 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrace2Skill: Distill Trajectory-Local Lessons into Transferable Agent Skills
Mar 26, 2026Equipping Large Language Model (LLM) agents with domain-specific skills is critical for tackling complex tasks. Yet, manual authoring creates a severe scalability bottleneck. Conversely, automated skill generation often yields fragile or fragmented results because it either relies on shallow parametric knowledge or sequentially overfits to non-generalizable trajectory-local lessons. To overcome this, we introduce Trace2Skill, a framework that mirrors how human experts author skills: by holistically analyzing broad execution experience before distilling it into a single, comprehensive guide. Instead of reacting sequentially to individual trajectories, Trace2Skill dispatches a parallel fleet of sub-agents to analyze a diverse pool of executions. It extracts trajectory-specific lessons and hierarchically consolidates them into a unified, conflict-free skill directory via inductive reasoning. Trace2Skill supports both deepening existing human-written skills and creating new ones from scratch. Experiments in challenging domains, such as spreadsheet, VisionQA and math reasoning, show that Trace2Skill significantly improves upon strong baselines, including Anthropic's official xlsx skills. Crucially, this trajectory-grounded evolution does not merely memorize task instances or model-specific quirks: evolved skills transfer across LLM scales and generalize to OOD settings. For example, skills evolved by Qwen3.5-35B on its own trajectories improved a Qwen3.5-122B agent by up to 57.65 absolute percentage points on WikiTableQuestions. Ultimately, our results demonstrate that complex agent experience can be packaged into highly transferable, declarative skills -- requiring no parameter updates, no external retrieval modules, and utilizing open-source models as small as 35B parameters.
TextlessRAG: End-to-End Visual Document RAG by Speech Without Text
Sep 10, 2025Document images encapsulate a wealth of knowledge, while the portability of spoken queries enables broader and flexible application scenarios. Yet, no prior work has explored knowledge base question answering over visual document images with queries provided directly in speech. We propose TextlessRAG, the first end-to-end framework for speech-based question answering over large-scale document images. Unlike prior methods, TextlessRAG eliminates ASR, TTS and OCR, directly interpreting speech, retrieving relevant visual knowledge, and generating answers in a fully textless pipeline. To further boost performance, we integrate a layout-aware reranking mechanism to refine retrieval. Experiments demonstrate substantial improvements in both efficiency and accuracy. To advance research in this direction, we also release the first bilingual speech--document RAG dataset, featuring Chinese and English voice queries paired with multimodal document content. Both the dataset and our pipeline will be made available at repository:https://github.com/xiepeijinhit-hue/textlessrag
AdaST: Dynamically Adapting Encoder States in the Decoder for End-to-End Speech-to-Text Translation
Mar 18, 2025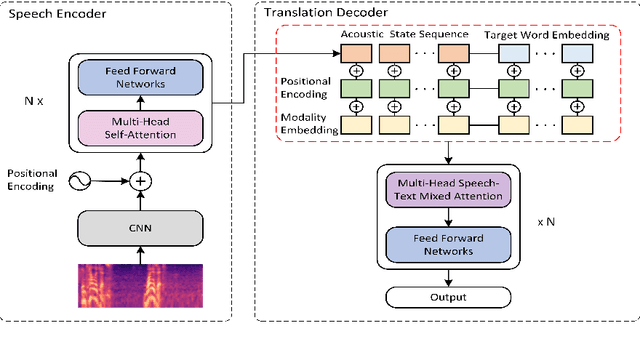

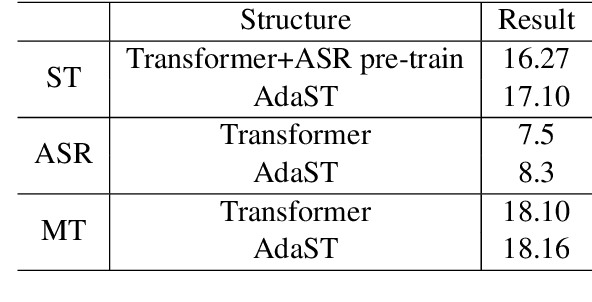

In end-to-end speech translation, acoustic representations learned by the encoder are usually fixed and static, from the perspective of the decoder, which is not desirable for dealing with the cross-modal and cross-lingual challenge in speech translation. In this paper, we show the benefits of varying acoustic states according to decoder hidden states and propose an adaptive speech-to-text translation model that is able to dynamically adapt acoustic states in the decoder. We concatenate the acoustic state and target word embedding sequence and feed the concatenated sequence into subsequent blocks in the decoder. In order to model the deep interaction between acoustic states and target hidden states, a speech-text mixed attention sublayer is introduced to replace the conventional cross-attention network. Experiment results on two widely-used datasets show that the proposed method significantly outperforms state-of-the-art neural speech translation models.
Goal State Generation for Robotic Manipulation Based on Linguistically Guided Hybrid Gaussian Diffusion
Dec 25, 2024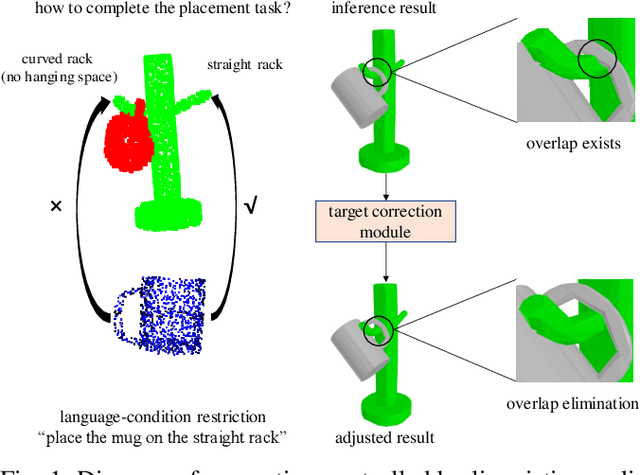
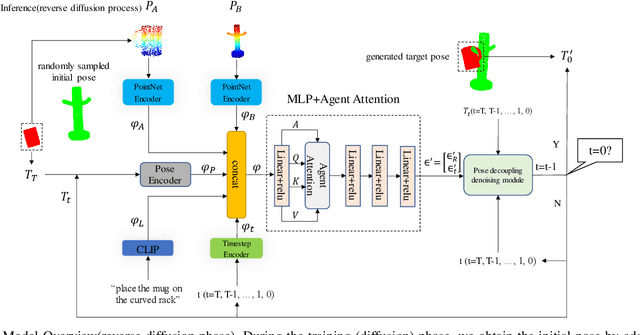
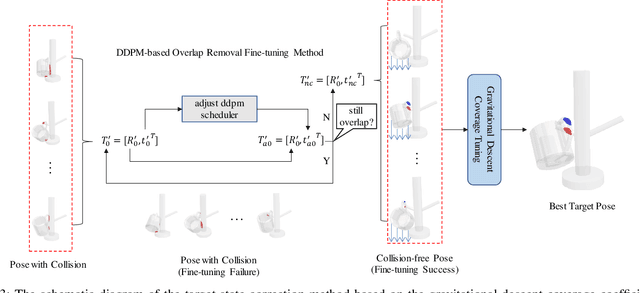

In robotic manipulation tasks, achieving a designated target state for the manipulated object is often essential to facilitate motion planning for robotic arms. Specifically, in tasks such as hanging a mug, the mug must be positioned within a feasible region around the hook. Previous approaches have enabled the generation of multiple feasible target states for mugs; however, these target states are typically generated randomly, lacking control over the specific generation locations. This limitation makes such methods less effective in scenarios where constraints exist, such as hooks already occupied by other mugs or when specific operational objectives must be met. Moreover, due to the frequent physical interactions between the mug and the rack in real-world hanging scenarios, imprecisely generated target states from end-to-end models often result in overlapping point clouds. This overlap adversely impacts subsequent motion planning for the robotic arm. To address these challenges, we propose a Linguistically Guided Hybrid Gaussian Diffusion (LHGD) network for generating manipulation target states, combined with a gravity coverage coefficient-based method for target state refinement. To evaluate our approach under a language-specified distribution setting, we collected multiple feasible target states for 10 types of mugs across 5 different racks with 10 distinct hooks. Additionally, we prepared five unseen mug designs for validation purposes. Experimental results demonstrate that our method achieves the highest success rates across single-mode, multi-mode, and language-specified distribution manipulation tasks. Furthermore, it significantly reduces point cloud overlap, directly producing collision-free target states and eliminating the need for additional obstacle avoidance operations by the robotic arm.
Expand VSR Benchmark for VLLM to Expertize in Spatial Rules
Dec 24, 2024



Distinguishing spatial relations is a basic part of human cognition which requires fine-grained perception on cross-instance. Although benchmarks like MME, MMBench and SEED comprehensively have evaluated various capabilities which already include visual spatial reasoning(VSR). There is still a lack of sufficient quantity and quality evaluation and optimization datasets for Vision Large Language Models(VLLMs) specifically targeting visual positional reasoning. To handle this, we first diagnosed current VLLMs with the VSR dataset and proposed a unified test set. We found current VLLMs to exhibit a contradiction of over-sensitivity to language instructions and under-sensitivity to visual positional information. By expanding the original benchmark from two aspects of tunning data and model structure, we mitigated this phenomenon. To our knowledge, we expanded spatially positioned image data controllably using diffusion models for the first time and integrated original visual encoding(CLIP) with other 3 powerful visual encoders(SigLIP, SAM and DINO). After conducting combination experiments on scaling data and models, we obtained a VLLM VSR Expert(VSRE) that not only generalizes better to different instructions but also accurately distinguishes differences in visual positional information. VSRE achieved over a 27\% increase in accuracy on the VSR test set. It becomes a performant VLLM on the position reasoning of both the VSR dataset and relevant subsets of other evaluation benchmarks. We open-sourced the expanded model with data and Appendix at \url{https://github.com/peijin360/vsre} and hope it will accelerate advancements in VLLM on VSR learning.
Hierarchical Diffusion Policy: manipulation trajectory generation via contact guidance
Nov 20, 2024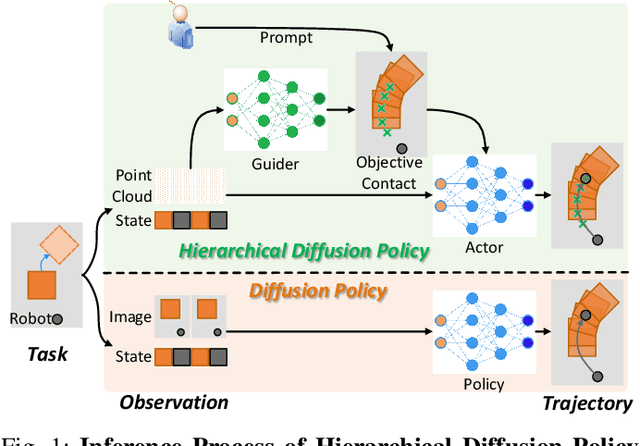


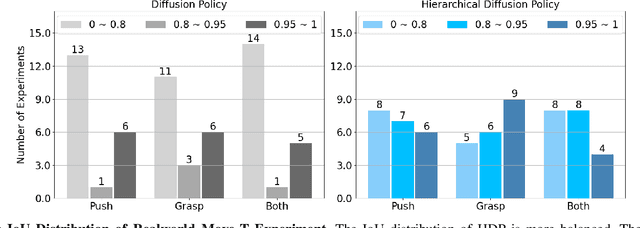
Decision-making in robotics using denoising diffusion processes has increasingly become a hot research topic, but end-to-end policies perform poorly in tasks with rich contact and have limited controllability. This paper proposes Hierarchical Diffusion Policy (HDP), a new imitation learning method of using objective contacts to guide the generation of robot trajectories. The policy is divided into two layers: the high-level policy predicts the contact for the robot's next object manipulation based on 3D information, while the low-level policy predicts the action sequence toward the high-level contact based on the latent variables of observation and contact. We represent both level policies as conditional denoising diffusion processes, and combine behavioral cloning and Q-learning to optimize the low level policy for accurately guiding actions towards contact. We benchmark Hierarchical Diffusion Policy across 6 different tasks and find that it significantly outperforms the existing state of-the-art imitation learning method Diffusion Policy with an average improvement of 20.8%. We find that contact guidance yields significant improvements, including superior performance, greater interpretability, and stronger controllability, especially on contact-rich tasks. To further unlock the potential of HDP, this paper proposes a set of key technical contributions including snapshot gradient optimization, 3D conditioning, and prompt guidance, which improve the policy's optimization efficiency, spatial awareness, and controllability respectively. Finally, real world experiments verify that HDP can handle both rigid and deformable objects.
DRIP: A Versatile Family of Space-Time ISAC Waveforms
Oct 16, 2024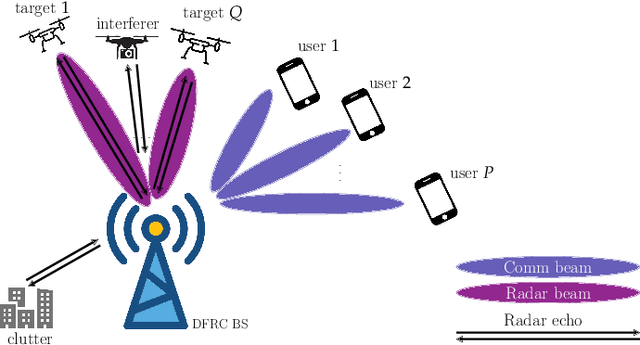
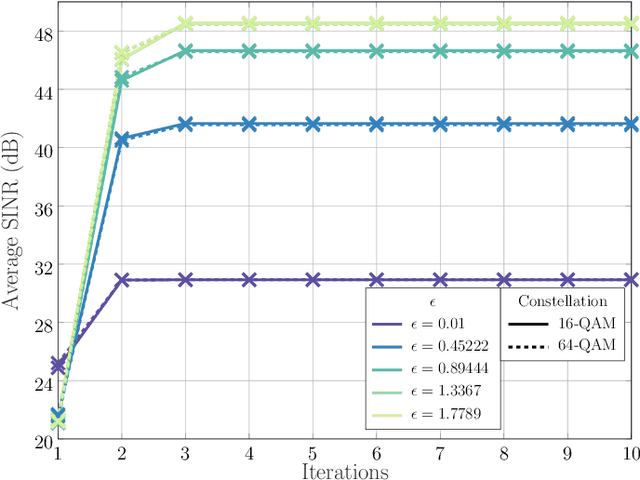
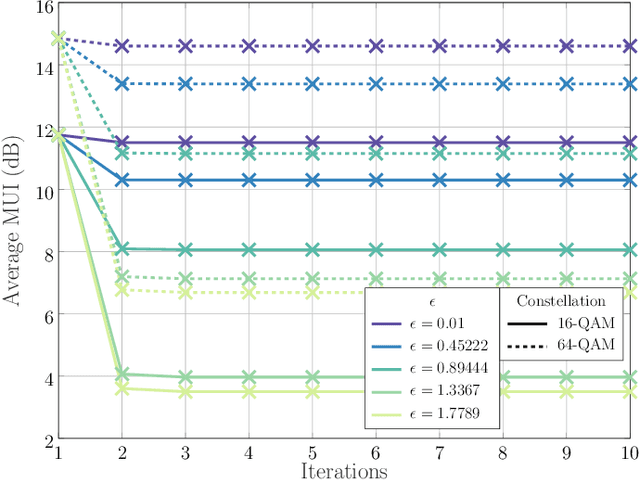
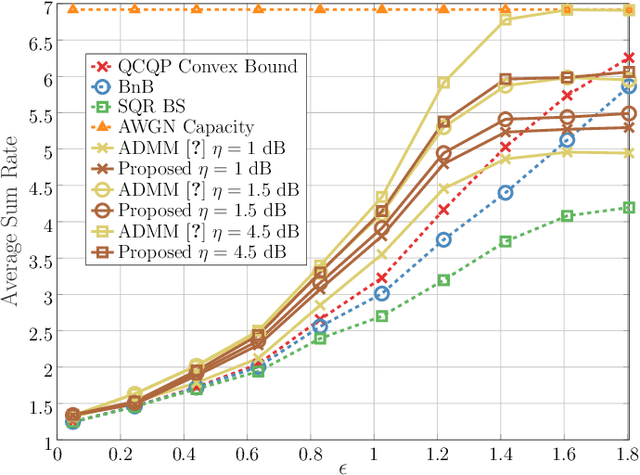
The following paper introduces Dual beam-similarity awaRe Integrated sensing and communications (ISAC) with controlled Peak-to-average power ratio (DRIP) waveforms. DRIP is a novel family of space-time ISAC waveforms designed for dynamic peak-to-average power ratio (PAPR) adjustment. The proposed DRIP waveforms are designed to conform to specified PAPR levels while exhibiting beampattern properties, effectively targeting multiple desired directions and suppressing interference for multi-target sensing applications, while closely resembling radar chirps. For communication purposes, the proposed DRIP waveforms aim to minimize multi-user interference across various constellations. Addressing the non-convexity of the optimization framework required for generating DRIP waveforms, we introduce a block cyclic coordinate descent algorithm. This iterative approach ensures convergence to an optimal ISAC waveform solution. Simulation results validate the DRIP waveforms' superior performance, versatility, and favorable ISAC trade-offs, highlighting their potential in advanced multi-target sensing and communication systems.
RIS-Enabled Integrated Sensing and Communication for 6G Systems
Dec 31, 2023



The following paper proposes a new target localization system design using an architecture based on reconfigurable intelligent surfaces (RISs) and passive radars (PRs) for integrated sensing and communications systems. The preamble of the communication signal is exploited in order to perform target sensing tasks, which involve detection and localization. The RIS in this case can aid the PR in sensing targets that are otherwise not seen by the PR itself, due to the many obstacles encountered within the propagation channel. Therefore, this work proposes a localization algorithm tailored for the integrated sensing and communications RIS-aided architecture, which is capable of uniquely positioning targets within the scene. The algorithm is capable of detecting the number of targets along with estimating the position of targets via angles and times of arrival. Our simulation results demonstrate the performance of the localization method in terms of different localization and detection metrics and for increasing RIS sizes.
Multi-Stage Reinforcement Learning for Non-Prehensile Manipulation
Jul 22, 2023



Manipulating objects without grasping them enables more complex tasks, known as non-prehensile manipulation. Most previous methods only learn one manipulation skill, such as reach or push, and cannot achieve flexible object manipulation.In this work, we introduce MRLM, a Multi-stage Reinforcement Learning approach for non-prehensile Manipulation of objects.MRLM divides the task into multiple stages according to the switching of object poses and contact points.At each stage, the policy takes the point cloud-based state-goal fusion representation as input, and proposes a spatially-continuous action that including the motion of the parallel gripper pose and opening width.To fully unlock the potential of MRLM, we propose a set of technical contributions including the state-goal fusion representation, spatially-reachable distance metric, and automatic buffer compaction.We evaluate MRLM on an Occluded Grasping task which aims to grasp the object in configurations that are initially occluded.Compared with the baselines, the proposed technical contributions improve the success rate by at least 40\% and maximum 100\%, and avoids falling into local optimum.Our method demonstrates strong generalization to unseen object with shapes outside the training distribution.Moreover, MRLM can be transferred to real world with zero-shot transfer, achieving a 95\% success rate.Code and videos can be found at https://sites.google.com/view/mrlm.
Zero and R2D2: A Large-scale Chinese Cross-modal Benchmark and A Vision-Language Framework
May 08, 2022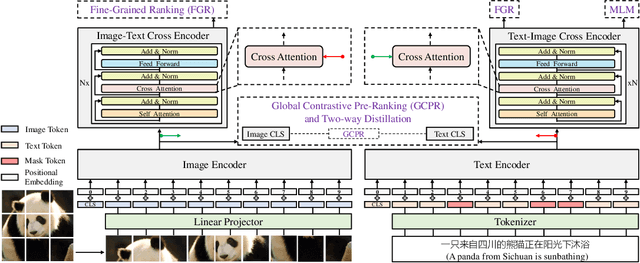
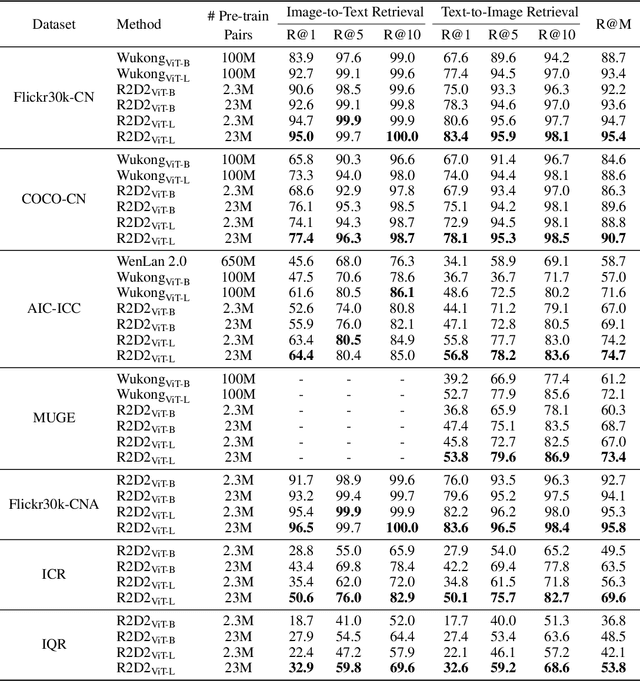

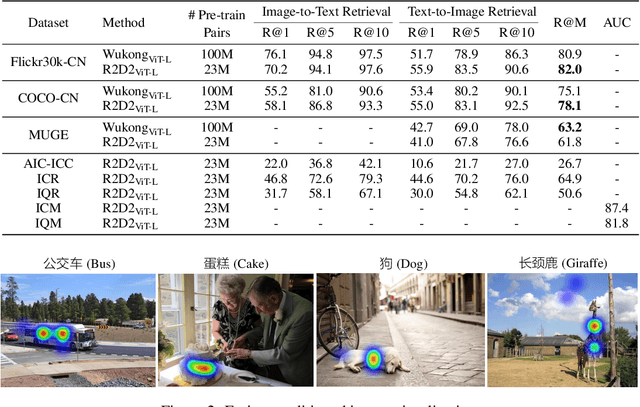
Vision-language pre-training (VLP) relying on large-scale pre-training datasets has shown premier performance on various downstream tasks. In this sense, a complete and fair benchmark (i.e., including large-scale pre-training datasets and a variety of downstream datasets) is essential for VLP. But how to construct such a benchmark in Chinese remains a critical problem. To this end, we develop a large-scale Chinese cross-modal benchmark called Zero for AI researchers to fairly compare VLP models. We release two pre-training datasets and five fine-tuning datasets for downstream tasks. Furthermore, we propose a novel pre-training framework of pre-Ranking + Ranking for cross-modal learning. Specifically, we apply global contrastive pre-ranking to learn the individual representations of images and Chinese texts, respectively. We then fuse the representations in a fine-grained ranking manner via an image-text cross encoder and a text-image cross encoder. To further enhance the capability of the model, we propose a two-way distillation strategy consisting of target-guided Distillation and feature-guided Distillation. For simplicity, we call our model R2D2. We achieve state-of-the-art performance on four public cross-modal datasets and our five downstream datasets. The datasets, models and codes will be made available.