 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Discourse Cohesion in Pre-trained Language Models
Mar 08, 2025
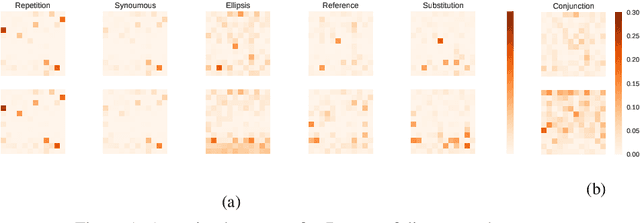
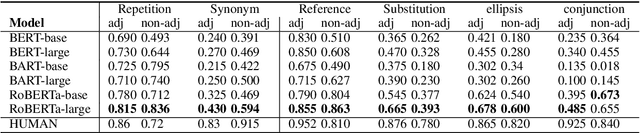

Large pre-trained neural models have achieved remarkable success in natural language process (NLP), inspiring a growing body of research analyzing their ability from different aspects. In this paper, we propose a test suite to evaluate the cohesive ability of pre-trained language models. The test suite contains multiple cohesion phenomena between adjacent and non-adjacent sentences. We try to compare different pre-trained language models on these phenomena and analyze the experimental results,hoping more attention can be given to discourse cohesion in the future.
Evaluating and Improving Graph to Text Generation with Large Language Models
Jan 24, 2025Large language models (LLMs) have demonstrated immense potential across various tasks. However, research for exploring and improving the capabilities of LLMs in interpreting graph structures remains limited. To address this gap, we conduct a comprehensive evaluation of prompting current open-source LLMs on graph-to-text generation tasks. Although we explored the optimal prompting strategies and proposed a novel and effective diversity-difficulty-based few-shot sample selection method, we found that the improvements from tuning-free approaches were incremental, as LLMs struggle with planning on complex graphs, particularly those with a larger number of triplets. To further improve LLMs in planning with graph sequences and grounding in truth, we introduce a new graph-to-text dataset, PlanGTG, annotated with two sub-tasks: reordering and attribution. Through extensive automatic and human evaluations, we demonstrate significant improvements in the quality of generated text from both few-shot learning and fine-tuning perspectives using the PlanGTG dataset. Our study paves the way for new research directions in graph-to-text generation. PlanGTG datasets can be found in https://github.com/probe2/kg_text.
MINTQA: A Multi-Hop Question Answering Benchmark for Evaluating LLMs on New and Tail Knowledge
Dec 22, 2024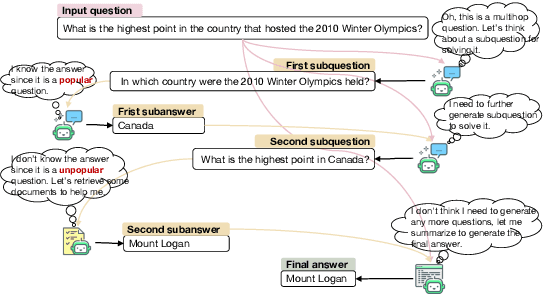
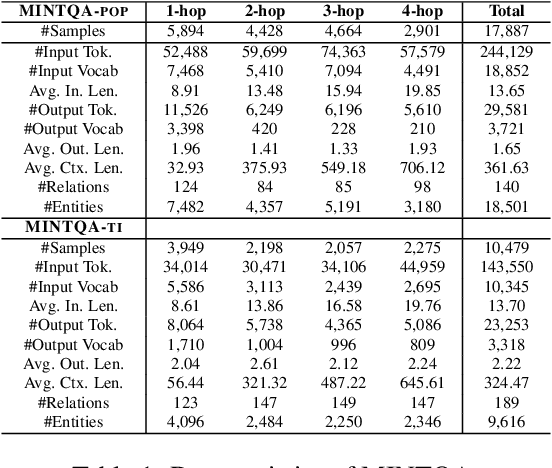
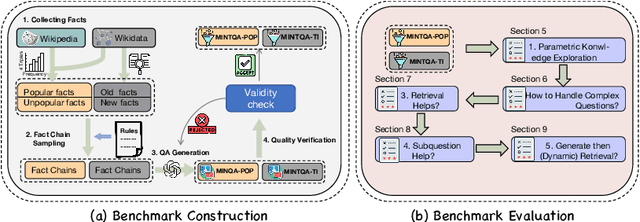
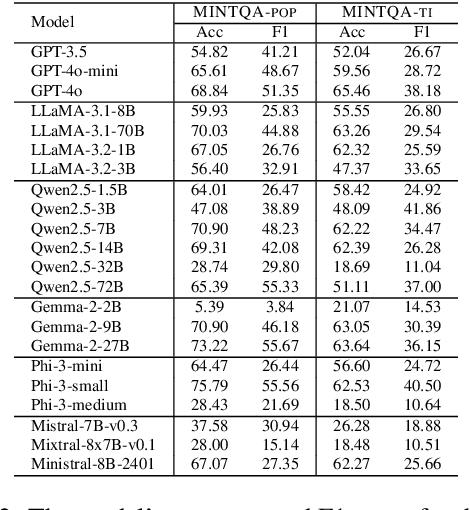
Large language models (LLMs) have demonstrated impressive capabilities in various reasoning tasks but face significant challenges with complex, knowledge-intensive multi-hop queries, particularly those involving new or long-tail knowledge. Existing benchmarks often fail to fully address these challenges. To bridge this gap, we introduce MINTQA (Multi-hop Question Answering on New and Tail Knowledge), a comprehensive benchmark to evaluate LLMs' capabilities in multi-hop reasoning across four critical dimensions: question handling strategy, sub-question generation, retrieval-augmented generation, and iterative or dynamic decomposition and retrieval. MINTQA comprises 10,479 question-answer pairs for evaluating new knowledge and 17,887 pairs for assessing long-tail knowledge, with each question equipped with corresponding sub-questions and answers. Our systematic evaluation of 22 state-of-the-art LLMs on MINTQA reveals significant limitations in their ability to handle complex knowledge base queries, particularly in handling new or unpopular knowledge. Our findings highlight critical challenges and offer insights for advancing multi-hop reasoning capabilities. The MINTQA benchmark is available at https://github.com/probe2/multi-hop/.
Leveraging Hierarchical Prototypes as the Verbalizer for Implicit Discourse Relation Recognition
Nov 22, 2024Implicit discourse relation recognition involves determining relationships that hold between spans of text that are not linked by an explicit discourse connective. In recent years, the pre-train, prompt, and predict paradigm has emerged as a promising approach for tackling this task. However, previous work solely relied on manual verbalizers for implicit discourse relation recognition, which suffer from issues of ambiguity and even incorrectness. To overcome these limitations, we leverage the prototypes that capture certain class-level semantic features and the hierarchical label structure for different classes as the verbalizer. We show that our method improves on competitive baselines. Besides, our proposed approach can be extended to enable zero-shot cross-lingual learning, facilitating the recognition of discourse relations in languages with scarce resources. These advancement validate the practicality and versatility of our approach in addressing the issues of implicit discourse relation recognition across different languages.
Multi-Label Classification for Implicit Discourse Relation Recognition
Jun 06, 2024Discourse relations play a pivotal role in establishing coherence within textual content, uniting sentences and clauses into a cohesive narrative. The Penn Discourse Treebank (PDTB) stands as one of the most extensively utilized datasets in this domain. In PDTB-3, the annotators can assign multiple labels to an example, when they believe that multiple relations are present. Prior research in discourse relation recognition has treated these instances as separate examples during training, and only one example needs to have its label predicted correctly for the instance to be judged as correct. However, this approach is inadequate, as it fails to account for the interdependence of labels in real-world contexts and to distinguish between cases where only one sense relation holds and cases where multiple relations hold simultaneously. In our work, we address this challenge by exploring various multi-label classification frameworks to handle implicit discourse relation recognition. We show that multi-label classification methods don't depress performance for single-label prediction. Additionally, we give comprehensive analysis of results and data. Our work contributes to advancing the understanding and application of discourse relations and provide a foundation for the future study
Facilitating Contrastive Learning of Discourse Relational Senses by Exploiting the Hierarchy of Sense Relations
Jan 06, 2023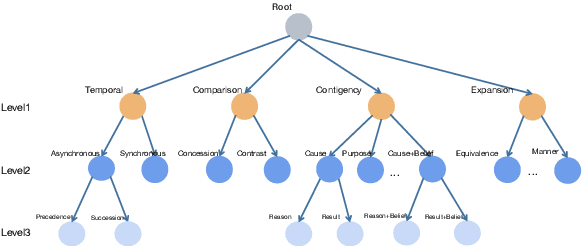
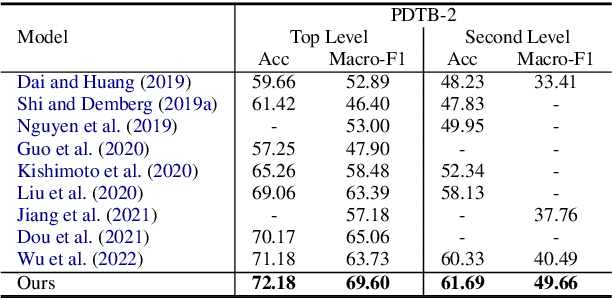
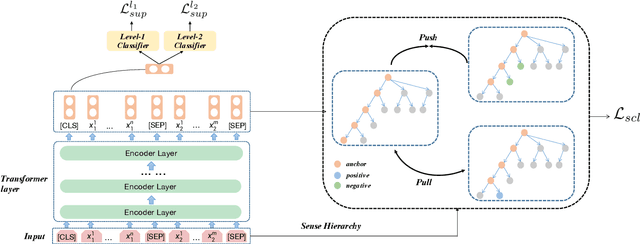
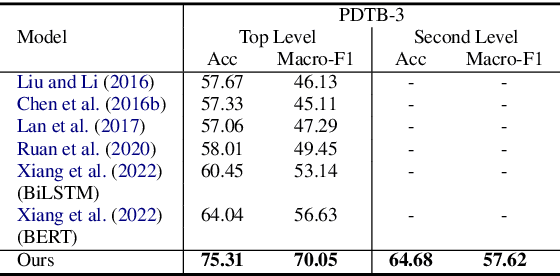
Implicit discourse relation recognition is a challenging task that involves identifying the sense or senses that hold between two adjacent spans of text, in the absence of an explicit connective between them. In both PDTB-2 and PDTB-3, discourse relational senses are organized into a three-level hierarchy ranging from four broad top-level senses, to more specific senses below them. Most previous work on implicit discourse relation recognition have used the sense hierarchy simply to indicate what sense labels were available. Here we do more -- incorporating the sense hierarchy into the recognition process itself and using it to select the negative examples used in contrastive learning. With no additional effort, the approach achieves state-of-the-art performance on the task.
Shallow Discourse Annotation for Chinese TED Talks
Apr 06, 2020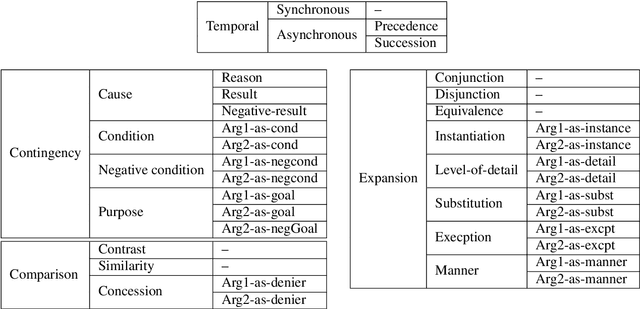
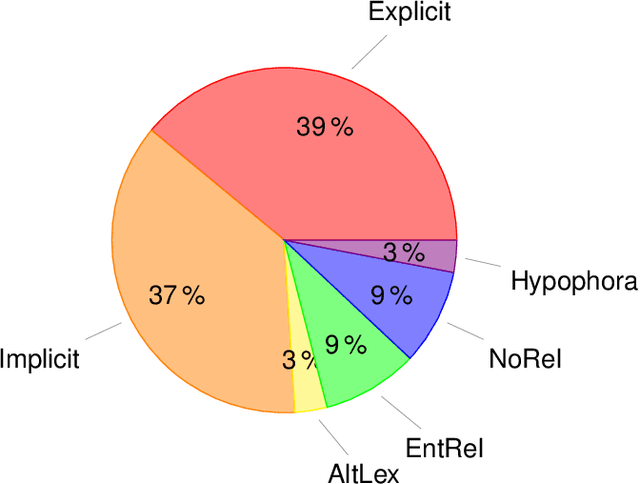
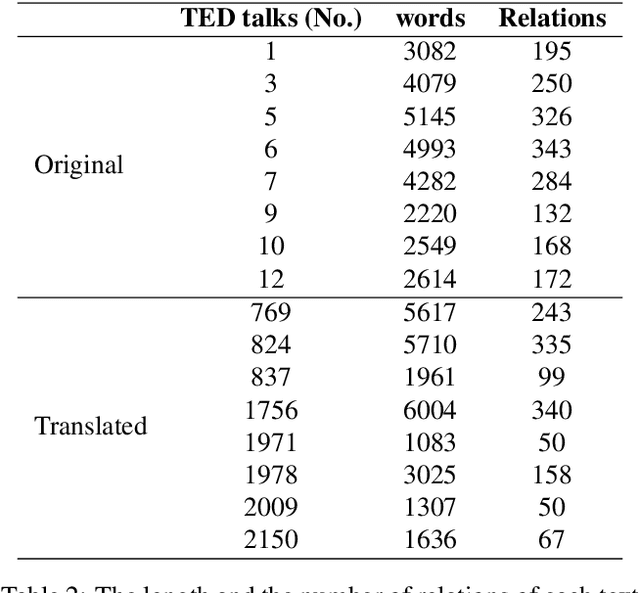
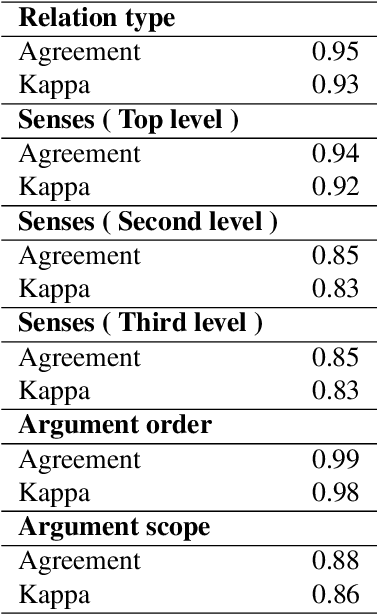
Text corpora annotated with language-related properties are an important resource for the development of Language Technology. The current work contributes a new resource for Chinese Language Technology and for Chinese-English translation, in the form of a set of TED talks (some originally given in English, some in Chinese) that have been annotated with discourse relations in the style of the Penn Discourse TreeBank, adapted to properties of Chinese text that are not present in English. The resource is currently unique in annotating discourse-level properties of planned spoken monologues rather than of written text. An inter-annotator agreement study demonstrates that the annotation scheme is able to achieve highly reliable results.