 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIPO: Iterative Preference Optimization for Text-to-Video Generation
Feb 05, 2025



Video foundation models have achieved significant advancement with the help of network upgrade as well as model scale-up. However, they are still hard to meet requirements of applications due to unsatisfied generation quality. To solve this problem, we propose to align video foundation models with human preferences from the perspective of post-training in this paper. Consequently, we introduce an Iterative Preference Optimization strategy to enhance generated video quality by incorporating human feedback. Specifically, IPO exploits a critic model to justify video generations for pairwise ranking as in Direct Preference Optimization or point-wise scoring as in Kahneman-Tversky Optimization. Given this, IPO optimizes video foundation models with guidance of signals from preference feedback, which helps improve generated video quality in subject consistency, motion smoothness and aesthetic quality, etc. In addition, IPO incorporates the critic model with the multi-modality large language model, which enables it to automatically assign preference labels without need of retraining or relabeling. In this way, IPO can efficiently perform multi-round preference optimization in an iterative manner, without the need of tediously manual labeling. Comprehensive experiments demonstrate that the proposed IPO can effectively improve the video generation quality of a pretrained model and help a model with only 2B parameters surpass the one with 5B parameters. Besides, IPO achieves new state-of-the-art performance on VBench benchmark. We will release our source codes, models as well as dataset to advance future research and applications.
Multimodal Music Generation with Explicit Bridges and Retrieval Augmentation
Dec 12, 2024Multimodal music generation aims to produce music from diverse input modalities, including text, videos, and images. Existing methods use a common embedding space for multimodal fusion. Despite their effectiveness in other modalities, their application in multimodal music generation faces challenges of data scarcity, weak cross-modal alignment, and limited controllability. This paper addresses these issues by using explicit bridges of text and music for multimodal alignment. We introduce a novel method named Visuals Music Bridge (VMB). Specifically, a Multimodal Music Description Model converts visual inputs into detailed textual descriptions to provide the text bridge; a Dual-track Music Retrieval module that combines broad and targeted retrieval strategies to provide the music bridge and enable user control. Finally, we design an Explicitly Conditioned Music Generation framework to generate music based on the two bridges. We conduct experiments on video-to-music, image-to-music, text-to-music, and controllable music generation tasks, along with experiments on controllability. The results demonstrate that VMB significantly enhances music quality, modality, and customization alignment compared to previous methods. VMB sets a new standard for interpretable and expressive multimodal music generation with applications in various multimedia fields. Demos and code are available at https://github.com/wbs2788/VMB.
SPDiffusion: Semantic Protection Diffusion for Multi-concept Text-to-image Generation
Sep 02, 2024



Recent text-to-image models have achieved remarkable success in generating high-quality images. However, when tasked with multi-concept generation which creates images containing multiple characters or objects, existing methods often suffer from attribute confusion, resulting in severe text-image inconsistency. We found that attribute confusion occurs when a certain region of the latent features attend to multiple or incorrect prompt tokens. In this work, we propose novel Semantic Protection Diffusion (SPDiffusion) to protect the semantics of regions from the influence of irrelevant tokens, eliminating the confusion of non-corresponding attributes. In the SPDiffusion framework, we design a Semantic Protection Mask (SP-Mask) to represent the relevance of the regions and the tokens, and propose a Semantic Protection Cross-Attention (SP-Attn) to shield the influence of irrelevant tokens on specific regions in the generation process. To evaluate our method, we created a diverse multi-concept benchmark, and SPDiffusion achieves state-of-the-art results on this benchmark, proving its effectiveness. Our method can be combined with many other application methods or backbones, such as ControlNet, Story Diffusion, PhotoMaker and PixArt-alpha to enhance their multi-concept capabilities, demonstrating strong compatibility and scalability.
The SkatingVerse Workshop & Challenge: Methods and Results
May 27, 2024

The SkatingVerse Workshop & Challenge aims to encourage research in developing novel and accurate methods for human action understanding. The SkatingVerse dataset used for the SkatingVerse Challenge has been publicly released. There are two subsets in the dataset, i.e., the training subset and testing subset. The training subsets consists of 19,993 RGB video sequences, and the testing subsets consists of 8,586 RGB video sequences. Around 10 participating teams from the globe competed in the SkatingVerse Challenge. In this paper, we provide a brief summary of the SkatingVerse Workshop & Challenge including brief introductions to the top three methods. The submission leaderboard will be reopened for researchers that are interested in the human action understanding challenge. The benchmark dataset and other information can be found at: https://skatingverse.github.io/.
BlazeBVD: Make Scale-Time Equalization Great Again for Blind Video Deflickering
Mar 10, 2024



Developing blind video deflickering (BVD) algorithms to enhance video temporal consistency, is gaining importance amid the flourish of image processing and video generation. However, the intricate nature of video data complicates the training of deep learning methods, leading to high resource consumption and instability, notably under severe lighting flicker. This underscores the critical need for a compact representation beyond pixel values to advance BVD research and applications. Inspired by the classic scale-time equalization (STE), our work introduces the histogram-assisted solution, called BlazeBVD, for high-fidelity and rapid BVD. Compared with STE, which directly corrects pixel values by temporally smoothing color histograms, BlazeBVD leverages smoothed illumination histograms within STE filtering to ease the challenge of learning temporal data using neural networks. In technique, BlazeBVD begins by condensing pixel values into illumination histograms that precisely capture flickering and local exposure variations. These histograms are then smoothed to produce singular frames set, filtered illumination maps, and exposure maps. Resorting to these deflickering priors, BlazeBVD utilizes a 2D network to restore faithful and consistent texture impacted by lighting changes or localized exposure issues. BlazeBVD also incorporates a lightweight 3D network to amend slight temporal inconsistencies, avoiding the resource consumption issue. Comprehensive experiments on synthetic, real-world and generated videos, showcase the superior qualitative and quantitative results of BlazeBVD, achieving inference speeds up to 10x faster than state-of-the-arts.
Customize your NeRF: Adaptive Source Driven 3D Scene Editing via Local-Global Iterative Training
Dec 04, 2023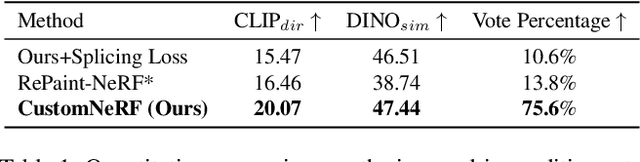
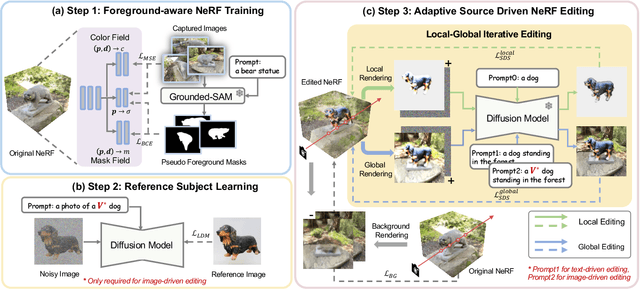


In this paper, we target the adaptive source driven 3D scene editing task by proposing a CustomNeRF model that unifies a text description or a reference image as the editing prompt. However, obtaining desired editing results conformed with the editing prompt is nontrivial since there exist two significant challenges, including accurate editing of only foreground regions and multi-view consistency given a single-view reference image. To tackle the first challenge, we propose a Local-Global Iterative Editing (LGIE) training scheme that alternates between foreground region editing and full-image editing, aimed at foreground-only manipulation while preserving the background. For the second challenge, we also design a class-guided regularization that exploits class priors within the generation model to alleviate the inconsistency problem among different views in image-driven editing. Extensive experiments show that our CustomNeRF produces precise editing results under various real scenes for both text- and image-driven settings.
Towards Consistent Video Editing with Text-to-Image Diffusion Models
May 27, 2023
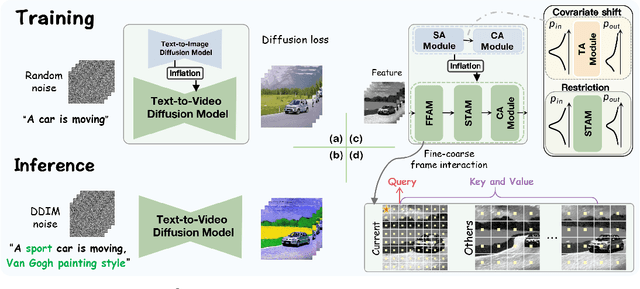


Existing works have advanced Text-to-Image (TTI) diffusion models for video editing in a one-shot learning manner. Despite their low requirements of data and computation, these methods might produce results of unsatisfied consistency with text prompt as well as temporal sequence, limiting their applications in the real world. In this paper, we propose to address the above issues with a novel EI$^2$ model towards \textbf{E}nhancing v\textbf{I}deo \textbf{E}diting cons\textbf{I}stency of TTI-based frameworks. Specifically, we analyze and find that the inconsistent problem is caused by newly added modules into TTI models for learning temporal information. These modules lead to covariate shift in the feature space, which harms the editing capability. Thus, we design EI$^2$ to tackle the above drawbacks with two classical modules: Shift-restricted Temporal Attention Module (STAM) and Fine-coarse Frame Attention Module (FFAM). First, through theoretical analysis, we demonstrate that covariate shift is highly related to Layer Normalization, thus STAM employs a \textit{Instance Centering} layer replacing it to preserve the distribution of temporal features. In addition, {STAM} employs an attention layer with normalized mapping to transform temporal features while constraining the variance shift. As the second part, we incorporate {STAM} with a novel {FFAM}, which efficiently leverages fine-coarse spatial information of overall frames to further enhance temporal consistency. Extensive experiments demonstrate the superiority of the proposed EI$^2$ model for text-driven video editing.
DiffBFR: Bootstrapping Diffusion Model Towards Blind Face Restoration
May 08, 2023
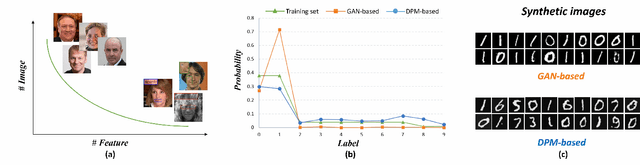
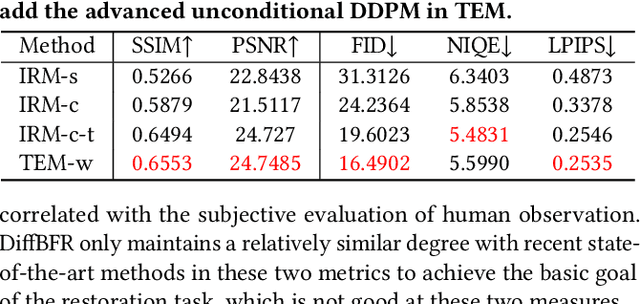
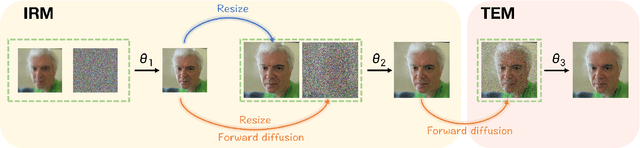
Blind face restoration (BFR) is important while challenging. Prior works prefer to exploit GAN-based frameworks to tackle this task due to the balance of quality and efficiency. However, these methods suffer from poor stability and adaptability to long-tail distribution, failing to simultaneously retain source identity and restore detail. We propose DiffBFR to introduce Diffusion Probabilistic Model (DPM) for BFR to tackle the above problem, given its superiority over GAN in aspects of avoiding training collapse and generating long-tail distribution. DiffBFR utilizes a two-step design, that first restores identity information from low-quality images and then enhances texture details according to the distribution of real faces. This design is implemented with two key components: 1) Identity Restoration Module (IRM) for preserving the face details in results. Instead of denoising from pure Gaussian random distribution with LQ images as the condition during the reverse process, we propose a novel truncated sampling method which starts from LQ images with part noise added. We theoretically prove that this change shrinks the evidence lower bound of DPM and then restores more original details. With theoretical proof, two cascade conditional DPMs with different input sizes are introduced to strengthen this sampling effect and reduce training difficulty in the high-resolution image generated directly. 2) Texture Enhancement Module (TEM) for polishing the texture of the image. Here an unconditional DPM, a LQ-free model, is introduced to further force the restorations to appear realistic. We theoretically proved that this unconditional DPM trained on pure HQ images contributes to justifying the correct distribution of inference images output from IRM in pixel-level space. Truncated sampling with fractional time step is utilized to polish pixel-level textures while preserving identity information.
StyO: Stylize Your Face in Only One-Shot
Mar 07, 2023



This paper focuses on face stylization with a single artistic target. Existing works for this task often fail to retain the source content while achieving geometry variation. Here, we present a novel StyO model, ie. Stylize the face in only One-shot, to solve the above problem. In particular, StyO exploits a disentanglement and recombination strategy. It first disentangles the content and style of source and target images into identifiers, which are then recombined in a cross manner to derive the stylized face image. In this way, StyO decomposes complex images into independent and specific attributes, and simplifies one-shot face stylization as the combination of different attributes from input images, thus producing results better matching face geometry of target image and content of source one. StyO is implemented with latent diffusion models (LDM) and composed of two key modules: 1) Identifier Disentanglement Learner (IDL) for disentanglement phase. It represents identifiers as contrastive text prompts, ie. positive and negative descriptions. And it introduces a novel triple reconstruction loss to fine-tune the pre-trained LDM for encoding style and content into corresponding identifiers; 2) Fine-grained Content Controller (FCC) for the recombination phase. It recombines disentangled identifiers from IDL to form an augmented text prompt for generating stylized faces. In addition, FCC also constrains the cross-attention maps of latent and text features to preserve source face details in results. The extensive evaluation shows that StyO produces high-quality images on numerous paintings of various styles and outperforms the current state-of-the-art. Code will be released upon acceptance.
Masked Reconstruction Contrastive Learning with Information Bottleneck Principle
Nov 15, 2022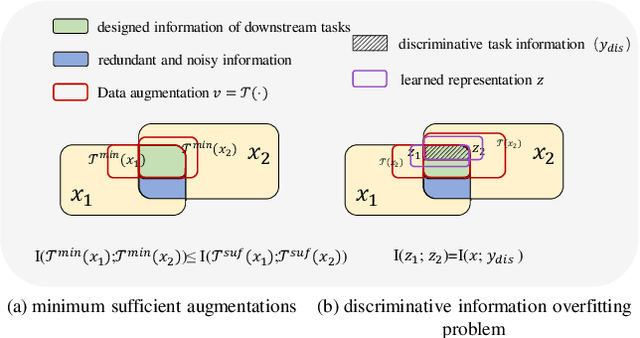
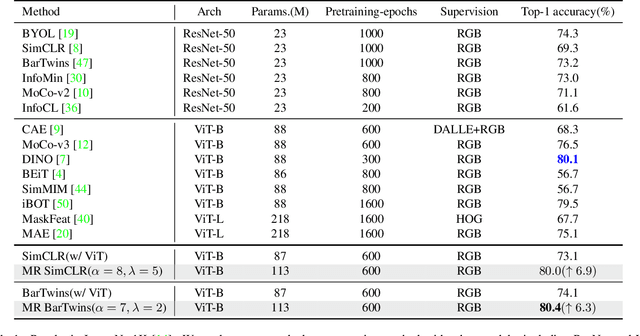
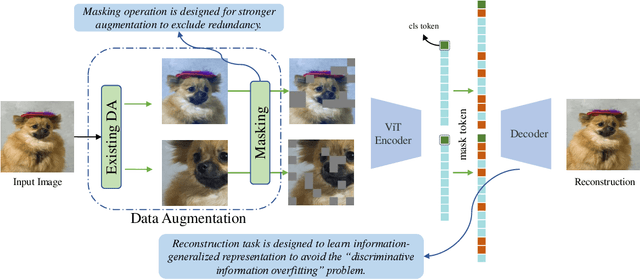
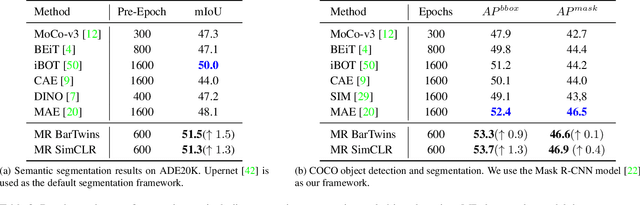
Contrastive learning (CL) has shown great power in self-supervised learning due to its ability to capture insight correlations among large-scale data. Current CL models are biased to learn only the ability to discriminate positive and negative pairs due to the discriminative task setting. However, this bias would lead to ignoring its sufficiency for other downstream tasks, which we call the discriminative information overfitting problem. In this paper, we propose to tackle the above problems from the aspect of the Information Bottleneck (IB) principle, further pushing forward the frontier of CL. Specifically, we present a new perspective that CL is an instantiation of the IB principle, including information compression and expression. We theoretically analyze the optimal information situation and demonstrate that minimum sufficient augmentation and information-generalized representation are the optimal requirements for achieving maximum compression and generalizability to downstream tasks. Therefore, we propose the Masked Reconstruction Contrastive Learning~(MRCL) model to improve CL models. For implementation in practice, MRCL utilizes the masking operation for stronger augmentation, further eliminating redundant and noisy information. In order to alleviate the discriminative information overfitting problem effectively, we employ the reconstruction task to regularize the discriminative task. We conduct comprehensive experiments and show the superiority of the proposed model on multiple tasks, including image classification, semantic segmentation and objective detection.