level method for CG querying. For enhancement, it is also equipped with dynamic demonstration retrieval. We have evaluated UnifiedTQA with 5 benchmarks covering 3 types of structured data. It outperforms 2 existing unified structured data QA methods and in comparison with the baselines that are specific to a data type, it achieves state-of-the-art on 2 of them. Further more, we demonstrates potential of our method for more general QA tasks, QA over mixed structured data and QA across structured data.
Reliable Academic Conference Question Answering: A Study Based on Large Language Model
Oct 19, 2023



The rapid growth of computer science has led to a proliferation of research presented at academic conferences, fostering global scholarly communication. Researchers consistently seek accurate, current information about these events at all stages. This data surge necessitates an intelligent question-answering system to efficiently address researchers' queries and ensure awareness of the latest advancements. The information of conferences is usually published on their official website, organized in a semi-structured way with a lot of text. To address this need, we have developed the ConferenceQA dataset for 7 diverse academic conferences with human annotations. Firstly, we employ a combination of manual and automated methods to organize academic conference data in a semi-structured JSON format. Subsequently, we annotate nearly 100 question-answer pairs for each conference. Each pair is classified into four different dimensions. To ensure the reliability of the data, we manually annotate the source of each answer. In light of recent advancements, Large Language Models (LLMs) have demonstrated impressive performance in various NLP tasks. They have demonstrated impressive capabilities in information-seeking question answering after instruction fine-tuning, and as such, we present our conference QA study based on LLM. Due to hallucination and outdated knowledge of LLMs, we adopt retrieval based methods to enhance LLMs' question-answering abilities. We have proposed a structure-aware retrieval method, specifically designed to leverage inherent structural information during the retrieval process. Empirical validation on the ConferenceQA dataset has demonstrated the effectiveness of this method. The dataset and code are readily accessible on https://github.com/zjukg/ConferenceQA.