 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMSPCaps: A Multi-Scale Patchify Capsule Network with Cross-Agreement Routing for Visual Recognition
Aug 23, 2025Capsule Network (CapsNet) has demonstrated significant potential in visual recognition by capturing spatial relationships and part-whole hierarchies for learning equivariant feature representations. However, existing CapsNet and variants often rely on a single high-level feature map, overlooking the rich complementary information from multi-scale features. Furthermore, conventional feature fusion strategies (e.g., addition and concatenation) struggle to reconcile multi-scale feature discrepancies, leading to suboptimal classification performance. To address these limitations, we propose the Multi-Scale Patchify Capsule Network (MSPCaps), a novel architecture that integrates multi-scale feature learning and efficient capsule routing. Specifically, MSPCaps consists of three key components: a Multi-Scale ResNet Backbone (MSRB), a Patchify Capsule Layer (PatchifyCaps), and Cross-Agreement Routing (CAR) blocks. First, the MSRB extracts diverse multi-scale feature representations from input images, preserving both fine-grained details and global contextual information. Second, the PatchifyCaps partitions these multi-scale features into primary capsules using a uniform patch size, equipping the model with the ability to learn from diverse receptive fields. Finally, the CAR block adaptively routes the multi-scale capsules by identifying cross-scale prediction pairs with maximum agreement. Unlike the simple concatenation of multiple self-routing blocks, CAR ensures that only the most coherent capsules contribute to the final voting. Our proposed MSPCaps achieves remarkable scalability and superior robustness, consistently surpassing multiple baseline methods in terms of classification accuracy, with configurations ranging from a highly efficient Tiny model (344.3K parameters) to a powerful Large model (10.9M parameters), highlighting its potential in advancing feature representation learning.
Towards Optimal Adversarial Robust Reinforcement Learning with Infinity Measurement Error
Feb 23, 2025


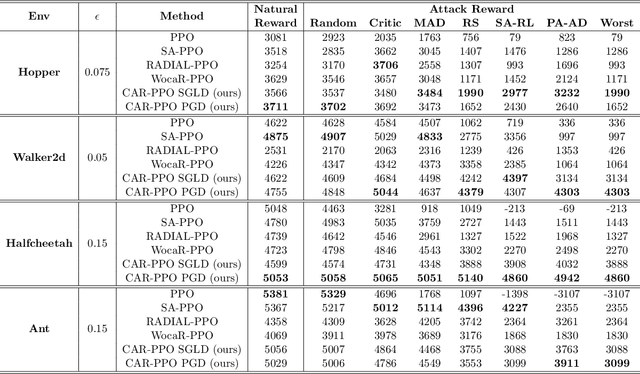
Ensuring the robustness of deep reinforcement learning (DRL) agents against adversarial attacks is critical for their trustworthy deployment. Recent research highlights the challenges of achieving state-adversarial robustness and suggests that an optimal robust policy (ORP) does not always exist, complicating the enforcement of strict robustness constraints. In this paper, we further explore the concept of ORP. We first introduce the Intrinsic State-adversarial Markov Decision Process (ISA-MDP), a novel formulation where adversaries cannot fundamentally alter the intrinsic nature of state observations. ISA-MDP, supported by empirical and theoretical evidence, universally characterizes decision-making under state-adversarial paradigms. We rigorously prove that within ISA-MDP, a deterministic and stationary ORP exists, aligning with the Bellman optimal policy. Our findings theoretically reveal that improving DRL robustness does not necessarily compromise performance in natural environments. Furthermore, we demonstrate the necessity of infinity measurement error (IME) in both $Q$-function and probability spaces to achieve ORP, unveiling vulnerabilities of previous DRL algorithms that rely on $1$-measurement errors. Motivated by these insights, we develop the Consistent Adversarial Robust Reinforcement Learning (CAR-RL) framework, which optimizes surrogates of IME. We apply CAR-RL to both value-based and policy-based DRL algorithms, achieving superior performance and validating our theoretical analysis.
Preference-based opponent shaping in differentiable games
Dec 04, 2024



Strategy learning in game environments with multi-agent is a challenging problem. Since each agent's reward is determined by the joint strategy, a greedy learning strategy that aims to maximize its own reward may fall into a local optimum. Recent studies have proposed the opponent modeling and shaping methods for game environments. These methods enhance the efficiency of strategy learning by modeling the strategies and updating processes of other agents. However, these methods often rely on simple predictions of opponent strategy changes. Due to the lack of modeling behavioral preferences such as cooperation and competition, they are usually applicable only to predefined scenarios and lack generalization capabilities. In this paper, we propose a novel Preference-based Opponent Shaping (PBOS) method to enhance the strategy learning process by shaping agents' preferences towards cooperation. We introduce the preference parameter, which is incorporated into the agent's loss function, thus allowing the agent to directly consider the opponent's loss function when updating the strategy. We update the preference parameters concurrently with strategy learning to ensure that agents can adapt to any cooperative or competitive game environment. Through a series of experiments, we verify the performance of PBOS algorithm in a variety of differentiable games. The experimental results show that the PBOS algorithm can guide the agent to learn the appropriate preference parameters, so as to achieve better reward distribution in multiple game environments.
Towards Optimal Adversarial Robust Q-learning with Bellman Infinity-error
Feb 03, 2024Establishing robust policies is essential to counter attacks or disturbances affecting deep reinforcement learning (DRL) agents. Recent studies explore state-adversarial robustness and suggest the potential lack of an optimal robust policy (ORP), posing challenges in setting strict robustness constraints. This work further investigates ORP: At first, we introduce a consistency assumption of policy (CAP) stating that optimal actions in the Markov decision process remain consistent with minor perturbations, supported by empirical and theoretical evidence. Building upon CAP, we crucially prove the existence of a deterministic and stationary ORP that aligns with the Bellman optimal policy. Furthermore, we illustrate the necessity of $L^{\infty}$-norm when minimizing Bellman error to attain ORP. This finding clarifies the vulnerability of prior DRL algorithms that target the Bellman optimal policy with $L^{1}$-norm and motivates us to train a Consistent Adversarial Robust Deep Q-Network (CAR-DQN) by minimizing a surrogate of Bellman Infinity-error. The top-tier performance of CAR-DQN across various benchmarks validates its practical effectiveness and reinforces the soundness of our theoretical analysis.