 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePurity Law for Generalizable Neural TSP Solvers
May 07, 2025Achieving generalization in neural approaches across different scales and distributions remains a significant challenge for the Traveling Salesman Problem~(TSP). A key obstacle is that neural networks often fail to learn robust principles for identifying universal patterns and deriving optimal solutions from diverse instances. In this paper, we first uncover Purity Law (PuLa), a fundamental structural principle for optimal TSP solutions, defining that edge prevalence grows exponentially with the sparsity of surrounding vertices. Statistically validated across diverse instances, PuLa reveals a consistent bias toward local sparsity in global optima. Building on this insight, we propose Purity Policy Optimization~(PUPO), a novel training paradigm that explicitly aligns characteristics of neural solutions with PuLa during the solution construction process to enhance generalization. Extensive experiments demonstrate that PUPO can be seamlessly integrated with popular neural solvers, significantly enhancing their generalization performance without incurring additional computational overhead during inference.
Towards Optimal Adversarial Robust Reinforcement Learning with Infinity Measurement Error
Feb 23, 2025


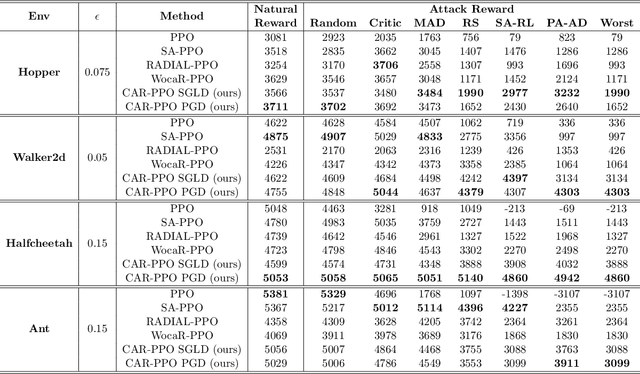
Ensuring the robustness of deep reinforcement learning (DRL) agents against adversarial attacks is critical for their trustworthy deployment. Recent research highlights the challenges of achieving state-adversarial robustness and suggests that an optimal robust policy (ORP) does not always exist, complicating the enforcement of strict robustness constraints. In this paper, we further explore the concept of ORP. We first introduce the Intrinsic State-adversarial Markov Decision Process (ISA-MDP), a novel formulation where adversaries cannot fundamentally alter the intrinsic nature of state observations. ISA-MDP, supported by empirical and theoretical evidence, universally characterizes decision-making under state-adversarial paradigms. We rigorously prove that within ISA-MDP, a deterministic and stationary ORP exists, aligning with the Bellman optimal policy. Our findings theoretically reveal that improving DRL robustness does not necessarily compromise performance in natural environments. Furthermore, we demonstrate the necessity of infinity measurement error (IME) in both $Q$-function and probability spaces to achieve ORP, unveiling vulnerabilities of previous DRL algorithms that rely on $1$-measurement errors. Motivated by these insights, we develop the Consistent Adversarial Robust Reinforcement Learning (CAR-RL) framework, which optimizes surrogates of IME. We apply CAR-RL to both value-based and policy-based DRL algorithms, achieving superior performance and validating our theoretical analysis.
Dual Alignment Maximin Optimization for Offline Model-based RL
Feb 02, 2025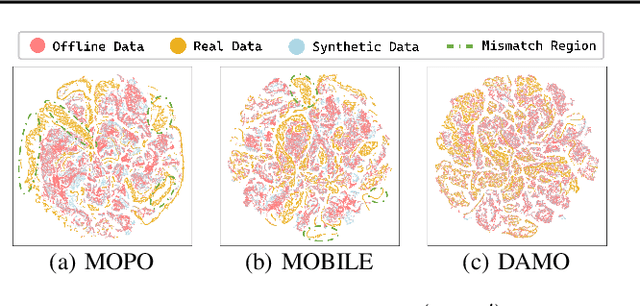
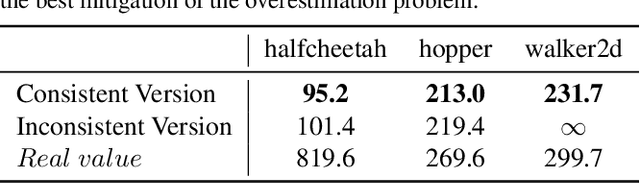
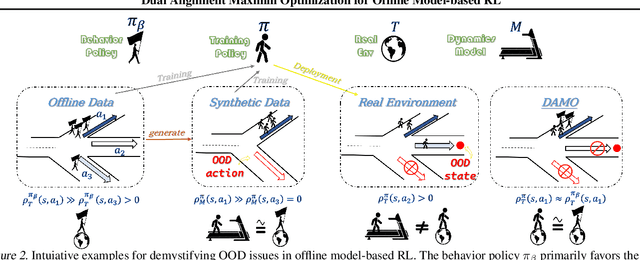
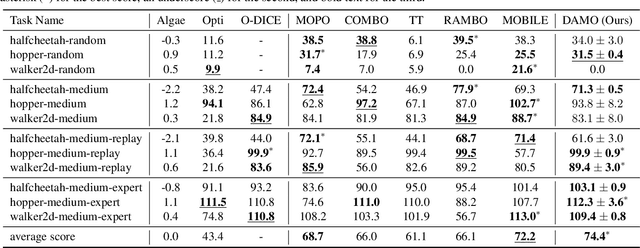
Offline reinforcement learning agents face significant deployment challenges due to the synthetic-to-real distribution mismatch. While most prior research has focused on improving the fidelity of synthetic sampling and incorporating off-policy mechanisms, the directly integrated paradigm often fails to ensure consistent policy behavior in biased models and underlying environmental dynamics, which inherently arise from discrepancies between behavior and learning policies. In this paper, we first shift the focus from model reliability to policy discrepancies while optimizing for expected returns, and then self-consistently incorporate synthetic data, deriving a novel actor-critic paradigm, Dual Alignment Maximin Optimization (DAMO). It is a unified framework to ensure both model-environment policy consistency and synthetic and offline data compatibility. The inner minimization performs dual conservative value estimation, aligning policies and trajectories to avoid out-of-distribution states and actions, while the outer maximization ensures that policy improvements remain consistent with inner value estimates. Empirical evaluations demonstrate that DAMO effectively ensures model and policy alignments, achieving competitive performance across diverse benchmark tasks.
Preference-based opponent shaping in differentiable games
Dec 04, 2024



Strategy learning in game environments with multi-agent is a challenging problem. Since each agent's reward is determined by the joint strategy, a greedy learning strategy that aims to maximize its own reward may fall into a local optimum. Recent studies have proposed the opponent modeling and shaping methods for game environments. These methods enhance the efficiency of strategy learning by modeling the strategies and updating processes of other agents. However, these methods often rely on simple predictions of opponent strategy changes. Due to the lack of modeling behavioral preferences such as cooperation and competition, they are usually applicable only to predefined scenarios and lack generalization capabilities. In this paper, we propose a novel Preference-based Opponent Shaping (PBOS) method to enhance the strategy learning process by shaping agents' preferences towards cooperation. We introduce the preference parameter, which is incorporated into the agent's loss function, thus allowing the agent to directly consider the opponent's loss function when updating the strategy. We update the preference parameters concurrently with strategy learning to ensure that agents can adapt to any cooperative or competitive game environment. Through a series of experiments, we verify the performance of PBOS algorithm in a variety of differentiable games. The experimental results show that the PBOS algorithm can guide the agent to learn the appropriate preference parameters, so as to achieve better reward distribution in multiple game environments.
DR-BFR: Degradation Representation with Diffusion Models for Blind Face Restoration
Nov 15, 2024



Blind face restoration (BFR) is fundamentally challenged by the extensive range of degradation types and degrees that impact model generalization. Recent advancements in diffusion models have made considerable progress in this field. Nevertheless, a critical limitation is their lack of awareness of specific degradation, leading to potential issues such as unnatural details and inaccurate textures. In this paper, we equip diffusion models with the capability to decouple various degradation as a degradation prompt from low-quality (LQ) face images via unsupervised contrastive learning with reconstruction loss, and demonstrate that this capability significantly improves performance, particularly in terms of the naturalness of the restored images. Our novel restoration scheme, named DR-BFR, guides the denoising of Latent Diffusion Models (LDM) by incorporating Degradation Representation (DR) and content features from LQ images. DR-BFR comprises two modules: 1) Degradation Representation Module (DRM): This module extracts degradation representation with content-irrelevant features from LQ faces and estimates a reasonable distribution in the degradation space through contrastive learning and a specially designed LQ reconstruction. 2) Latent Diffusion Restoration Module (LDRM): This module perceives both degradation features and content features in the latent space, enabling the restoration of high-quality images from LQ inputs. Our experiments demonstrate that the proposed DR-BFR significantly outperforms state-of-the-art methods quantitatively and qualitatively across various datasets. The DR effectively distinguishes between various degradations in blind face inverse problems and provides a reasonably powerful prompt to LDM.
SAMBO-RL: Shifts-aware Model-based Offline Reinforcement Learning
Aug 23, 2024Model-based Offline Reinforcement Learning trains policies based on offline datasets and model dynamics, without direct real-world environment interactions. However, this method is inherently challenged by distribution shift. Previous approaches have primarily focused on tackling this issue directly leveraging off-policy mechanisms and heuristic uncertainty in model dynamics, but they resulted in inconsistent objectives and lacked a unified theoretical foundation. This paper offers a comprehensive analysis that disentangles the problem into two key components: model bias and policy shift. We provide both theoretical insights and empirical evidence to demonstrate how these factors lead to inaccuracies in value function estimation and impose implicit restrictions on policy learning. To address these challenges, we derive adjustment terms for model bias and policy shift within a unified probabilistic inference framework. These adjustments are seamlessly integrated into the vanilla reward function to create a novel Shifts-aware Reward (SAR), aiming at refining value learning and facilitating policy training. Furthermore, we introduce Shifts-aware Model-based Offline Reinforcement Learning (SAMBO-RL), a practical framework that efficiently trains classifiers to approximate the SAR for policy optimization. Empirically, we show that SAR effectively mitigates distribution shift, and SAMBO-RL demonstrates superior performance across various benchmarks, underscoring its practical effectiveness and validating our theoretical analysis.
BlazeBVD: Make Scale-Time Equalization Great Again for Blind Video Deflickering
Mar 10, 2024



Developing blind video deflickering (BVD) algorithms to enhance video temporal consistency, is gaining importance amid the flourish of image processing and video generation. However, the intricate nature of video data complicates the training of deep learning methods, leading to high resource consumption and instability, notably under severe lighting flicker. This underscores the critical need for a compact representation beyond pixel values to advance BVD research and applications. Inspired by the classic scale-time equalization (STE), our work introduces the histogram-assisted solution, called BlazeBVD, for high-fidelity and rapid BVD. Compared with STE, which directly corrects pixel values by temporally smoothing color histograms, BlazeBVD leverages smoothed illumination histograms within STE filtering to ease the challenge of learning temporal data using neural networks. In technique, BlazeBVD begins by condensing pixel values into illumination histograms that precisely capture flickering and local exposure variations. These histograms are then smoothed to produce singular frames set, filtered illumination maps, and exposure maps. Resorting to these deflickering priors, BlazeBVD utilizes a 2D network to restore faithful and consistent texture impacted by lighting changes or localized exposure issues. BlazeBVD also incorporates a lightweight 3D network to amend slight temporal inconsistencies, avoiding the resource consumption issue. Comprehensive experiments on synthetic, real-world and generated videos, showcase the superior qualitative and quantitative results of BlazeBVD, achieving inference speeds up to 10x faster than state-of-the-arts.
Learning Dynamic Tetrahedra for High-Quality Talking Head Synthesis
Feb 27, 2024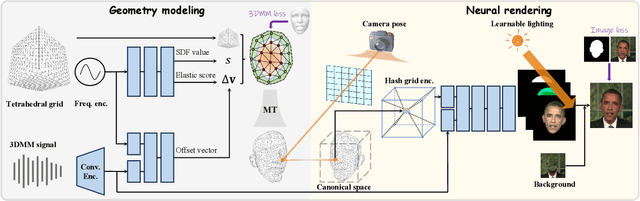
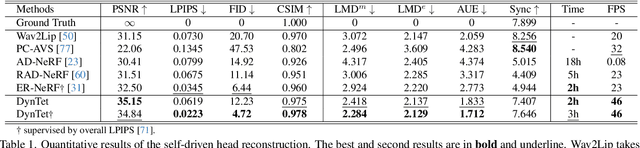

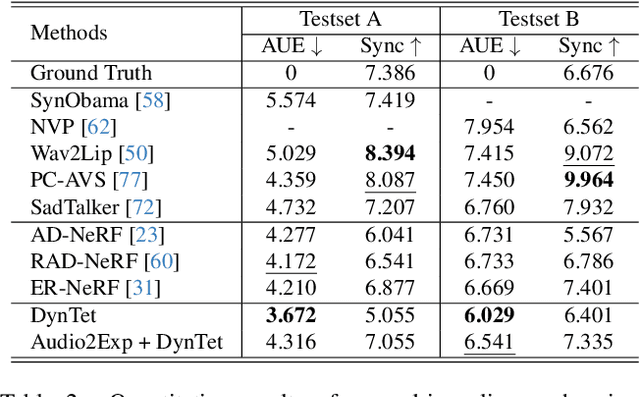
Recent works in implicit representations, such as Neural Radiance Fields (NeRF), have advanced the generation of realistic and animatable head avatars from video sequences. These implicit methods are still confronted by visual artifacts and jitters, since the lack of explicit geometric constraints poses a fundamental challenge in accurately modeling complex facial deformations. In this paper, we introduce Dynamic Tetrahedra (DynTet), a novel hybrid representation that encodes explicit dynamic meshes by neural networks to ensure geometric consistency across various motions and viewpoints. DynTet is parameterized by the coordinate-based networks which learn signed distance, deformation, and material texture, anchoring the training data into a predefined tetrahedra grid. Leveraging Marching Tetrahedra, DynTet efficiently decodes textured meshes with a consistent topology, enabling fast rendering through a differentiable rasterizer and supervision via a pixel loss. To enhance training efficiency, we incorporate classical 3D Morphable Models to facilitate geometry learning and define a canonical space for simplifying texture learning. These advantages are readily achievable owing to the effective geometric representation employed in DynTet. Compared with prior works, DynTet demonstrates significant improvements in fidelity, lip synchronization, and real-time performance according to various metrics. Beyond producing stable and visually appealing synthesis videos, our method also outputs the dynamic meshes which is promising to enable many emerging applications.
Understanding Oversmoothing in Diffusion-Based GNNs From the Perspective of Operator Semigroup Theory
Feb 23, 2024



This paper presents a novel study of the oversmoothing issue in diffusion-based Graph Neural Networks (GNNs). Diverging from extant approaches grounded in random walk analysis or particle systems, we approach this problem through operator semigroup theory. This theoretical framework allows us to rigorously prove that oversmoothing is intrinsically linked to the ergodicity of the diffusion operator. This finding further poses a general and mild ergodicity-breaking condition, encompassing the various specific solutions previously offered, thereby presenting a more universal and theoretically grounded approach to mitigating oversmoothing in diffusion-based GNNs. Additionally, we offer a probabilistic interpretation of our theory, forging a link with prior works and broadening the theoretical horizon. Our experimental results reveal that this ergodicity-breaking term effectively mitigates oversmoothing measured by Dirichlet energy, and simultaneously enhances performance in node classification tasks.
Towards Optimal Adversarial Robust Q-learning with Bellman Infinity-error
Feb 03, 2024Establishing robust policies is essential to counter attacks or disturbances affecting deep reinforcement learning (DRL) agents. Recent studies explore state-adversarial robustness and suggest the potential lack of an optimal robust policy (ORP), posing challenges in setting strict robustness constraints. This work further investigates ORP: At first, we introduce a consistency assumption of policy (CAP) stating that optimal actions in the Markov decision process remain consistent with minor perturbations, supported by empirical and theoretical evidence. Building upon CAP, we crucially prove the existence of a deterministic and stationary ORP that aligns with the Bellman optimal policy. Furthermore, we illustrate the necessity of $L^{\infty}$-norm when minimizing Bellman error to attain ORP. This finding clarifies the vulnerability of prior DRL algorithms that target the Bellman optimal policy with $L^{1}$-norm and motivates us to train a Consistent Adversarial Robust Deep Q-Network (CAR-DQN) by minimizing a surrogate of Bellman Infinity-error. The top-tier performance of CAR-DQN across various benchmarks validates its practical effectiveness and reinforces the soundness of our theoretical analysis.