 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAggregation Queries over Unstructured Text: Benchmark and Agentic Method
Feb 03, 2026Aggregation query over free text is a long-standing yet underexplored problem. Unlike ordinary question answering, aggregate queries require exhaustive evidence collection and systems are required to "find all," not merely "find one." Existing paradigms such as Text-to-SQL and Retrieval-Augmented Generation fail to achieve this completeness. In this work, we formalize entity-level aggregation querying over text in a corpus-bounded setting with strict completeness requirement. To enable principled evaluation, we introduce AGGBench, a benchmark designed to evaluate completeness-oriented aggregation under realistic large-scale corpus. To accompany the benchmark, we propose DFA (Disambiguation--Filtering--Aggregation), a modular agentic baseline that decomposes aggregation querying into interpretable stages and exposes key failure modes related to ambiguity, filtering, and aggregation. Empirical results show that DFA consistently improves aggregation evidence coverage over strong RAG and agentic baselines. The data and code are available in \href{https://anonymous.4open.science/r/DFA-A4C1}.
LogicScore: Fine-grained Logic Evaluation of Conciseness, Completeness, and Determinateness in Attributed Question Answering
Jan 22, 2026Current evaluation methods for Attributed Question Answering (AQA) suffer from \textit{attribution myopia}: they emphasize verification of isolated statements and their attributions but overlook the global logical integrity of long-form answers. Consequently, Large Language Models (LLMs) often produce factually grounded yet logically incoherent responses with elusive deductive gaps. To mitigate this limitation, we present \textsc{LogicScore}, a unified evaluation framework that shifts the paradigm from local assessment to global reasoning scrutiny. Grounded in Horn Rules, our approach integrates a backward verification mechanism to systematically evaluate three key reasoning dimensions: \textit{Completeness} (logically sound deduction), \textit{Conciseness} (non-redundancy), and \textit{Determinateness} (consistent answer entailment). Extensive experiments across three multi-hop QA datasets (HotpotQA, MusiQue, and 2WikiMultiHopQA) and over 20 LLMs (including GPT-5, Gemini-3-Pro, LLaMA3, and task-specific tuned models) reveal a critical capability gap: leading models often achieve high attribution scores (e.g., 92.85\% precision for Gemini-3 Pro) but struggle with global reasoning quality (e.g., 35.11\% Conciseness for Gemini-3 Pro). Our work establishes a robust standard for logical evaluation, highlighting the need to prioritize reasoning coherence alongside factual grounding in LLM development. Codes are available at: https://github.com/zhichaoyan11/LogicScore.
\textsc{LogicScore}: Fine-grained Logic Evaluation of Conciseness, Completeness, and Determinateness in Attributed Question Answering
Jan 21, 2026Current evaluation methods for Attributed Question Answering (AQA) suffer from \textit{attribution myopia}: they emphasize verification of isolated statements and their attributions but overlook the global logical integrity of long-form answers. Consequently, Large Language Models (LLMs) often produce factually grounded yet logically incoherent responses with elusive deductive gaps. To mitigate this limitation, we present \textsc{LogicScore}, a unified evaluation framework that shifts the paradigm from local assessment to global reasoning scrutiny. Grounded in Horn Rules, our approach integrates a backward verification mechanism to systematically evaluate three key reasoning dimensions: \textit{Completeness} (logically sound deduction), \textit{Conciseness} (non-redundancy), and \textit{Determinateness} (consistent answer entailment). Extensive experiments across three multi-hop QA datasets (HotpotQA, MusiQue, and 2WikiMultiHopQA) and over 20 LLMs (including GPT-5, Gemini-3-Pro, LLaMA3, and task-specific tuned models) reveal a critical capability gap: leading models often achieve high attribution scores (e.g., 92.85\% precision for Gemini-3 Pro) but struggle with global reasoning quality (e.g., 35.11\% Conciseness for Gemini-3 Pro). Our work establishes a robust standard for logical evaluation, highlighting the need to prioritize reasoning coherence alongside factual grounding in LLM development. Codes are available at: https://github.com/zhichaoyan11/LogicScore.
Large Language Model for OWL Proofs
Jan 18, 2026The ability of Large Language Models (LLMs) to perform reasoning tasks such as deduction has been widely investigated in recent years. Yet, their capacity to generate proofs-faithful, human-readable explanations of why conclusions follow-remains largely under explored. In this work, we study proof generation in the context of OWL ontologies, which are widely adopted for representing and reasoning over complex knowledge, by developing an automated dataset construction and evaluation framework. Our evaluation encompassing three sequential tasks for complete proving: Extraction, Simplification, and Explanation, as well as an additional task of assessing Logic Completeness of the premise. Through extensive experiments on widely used reasoning LLMs, we achieve important findings including: (1) Some models achieve overall strong results but remain limited on complex cases; (2) Logical complexity, rather than representation format (formal logic language versus natural language), is the dominant factor shaping LLM performance; and (3) Noise and incompleteness in input data substantially diminish LLMs' performance. Together, these results underscore both the promise of LLMs for explanation with rigorous logics and the gap of supporting resilient reasoning under complex or imperfect conditions. Code and data are available at https://github.com/HuiYang1997/LLMOwlR.
GR-Agent: Adaptive Graph Reasoning Agent under Incomplete Knowledge
Dec 16, 2025

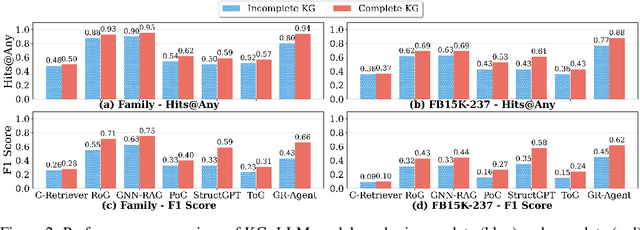

Large language models (LLMs) achieve strong results on knowledge graph question answering (KGQA), but most benchmarks assume complete knowledge graphs (KGs) where direct supporting triples exist. This reduces evaluation to shallow retrieval and overlooks the reality of incomplete KGs, where many facts are missing and answers must be inferred from existing facts. We bridge this gap by proposing a methodology for constructing benchmarks under KG incompleteness, which removes direct supporting triples while ensuring that alternative reasoning paths required to infer the answer remain. Experiments on benchmarks constructed using our methodology show that existing methods suffer consistent performance degradation under incompleteness, highlighting their limited reasoning ability. To overcome this limitation, we present the Adaptive Graph Reasoning Agent (GR-Agent). It first constructs an interactive environment from the KG, and then formalizes KGQA as agent environment interaction within this environment. GR-Agent operates over an action space comprising graph reasoning tools and maintains a memory of potential supporting reasoning evidence, including relevant relations and reasoning paths. Extensive experiments demonstrate that GR-Agent outperforms non-training baselines and performs comparably to training-based methods under both complete and incomplete settings.
Schema Inference for Tabular Data Repositories Using Large Language Models
Sep 04, 2025Minimally curated tabular data often contain representational inconsistencies across heterogeneous sources, and are accompanied by sparse metadata. Working with such data is intimidating. While prior work has advanced dataset discovery and exploration, schema inference remains difficult when metadata are limited. We present SI-LLM (Schema Inference using Large Language Models), which infers a concise conceptual schema for tabular data using only column headers and cell values. The inferred schema comprises hierarchical entity types, attributes, and inter-type relationships. In extensive evaluation on two datasets from web tables and open data, SI-LLM achieves promising end-to-end results, as well as better or comparable results to state-of-the-art methods at each step. All source code, full prompts, and datasets of SI-LLM are available at https://github.com/PierreWoL/SILLM.
What Breaks Knowledge Graph based RAG? Empirical Insights into Reasoning under Incomplete Knowledge
Aug 11, 2025Knowledge Graph-based Retrieval-Augmented Generation (KG-RAG) is an increasingly explored approach for combining the reasoning capabilities of large language models with the structured evidence of knowledge graphs. However, current evaluation practices fall short: existing benchmarks often include questions that can be directly answered using existing triples in KG, making it unclear whether models perform reasoning or simply retrieve answers directly. Moreover, inconsistent evaluation metrics and lenient answer matching criteria further obscure meaningful comparisons. In this work, we introduce a general method for constructing benchmarks, together with an evaluation protocol, to systematically assess KG-RAG methods under knowledge incompleteness. Our empirical results show that current KG-RAG methods have limited reasoning ability under missing knowledge, often rely on internal memorization, and exhibit varying degrees of generalization depending on their design.
Ontology-Enhanced Knowledge Graph Completion using Large Language Models
Jul 28, 2025Large Language Models (LLMs) have been extensively adopted in Knowledge Graph Completion (KGC), showcasing significant research advancements. However, as black-box models driven by deep neural architectures, current LLM-based KGC methods rely on implicit knowledge representation with parallel propagation of erroneous knowledge, thereby hindering their ability to produce conclusive and decisive reasoning outcomes. We aim to integrate neural-perceptual structural information with ontological knowledge, leveraging the powerful capabilities of LLMs to achieve a deeper understanding of the intrinsic logic of the knowledge. We propose an ontology enhanced KGC method using LLMs -- OL-KGC. It first leverages neural perceptual mechanisms to effectively embed structural information into the textual space, and then uses an automated extraction algorithm to retrieve ontological knowledge from the knowledge graphs (KGs) that needs to be completed, which is further transformed into a textual format comprehensible to LLMs for providing logic guidance. We conducted extensive experiments on three widely-used benchmarks -- FB15K-237, UMLS and WN18RR. The experimental results demonstrate that OL-KGC significantly outperforms existing mainstream KGC methods across multiple evaluation metrics, achieving state-of-the-art performance.
Multi-modal Knowledge Graph Generation with Semantics-enriched Prompts
Apr 18, 2025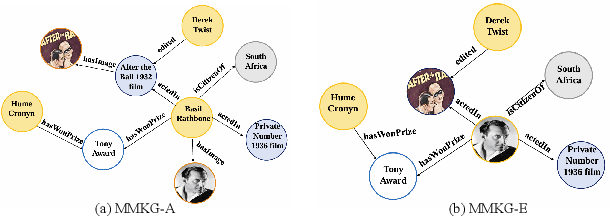
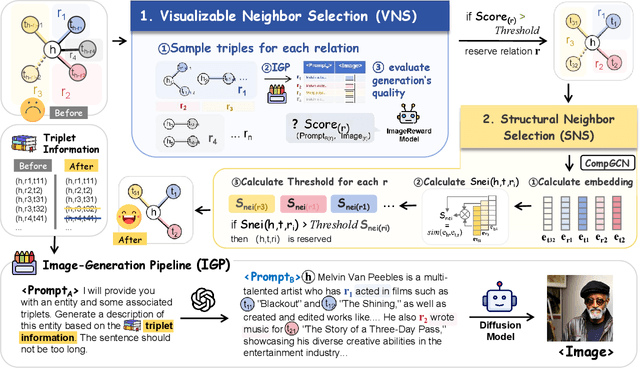
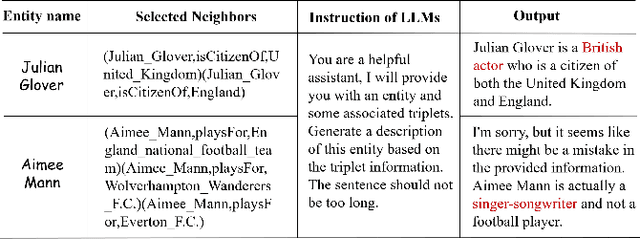

Multi-modal Knowledge Graphs (MMKGs) have been widely applied across various domains for knowledge representation. However, the existing MMKGs are significantly fewer than required, and their construction faces numerous challenges, particularly in ensuring the selection of high-quality, contextually relevant images for knowledge graph enrichment. To address these challenges, we present a framework for constructing MMKGs from conventional KGs. Furthermore, to generate higher-quality images that are more relevant to the context in the given knowledge graph, we designed a neighbor selection method called Visualizable Structural Neighbor Selection (VSNS). This method consists of two modules: Visualizable Neighbor Selection (VNS) and Structural Neighbor Selection (SNS). The VNS module filters relations that are difficult to visualize, while the SNS module selects neighbors that most effectively capture the structural characteristics of the entity. To evaluate the quality of the generated images, we performed qualitative and quantitative evaluations on two datasets, MKG-Y and DB15K. The experimental results indicate that using the VSNS method to select neighbors results in higher-quality images that are more relevant to the knowledge graph.
Evaluating Knowledge Graph Based Retrieval Augmented Generation Methods under Knowledge Incompleteness
Apr 07, 2025

Knowledge Graph based Retrieval-Augmented Generation (KG-RAG) is a technique that enhances Large Language Model (LLM) inference in tasks like Question Answering (QA) by retrieving relevant information from knowledge graphs (KGs). However, real-world KGs are often incomplete, meaning that essential information for answering questions may be missing. Existing benchmarks do not adequately capture the impact of KG incompleteness on KG-RAG performance. In this paper, we systematically evaluate KG-RAG methods under incomplete KGs by removing triples using different methods and analyzing the resulting effects. We demonstrate that KG-RAG methods are sensitive to KG incompleteness, highlighting the need for more robust approaches in realistic settings.