 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTAG-MoE: Task-Aware Gating for Unified Generative Mixture-of-Experts
Jan 12, 2026Unified image generation and editing models suffer from severe task interference in dense diffusion transformers architectures, where a shared parameter space must compromise between conflicting objectives (e.g., local editing v.s. subject-driven generation). While the sparse Mixture-of-Experts (MoE) paradigm is a promising solution, its gating networks remain task-agnostic, operating based on local features, unaware of global task intent. This task-agnostic nature prevents meaningful specialization and fails to resolve the underlying task interference. In this paper, we propose a novel framework to inject semantic intent into MoE routing. We introduce a Hierarchical Task Semantic Annotation scheme to create structured task descriptors (e.g., scope, type, preservation). We then design Predictive Alignment Regularization to align internal routing decisions with the task's high-level semantics. This regularization evolves the gating network from a task-agnostic executor to a dispatch center. Our model effectively mitigates task interference, outperforming dense baselines in fidelity and quality, and our analysis shows that experts naturally develop clear and semantically correlated specializations.
Re-Align: Structured Reasoning-guided Alignment for In-Context Image Generation and Editing
Jan 08, 2026In-context image generation and editing (ICGE) enables users to specify visual concepts through interleaved image-text prompts, demanding precise understanding and faithful execution of user intent. Although recent unified multimodal models exhibit promising understanding capabilities, these strengths often fail to transfer effectively to image generation. We introduce Re-Align, a unified framework that bridges the gap between understanding and generation through structured reasoning-guided alignment. At its core lies the In-Context Chain-of-Thought (IC-CoT), a structured reasoning paradigm that decouples semantic guidance and reference association, providing clear textual target and mitigating confusion among reference images. Furthermore, Re-Align introduces an effective RL training scheme that leverages a surrogate reward to measure the alignment between structured reasoning text and the generated image, thereby improving the model's overall performance on ICGE tasks. Extensive experiments verify that Re-Align outperforms competitive methods of comparable model scale and resources on both in-context image generation and editing tasks.
MoFu: Scale-Aware Modulation and Fourier Fusion for Multi-Subject Video Generation
Dec 26, 2025Multi-subject video generation aims to synthesize videos from textual prompts and multiple reference images, ensuring that each subject preserves natural scale and visual fidelity. However, current methods face two challenges: scale inconsistency, where variations in subject size lead to unnatural generation, and permutation sensitivity, where the order of reference inputs causes subject distortion. In this paper, we propose MoFu, a unified framework that tackles both challenges. For scale inconsistency, we introduce Scale-Aware Modulation (SMO), an LLM-guided module that extracts implicit scale cues from the prompt and modulates features to ensure consistent subject sizes. To address permutation sensitivity, we present a simple yet effective Fourier Fusion strategy that processes the frequency information of reference features via the Fast Fourier Transform to produce a unified representation. Besides, we design a Scale-Permutation Stability Loss to jointly encourage scale-consistent and permutation-invariant generation. To further evaluate these challenges, we establish a dedicated benchmark with controlled variations in subject scale and reference permutation. Extensive experiments demonstrate that MoFu significantly outperforms existing methods in preserving natural scale, subject fidelity, and overall visual quality.
Align Beyond Prompts: Evaluating World Knowledge Alignment in Text-to-Image Generation
May 24, 2025Recent text-to-image (T2I) generation models have advanced significantly, enabling the creation of high-fidelity images from textual prompts. However, existing evaluation benchmarks primarily focus on the explicit alignment between generated images and prompts, neglecting the alignment with real-world knowledge beyond prompts. To address this gap, we introduce Align Beyond Prompts (ABP), a comprehensive benchmark designed to measure the alignment of generated images with real-world knowledge that extends beyond the explicit user prompts. ABP comprises over 2,000 meticulously crafted prompts, covering real-world knowledge across six distinct scenarios. We further introduce ABPScore, a metric that utilizes existing Multimodal Large Language Models (MLLMs) to assess the alignment between generated images and world knowledge beyond prompts, which demonstrates strong correlations with human judgments. Through a comprehensive evaluation of 8 popular T2I models using ABP, we find that even state-of-the-art models, such as GPT-4o, face limitations in integrating simple real-world knowledge into generated images. To mitigate this issue, we introduce a training-free strategy within ABP, named Inference-Time Knowledge Injection (ITKI). By applying this strategy to optimize 200 challenging samples, we achieved an improvement of approximately 43% in ABPScore. The dataset and code are available in https://github.com/smile365317/ABP.
PlanGen: Towards Unified Layout Planning and Image Generation in Auto-Regressive Vision Language Models
Mar 13, 2025In this paper, we propose a unified layout planning and image generation model, PlanGen, which can pre-plan spatial layout conditions before generating images. Unlike previous diffusion-based models that treat layout planning and layout-to-image as two separate models, PlanGen jointly models the two tasks into one autoregressive transformer using only next-token prediction. PlanGen integrates layout conditions into the model as context without requiring specialized encoding of local captions and bounding box coordinates, which provides significant advantages over the previous embed-and-pool operations on layout conditions, particularly when dealing with complex layouts. Unified prompting allows PlanGen to perform multitasking training related to layout, including layout planning, layout-to-image generation, image layout understanding, etc. In addition, PlanGen can be seamlessly expanded to layout-guided image manipulation thanks to the well-designed modeling, with teacher-forcing content manipulation policy and negative layout guidance. Extensive experiments verify the effectiveness of our PlanGen in multiple layoutrelated tasks, showing its great potential. Code is available at: https://360cvgroup.github.io/PlanGen.
FreeEdit: Mask-free Reference-based Image Editing with Multi-modal Instruction
Sep 26, 2024Introducing user-specified visual concepts in image editing is highly practical as these concepts convey the user's intent more precisely than text-based descriptions. We propose FreeEdit, a novel approach for achieving such reference-based image editing, which can accurately reproduce the visual concept from the reference image based on user-friendly language instructions. Our approach leverages the multi-modal instruction encoder to encode language instructions to guide the editing process. This implicit way of locating the editing area eliminates the need for manual editing masks. To enhance the reconstruction of reference details, we introduce the Decoupled Residual ReferAttention (DRRA) module. This module is designed to integrate fine-grained reference features extracted by a detail extractor into the image editing process in a residual way without interfering with the original self-attention. Given that existing datasets are unsuitable for reference-based image editing tasks, particularly due to the difficulty in constructing image triplets that include a reference image, we curate a high-quality dataset, FreeBench, using a newly developed twice-repainting scheme. FreeBench comprises the images before and after editing, detailed editing instructions, as well as a reference image that maintains the identity of the edited object, encompassing tasks such as object addition, replacement, and deletion. By conducting phased training on FreeBench followed by quality tuning, FreeEdit achieves high-quality zero-shot editing through convenient language instructions. We conduct extensive experiments to evaluate the effectiveness of FreeEdit across multiple task types, demonstrating its superiority over existing methods. The code will be available at: https://freeedit.github.io/.
Customize your NeRF: Adaptive Source Driven 3D Scene Editing via Local-Global Iterative Training
Dec 04, 2023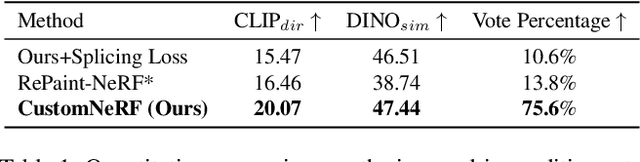
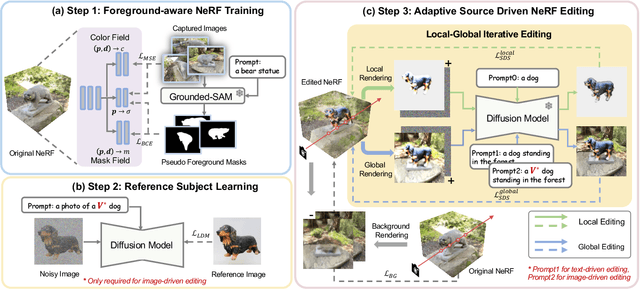


In this paper, we target the adaptive source driven 3D scene editing task by proposing a CustomNeRF model that unifies a text description or a reference image as the editing prompt. However, obtaining desired editing results conformed with the editing prompt is nontrivial since there exist two significant challenges, including accurate editing of only foreground regions and multi-view consistency given a single-view reference image. To tackle the first challenge, we propose a Local-Global Iterative Editing (LGIE) training scheme that alternates between foreground region editing and full-image editing, aimed at foreground-only manipulation while preserving the background. For the second challenge, we also design a class-guided regularization that exploits class priors within the generation model to alleviate the inconsistency problem among different views in image-driven editing. Extensive experiments show that our CustomNeRF produces precise editing results under various real scenes for both text- and image-driven settings.