 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMatMind: A Structure-Activity Knowledge-Driven Generative Foundation Model for Materials Science
Jun 05, 2026Progress in AI-driven crystal materials science has so far been carried by narrow architectures purpose-built for individual tasks -- graph neural networks for property prediction, diffusion and flow-matching models for crystal generation -- each excelling within its niche yet unable to act as a shared backbone across the full spectrum of materials problems. Generative large language models offer a fundamentally different paradigm, in which structural representation, quantitative prediction, and structure-activity reasoning can be unified within one model, but the materials community has yet to see this paradigm realized at a level competitive with established narrow specialists. Here we present MatMind, a generative foundation model purpose-built for crystal materials science under this paradigm, developed through the coordinated activation of structure-activity knowledge and physics-informed feedback within a progressive training framework -- combining structure-activity knowledge injection, a dual-head architecture that jointly trains language reasoning and numerical regression in a shared representation space, and multi-objective physics-informed reinforcement learning over stability, novelty, and structural diversity. Across three task families, MatMind attains the lowest mean absolute error on energy above hull, bulk modulus, and band gap -- surpassing graph neural network predictors purpose-built for these tasks -- reaches an S.U.N. rate of 65.3% on unconditional crystal generation, and achieves a comparable multiplicative improvement on magnetization-density-conditioned generation, where only 21 positive samples exist within over 600000 training entries. By matching or surpassing narrow specialists on their own ground while operating within a single unified model, MatMind shows that the LLM-based paradigm can serve as a viable backbone for crystal materials science going forward.
Taming Outlier Tokens in Diffusion Transformers
May 06, 2026We study outlier tokens in Diffusion Transformers (DiTs) for image generation. Prior work has shown that Vision Transformers (ViTs) can produce a small number of high-norm tokens that attract disproportionate attention while carrying limited local information, but their role in generative models remains underexplored. We show that this phenomenon appears in both the encoder and denoiser of modern Representation Autoencoder (RAE)-DiT pipelines: pretrained ViT encoders can produce outlier representations, and DiTs themselves can develop internal outlier tokens, especially in intermediate layers. Moreover, simply masking high-norm tokens does not improve performance, indicating that the problem is not only caused by a few extreme values, but is more closely related to corrupted local patch semantics. To address this issue, we introduce Dual-Stage Registers (DSR), a register-based intervention for both components: trained registers when available, recursive test-time registers otherwise, and diffusion registers for the denoiser. Across ImageNet and large-scale text-to-image generation, these interventions consistently reduce outlier artifacts and improve generation quality. Our results highlight outlier-token control as an important ingredient in building stronger DiTs.
ESOM: Efficiently Understanding Streaming Video Anomalies with Open-world Dynamic Definitions
Apr 09, 2026Open-world video anomaly detection (OWVAD) aims to detect and explain abnormal events under different anomaly definitions, which is important for applications such as intelligent surveillance and live-streaming content moderation. Recent MLLM-based methods have shown promising open-world generalization, but still suffer from three major limitations: inefficiency for practical deployment, lack of streaming processing adaptation, and limited support for dynamic anomaly definitions in both modeling and evaluation. To address these issues, this paper proposes ESOM, an efficient streaming OWVAD model that operates in a training-free manner. ESOM includes a Definition Normalization module to structure user prompts for reducing hallucination, an Inter-frame-matched Intra-frame Token Merging module to compress redundant visual tokens, a Hybrid Streaming Memory module for efficient causal inference, and a Probabilistic Scoring module that converts interval-level textual outputs into frame-level anomaly scores. In addition, this paper introduces OpenDef-Bench, a new benchmark with clean surveillance videos and diverse natural anomaly definitions for evaluating performance under varying conditions. Extensive experiments show that ESOM achieves real-time efficiency on a single GPU and state-of-the-art performance in anomaly temporal localization, classification, and description generation. The code and benchmark will be released at https://github.com/Kamino666/ESOM_OpenDef-Bench.
RPiAE: A Representation-Pivoted Autoencoder Enhancing Both Image Generation and Editing
Mar 19, 2026Diffusion models have become the dominant paradigm for image generation and editing, with latent diffusion models shifting denoising to a compact latent space for efficiency and scalability. Recent attempts to leverage pretrained visual representation models as tokenizer priors either align diffusion features to representation features or directly reuse representation encoders as frozen tokenizers. Although such approaches can improve generation metrics, they often suffer from limited reconstruction fidelity due to frozen encoders, which in turn degrades editing quality, as well as overly high-dimensional latents that make diffusion modeling difficult. To address these limitations, We propose Representation-Pivoted AutoEncoder, a representation-based tokenizer that improves both generation and editing. We introduce Representation-Pivot Regularization, a training strategy that enables a representation-initialized encoder to be fine-tuned for reconstruction while preserving the semantic structure of the pretrained representation space, followed by a variational bridge which compress latent space into a compact one for better diffusion modeling. We adopt an objective-decoupled stage-wise training strategy that sequentially optimizes generative tractability and reconstruction-fidelity objectives. Together, these components yield a tokenizer that preserves strong semantics, reconstructs faithfully, and produces latents with reduced diffusion modeling complexity. Experiments demonstrate that RPiAE outperforms other visual tokenizers on text-to-image generation and image editing, while delivering the best reconstruction fidelity among representation-based tokenizers.
FedMomentum: Preserving LoRA Training Momentum in Federated Fine-Tuning
Mar 09, 2026Federated fine-tuning of large language models (LLMs) with low-rank adaptation (LoRA) offers a communication-efficient and privacy-preserving solution for task-specific adaptation. Naive aggregation of LoRA modules introduces noise due to mathematical incorrectness when averaging the downsampling and upsampling matrices independently. However, existing noise-free aggregation strategies inevitably compromise the structural expressiveness of LoRA, limiting its ability to retain client-specific adaptations by either improperly reconstructing the low-rank structure or excluding partially trainable components. We identify this problem as loss of training momentum, where LoRA updates fail to accumulate effectively across rounds, resulting in slower convergence and suboptimal performance. To address this, we propose FedMomentum, a novel framework that enables structured and momentum-preserving LoRA aggregation via singular value decomposition (SVD). Specifically, after aggregating low-rank updates in a mathematically correct manner, FedMomentum applies SVD to extract the dominant components that capture the main update directions. These components are used to reconstruct the LoRA modules with the same rank, while residual components can be retained and later merged into the backbone to preserve semantic information and ensure robustness. Extensive experiments across multiple tasks demonstrate that FedMomentum consistently outperforms prior state-of-the-art methods in convergence speed and final accuracy.
Evaluating Modern Large Language Models on Low-Resource and Morphologically Rich Languages:A Cross-Lingual Benchmark Across Cantonese, Japanese, and Turkish
Nov 05, 2025
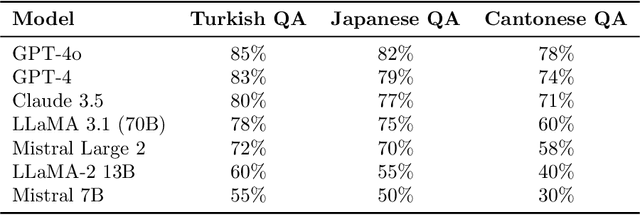
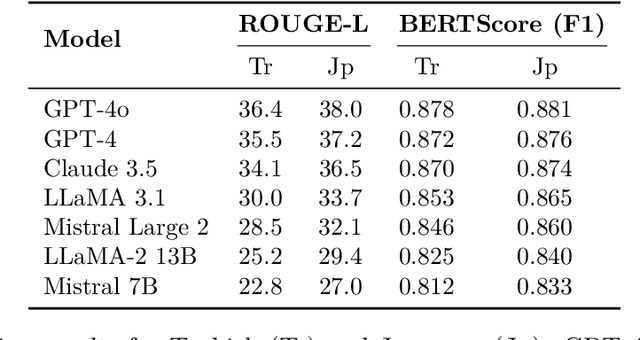
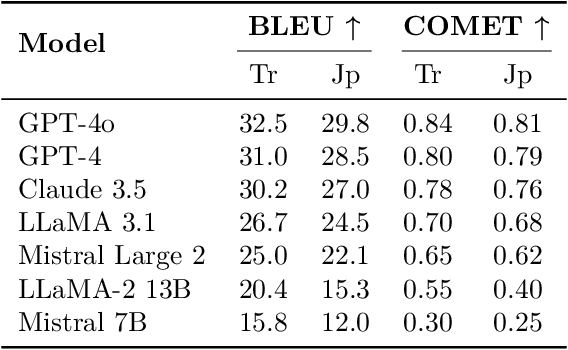
Large language models (LLMs) have achieved impressive results in high-resource languages like English, yet their effectiveness in low-resource and morphologically rich languages remains underexplored. In this paper, we present a comprehensive evaluation of seven cutting-edge LLMs -- including GPT-4o, GPT-4, Claude~3.5~Sonnet, LLaMA~3.1, Mistral~Large~2, LLaMA-2~Chat~13B, and Mistral~7B~Instruct -- on a new cross-lingual benchmark covering \textbf{Cantonese, Japanese, and Turkish}. Our benchmark spans four diverse tasks: open-domain question answering, document summarization, English-to-X translation, and culturally grounded dialogue. We combine \textbf{human evaluations} (rating fluency, factual accuracy, and cultural appropriateness) with automated metrics (e.g., BLEU, ROUGE) to assess model performance. Our results reveal that while the largest proprietary models (GPT-4o, GPT-4, Claude~3.5) generally lead across languages and tasks, significant gaps persist in culturally nuanced understanding and morphological generalization. Notably, GPT-4o demonstrates robust multilingual performance even on cross-lingual tasks, and Claude~3.5~Sonnet achieves competitive accuracy on knowledge and reasoning benchmarks. However, all models struggle to some extent with the unique linguistic challenges of each language, such as Turkish agglutinative morphology and Cantonese colloquialisms. Smaller open-source models (LLaMA-2~13B, Mistral~7B) lag substantially in fluency and accuracy, highlighting the resource disparity. We provide detailed quantitative results, qualitative error analysis, and discuss implications for developing more culturally aware and linguistically generalizable LLMs. Our benchmark and evaluation data are released to foster reproducibility and further research.
POLAR: Policy-based Layerwise Reinforcement Learning Method for Stealthy Backdoor Attacks in Federated Learning
Oct 21, 2025



Federated Learning (FL) enables decentralized model training across multiple clients without exposing local data, but its distributed feature makes it vulnerable to backdoor attacks. Despite early FL backdoor attacks modifying entire models, recent studies have explored the concept of backdoor-critical (BC) layers, which poison the chosen influential layers to maintain stealthiness while achieving high effectiveness. However, existing BC layers approaches rely on rule-based selection without consideration of the interrelations between layers, making them ineffective and prone to detection by advanced defenses. In this paper, we propose POLAR (POlicy-based LAyerwise Reinforcement learning), the first pipeline to creatively adopt RL to solve the BC layer selection problem in layer-wise backdoor attack. Different from other commonly used RL paradigm, POLAR is lightweight with Bernoulli sampling. POLAR dynamically learns an attack strategy, optimizing layer selection using policy gradient updates based on backdoor success rate (BSR) improvements. To ensure stealthiness, we introduce a regularization constraint that limits the number of modified layers by penalizing large attack footprints. Extensive experiments demonstrate that POLAR outperforms the latest attack methods by up to 40% against six state-of-the-art (SOTA) defenses.
CTA-Flux: Integrating Chinese Cultural Semantics into High-Quality English Text-to-Image Communities
Aug 20, 2025We proposed the Chinese Text Adapter-Flux (CTA-Flux). An adaptation method fits the Chinese text inputs to Flux, a powerful text-to-image (TTI) generative model initially trained on the English corpus. Despite the notable image generation ability conditioned on English text inputs, Flux performs poorly when processing non-English prompts, particularly due to linguistic and cultural biases inherent in predominantly English-centric training datasets. Existing approaches, such as translating non-English prompts into English or finetuning models for bilingual mappings, inadequately address culturally specific semantics, compromising image authenticity and quality. To address this issue, we introduce a novel method to bridge Chinese semantic understanding with compatibility in English-centric TTI model communities. Existing approaches relying on ControlNet-like architectures typically require a massive parameter scale and lack direct control over Chinese semantics. In comparison, CTA-flux leverages MultiModal Diffusion Transformer (MMDiT) to control the Flux backbone directly, significantly reducing the number of parameters while enhancing the model's understanding of Chinese semantics. This integration significantly improves the generation quality and cultural authenticity without extensive retraining of the entire model, thus maintaining compatibility with existing text-to-image plugins such as LoRA, IP-Adapter, and ControlNet. Empirical evaluations demonstrate that CTA-flux supports Chinese and English prompts and achieves superior image generation quality, visual realism, and faithful depiction of Chinese semantics.
NanoControl: A Lightweight Framework for Precise and Efficient Control in Diffusion Transformer
Aug 14, 2025Diffusion Transformers (DiTs) have demonstrated exceptional capabilities in text-to-image synthesis. However, in the domain of controllable text-to-image generation using DiTs, most existing methods still rely on the ControlNet paradigm originally designed for UNet-based diffusion models. This paradigm introduces significant parameter overhead and increased computational costs. To address these challenges, we propose the Nano Control Diffusion Transformer (NanoControl), which employs Flux as the backbone network. Our model achieves state-of-the-art controllable text-to-image generation performance while incurring only a 0.024\% increase in parameter count and a 0.029\% increase in GFLOPs, thus enabling highly efficient controllable generation. Specifically, rather than duplicating the DiT backbone for control, we design a LoRA-style (low-rank adaptation) control module that directly learns control signals from raw conditioning inputs. Furthermore, we introduce a KV-Context Augmentation mechanism that integrates condition-specific key-value information into the backbone in a simple yet highly effective manner, facilitating deep fusion of conditional features. Extensive benchmark experiments demonstrate that NanoControl significantly reduces computational overhead compared to conventional control approaches, while maintaining superior generation quality and achieving improved controllability.
FLUX-Makeup: High-Fidelity, Identity-Consistent, and Robust Makeup Transfer via Diffusion Transformer
Aug 07, 2025
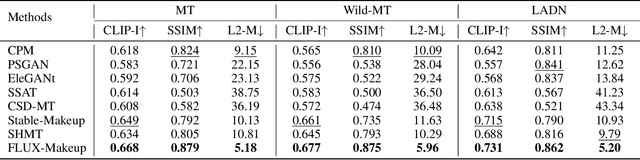
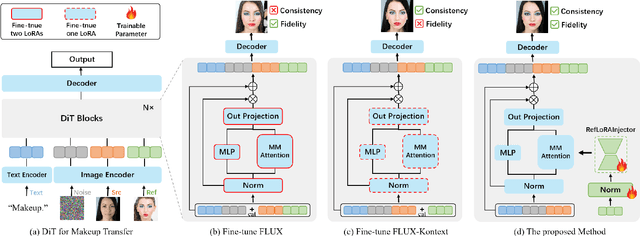
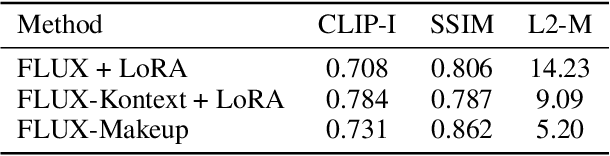
Makeup transfer aims to apply the makeup style from a reference face to a target face and has been increasingly adopted in practical applications. Existing GAN-based approaches typically rely on carefully designed loss functions to balance transfer quality and facial identity consistency, while diffusion-based methods often depend on additional face-control modules or algorithms to preserve identity. However, these auxiliary components tend to introduce extra errors, leading to suboptimal transfer results. To overcome these limitations, we propose FLUX-Makeup, a high-fidelity, identity-consistent, and robust makeup transfer framework that eliminates the need for any auxiliary face-control components. Instead, our method directly leverages source-reference image pairs to achieve superior transfer performance. Specifically, we build our framework upon FLUX-Kontext, using the source image as its native conditional input. Furthermore, we introduce RefLoRAInjector, a lightweight makeup feature injector that decouples the reference pathway from the backbone, enabling efficient and comprehensive extraction of makeup-related information. In parallel, we design a robust and scalable data generation pipeline to provide more accurate supervision during training. The paired makeup datasets produced by this pipeline significantly surpass the quality of all existing datasets. Extensive experiments demonstrate that FLUX-Makeup achieves state-of-the-art performance, exhibiting strong robustness across diverse scenarios.