 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage-guided Open-world Video Anomaly Detection
Mar 17, 2025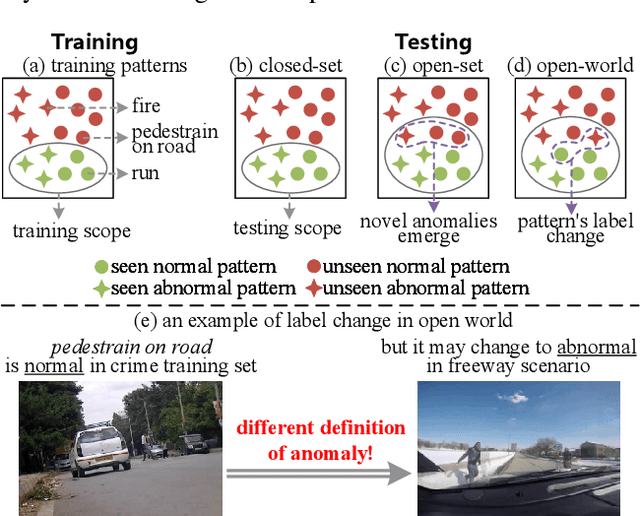
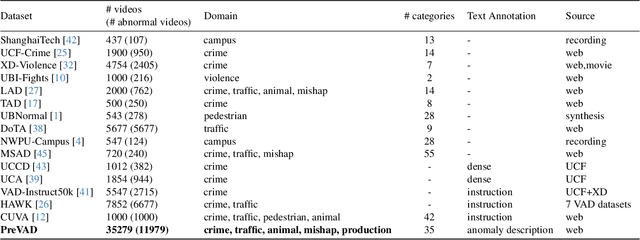
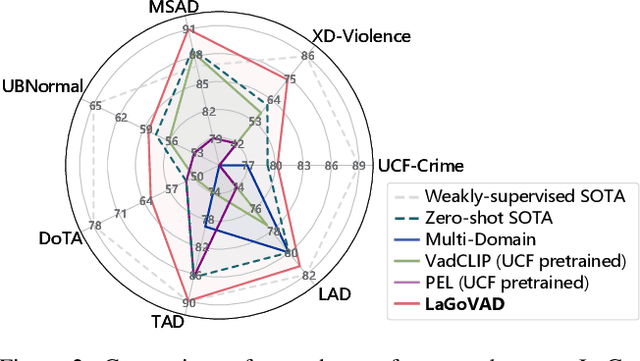
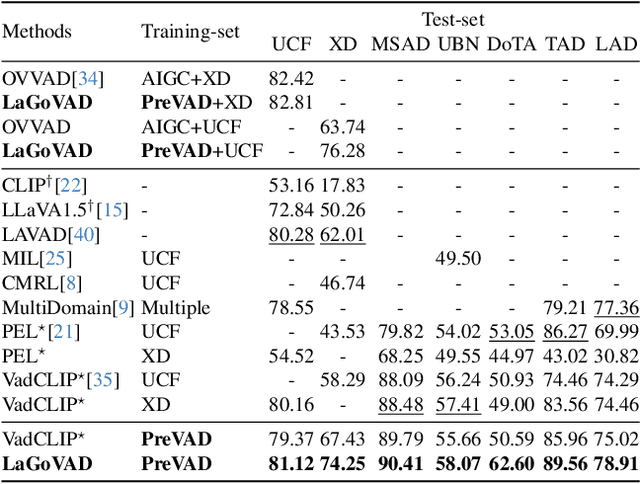
Video anomaly detection models aim to detect anomalies that deviate from what is expected. In open-world scenarios, the expected events may change as requirements change. For example, not wearing a mask is considered abnormal during a flu outbreak but normal otherwise. However, existing methods assume that the definition of anomalies is invariable, and thus are not applicable to the open world. To address this, we propose a novel open-world VAD paradigm with variable definitions, allowing guided detection through user-provided natural language at inference time. This paradigm necessitates establishing a robust mapping from video and textual definition to anomaly score. Therefore, we propose LaGoVAD (Language-guided Open-world VAD), a model that dynamically adapts anomaly definitions through two regularization strategies: diversifying the relative durations of anomalies via dynamic video synthesis, and enhancing feature robustness through contrastive learning with negative mining. Training such adaptable models requires diverse anomaly definitions, but existing datasets typically provide given labels without semantic descriptions. To bridge this gap, we collect PreVAD (Pre-training Video Anomaly Dataset), the largest and most diverse video anomaly dataset to date, featuring 35,279 annotated videos with multi-level category labels and descriptions that explicitly define anomalies. Zero-shot experiments on seven datasets demonstrate SOTA performance. Data and code will be released.