 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowRL: Boosting LLM Reasoning via Reinforcement Learning with Minimal-Sufficient Knowledge Guidance
Apr 14, 2026RLVR improves reasoning in large language models, but its effectiveness is often limited by severe reward sparsity on hard problems. Recent hint-based RL methods mitigate sparsity by injecting partial solutions or abstract templates, yet they typically scale guidance by adding more tokens, which introduce redundancy, inconsistency, and extra training overhead. We propose \textbf{KnowRL} (Knowledge-Guided Reinforcement Learning), an RL training framework that treats hint design as a minimal-sufficient guidance problem. During RL training, KnowRL decomposes guidance into atomic knowledge points (KPs) and uses Constrained Subset Search (CSS) to construct compact, interaction-aware subsets for training. We further identify a pruning interaction paradox -- removing one KP may help while removing multiple such KPs can hurt -- and explicitly optimize for robust subset curation under this dependency structure. We train KnowRL-Nemotron-1.5B from OpenMath-Nemotron-1.5B. Across eight reasoning benchmarks at the 1.5B scale, KnowRL-Nemotron-1.5B consistently outperforms strong RL and hinting baselines. Without KP hints at inference, KnowRL-Nemotron-1.5B reaches 70.08 average accuracy, already surpassing Nemotron-1.5B by +9.63 points; with selected KPs, performance improves to 74.16, establishing a new state of the art at this scale. The model, curated training data, and code are publicly available at https://github.com/Hasuer/KnowRL.
DEP: A Decentralized Large Language Model Evaluation Protocol
Mar 01, 2026With the rapid development of Large Language Models (LLMs), a large number of benchmarks have been proposed. However, most benchmarks lack unified evaluation standard and require the manual implementation of custom scripts, making results hard to ensure consistency and reproducibility. Furthermore, mainstream evaluation frameworks are centralized, with datasets and answers, which increases the risk of benchmark leakage. To address these issues, we propose a Decentralized Evaluation Protocol (DEP), a decentralized yet unified and standardized evaluation framework through a matching server without constraining benchmarks. The server can be mounted locally or deployed remotely, and once adapted, it can be reused over the long term. By decoupling users, LLMs, and benchmarks, DEP enables modular, plug-and-play evaluation: benchmark files and evaluation logic stay exclusively on the server side. In remote setting, users cannot access the ground truth, thereby achieving data isolation and leak-proof evaluation. To facilitate practical adoption, we develop DEP Toolkit, a protocol-compatible toolkit that supports features such as breakpoint resume, concurrent requests, and congestion control. We also provide detailed documentation for adapting new benchmarks to DEP. Using DEP toolkit, we evaluate multiple LLMs across benchmarks. Experimental results verify the effectiveness of DEP and show that it reduces the cost of deploying benchmark evaluations. As of February 2026, we have adapted over 60 benchmarks and continue to promote community co-construction to support unified evaluation across various tasks and domains.
SOUP: Token-level Single-sample Mix-policy Reinforcement Learning for Large Language Models
Jan 29, 2026On-policy reinforcement learning (RL) methods widely used for language model post-training, like Group Relative Policy Optimization (GRPO), often suffer from limited exploration and early saturation due to low sampling diversity. While off-policy data can help, current approaches that mix entire trajectories cause significant policy mismatch and instability. In this work, we propose the $\textbf{S}$ingle-sample Mix-p$\textbf{O}$licy $\textbf{U}$nified $\textbf{P}$aradigm (SOUP), a framework that unifies off- and on-policy learning within individual samples at the token level. It confines off-policy influence to the prefix of a generated sequence sampled from historical policies, while the continuation is generated on-policy. Through token-level importance ratios, SOUP effectively leverages off-policy information while preserving training stability. Extensive experiments demonstrate that SOUP consistently outperforms standard on-policy training and existing off-policy extensions. Our further analysis clarifies how our fine-grained, single-sample mix-policy training can improve both exploration and final performance in LLM RL.
Finding the Translation Switch: Discovering and Exploiting the Task-Initiation Features in LLMs
Jan 16, 2026Large Language Models (LLMs) frequently exhibit strong translation abilities, even without task-specific fine-tuning. However, the internal mechanisms governing this innate capability remain largely opaque. To demystify this process, we leverage Sparse Autoencoders (SAEs) and introduce a novel framework for identifying task-specific features. Our method first recalls features that are frequently co-activated on translation inputs and then filters them for functional coherence using a PCA-based consistency metric. This framework successfully isolates a small set of **translation initiation** features. Causal interventions demonstrate that amplifying these features steers the model towards correct translation, while ablating them induces hallucinations and off-task outputs, confirming they represent a core component of the model's innate translation competency. Moving from analysis to application, we leverage this mechanistic insight to propose a new data selection strategy for efficient fine-tuning. Specifically, we prioritize training on **mechanistically hard** samples-those that fail to naturally activate the translation initiation features. Experiments show this approach significantly improves data efficiency and suppresses hallucinations. Furthermore, we find these mechanisms are transferable to larger models of the same family. Our work not only decodes a core component of the translation mechanism in LLMs but also provides a blueprint for using internal model mechanism to create more robust and efficient models. The codes are available at https://github.com/flamewei123/AAAI26-translation-Initiation-Features.
Revisiting Entropy in Reinforcement Learning for Large Reasoning Models
Nov 08, 2025Reinforcement learning with verifiable rewards (RLVR) has emerged as a predominant approach for enhancing the reasoning capabilities of large language models (LLMs). However, the entropy of LLMs usually collapses during RLVR training, causing premature convergence to suboptimal local minima and hinder further performance improvement. Although various approaches have been proposed to mitigate entropy collapse, a comprehensive study of entropy in RLVR remains lacking. To address this gap, we conduct extensive experiments to investigate the entropy dynamics of LLMs trained with RLVR and analyze how model entropy correlates with response diversity, calibration, and performance across various benchmarks. Our findings reveal that the number of off-policy updates, the diversity of training data, and the clipping thresholds in the optimization objective are critical factors influencing the entropy of LLMs trained with RLVR. Moreover, we theoretically and empirically demonstrate that tokens with positive advantages are the primary contributors to entropy collapse, and that model entropy can be effectively regulated by adjusting the relative loss weights of tokens with positive and negative advantages during training.
Evaluating Multimodal Large Language Models on Video Captioning via Monte Carlo Tree Search
Jun 11, 2025Video captioning can be used to assess the video understanding capabilities of Multimodal Large Language Models (MLLMs). However, existing benchmarks and evaluation protocols suffer from crucial issues, such as inadequate or homogeneous creation of key points, exorbitant cost of data creation, and limited evaluation scopes. To address these issues, we propose an automatic framework, named AutoCaption, which leverages Monte Carlo Tree Search (MCTS) to construct numerous and diverse descriptive sentences (\textit{i.e.}, key points) that thoroughly represent video content in an iterative way. This iterative captioning strategy enables the continuous enhancement of video details such as actions, objects' attributes, environment details, etc. We apply AutoCaption to curate MCTS-VCB, a fine-grained video caption benchmark covering video details, thereby enabling a comprehensive evaluation of MLLMs on the video captioning task. We evaluate more than 20 open- and closed-source MLLMs of varying sizes on MCTS-VCB. Results show that MCTS-VCB can effectively and comprehensively evaluate the video captioning capability, with Gemini-1.5-Pro achieving the highest F1 score of 71.2. Interestingly, we fine-tune InternVL2.5-8B with the AutoCaption-generated data, which helps the model achieve an overall improvement of 25.0% on MCTS-VCB and 16.3% on DREAM-1K, further demonstrating the effectiveness of AutoCaption. The code and data are available at https://github.com/tjunlp-lab/MCTS-VCB.
FuxiMT: Sparsifying Large Language Models for Chinese-Centric Multilingual Machine Translation
May 20, 2025In this paper, we present FuxiMT, a novel Chinese-centric multilingual machine translation model powered by a sparsified large language model (LLM). We adopt a two-stage strategy to train FuxiMT. We first pre-train the model on a massive Chinese corpus and then conduct multilingual fine-tuning on a large parallel dataset encompassing 65 languages. FuxiMT incorporates Mixture-of-Experts (MoEs) and employs a curriculum learning strategy for robust performance across various resource levels. Experimental results demonstrate that FuxiMT significantly outperforms strong baselines, including state-of-the-art LLMs and machine translation models, particularly under low-resource scenarios. Furthermore, FuxiMT exhibits remarkable zero-shot translation capabilities for unseen language pairs, indicating its potential to bridge communication gaps where parallel data are scarce or unavailable.
AdaST: Dynamically Adapting Encoder States in the Decoder for End-to-End Speech-to-Text Translation
Mar 18, 2025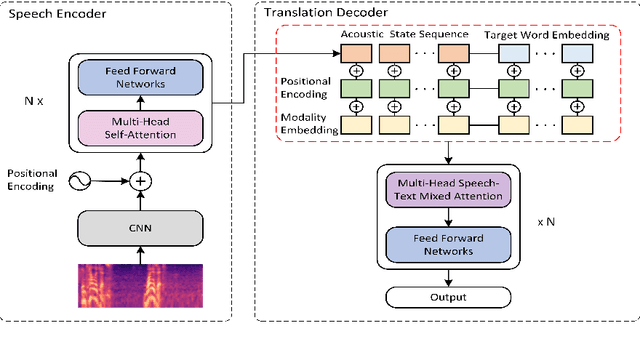

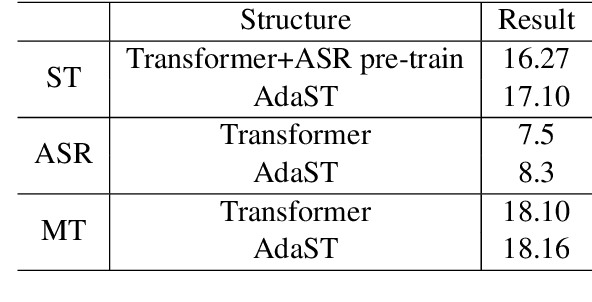

In end-to-end speech translation, acoustic representations learned by the encoder are usually fixed and static, from the perspective of the decoder, which is not desirable for dealing with the cross-modal and cross-lingual challenge in speech translation. In this paper, we show the benefits of varying acoustic states according to decoder hidden states and propose an adaptive speech-to-text translation model that is able to dynamically adapt acoustic states in the decoder. We concatenate the acoustic state and target word embedding sequence and feed the concatenated sequence into subsequent blocks in the decoder. In order to model the deep interaction between acoustic states and target hidden states, a speech-text mixed attention sublayer is introduced to replace the conventional cross-attention network. Experiment results on two widely-used datasets show that the proposed method significantly outperforms state-of-the-art neural speech translation models.
Joint Training And Decoding for Multilingual End-to-End Simultaneous Speech Translation
Mar 14, 2025Recent studies on end-to-end speech translation(ST) have facilitated the exploration of multilingual end-to-end ST and end-to-end simultaneous ST. In this paper, we investigate end-to-end simultaneous speech translation in a one-to-many multilingual setting which is closer to applications in real scenarios. We explore a separate decoder architecture and a unified architecture for joint synchronous training in this scenario. To further explore knowledge transfer across languages, we propose an asynchronous training strategy on the proposed unified decoder architecture. A multi-way aligned multilingual end-to-end ST dataset was curated as a benchmark testbed to evaluate our methods. Experimental results demonstrate the effectiveness of our models on the collected dataset. Our codes and data are available at: https://github.com/XiaoMi/TED-MMST.
N2C2: Nearest Neighbor Enhanced Confidence Calibration for Cross-Lingual In-Context Learning
Mar 12, 2025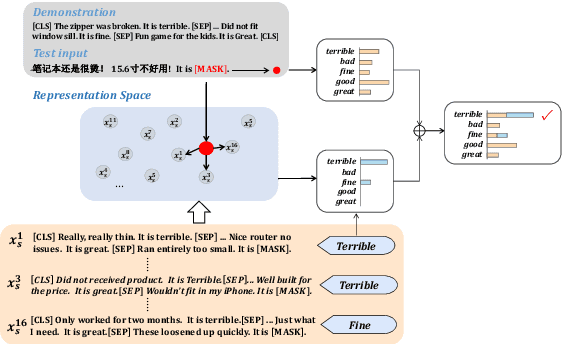
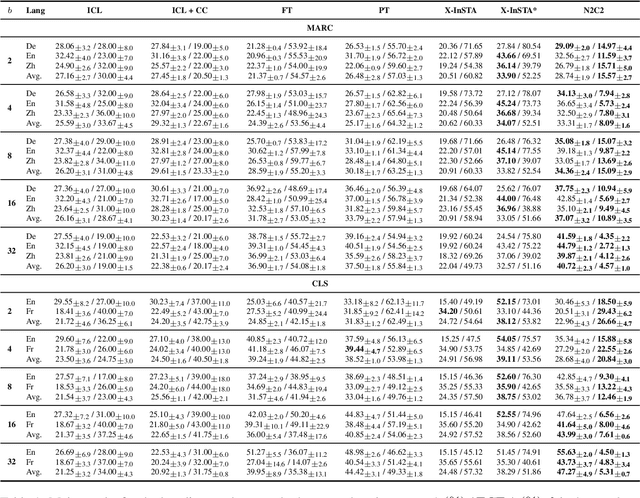
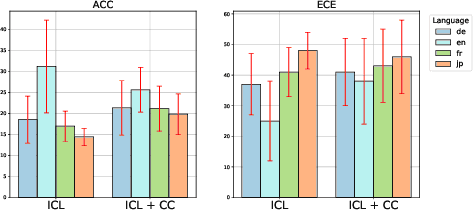
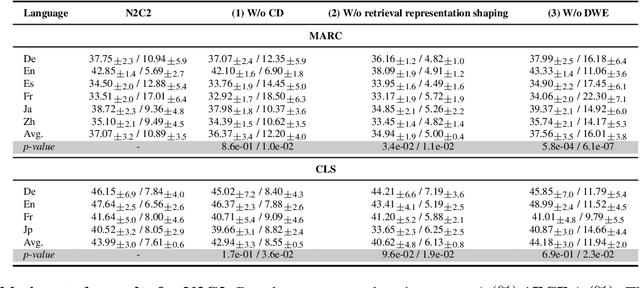
Recent advancements of in-context learning (ICL) show language models can significantly improve their performance when demonstrations are provided. However, little attention has been paid to model calibration and prediction confidence of ICL in cross-lingual scenarios. To bridge this gap, we conduct a thorough analysis of ICL for cross-lingual sentiment classification. Our findings suggest that ICL performs poorly in cross-lingual scenarios, exhibiting low accuracy and presenting high calibration errors. In response, we propose a novel approach, N2C2, which employs a -nearest neighbors augmented classifier for prediction confidence calibration. N2C2 narrows the prediction gap by leveraging a datastore of cached few-shot instances. Specifically, N2C2 integrates the predictions from the datastore and incorporates confidence-aware distribution, semantically consistent retrieval representation, and adaptive neighbor combination modules to effectively utilize the limited number of supporting instances. Evaluation on two multilingual sentiment classification datasets demonstrates that N2C2 outperforms traditional ICL. It surpasses fine tuning, prompt tuning and recent state-of-the-art methods in terms of accuracy and calibration errors.