 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Optimal Adversarial Robust Reinforcement Learning with Infinity Measurement Error
Paper and Code



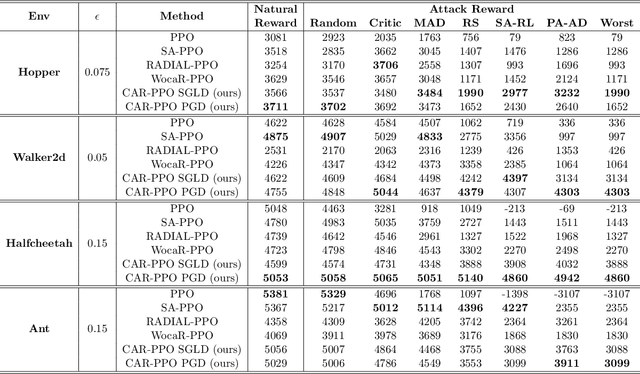
Ensuring the robustness of deep reinforcement learning (DRL) agents against adversarial attacks is critical for their trustworthy deployment. Recent research highlights the challenges of achieving state-adversarial robustness and suggests that an optimal robust policy (ORP) does not always exist, complicating the enforcement of strict robustness constraints. In this paper, we further explore the concept of ORP. We first introduce the Intrinsic State-adversarial Markov Decision Process (ISA-MDP), a novel formulation where adversaries cannot fundamentally alter the intrinsic nature of state observations. ISA-MDP, supported by empirical and theoretical evidence, universally characterizes decision-making under state-adversarial paradigms. We rigorously prove that within ISA-MDP, a deterministic and stationary ORP exists, aligning with the Bellman optimal policy. Our findings theoretically reveal that improving DRL robustness does not necessarily compromise performance in natural environments. Furthermore, we demonstrate the necessity of infinity measurement error (IME) in both $Q$-function and probability spaces to achieve ORP, unveiling vulnerabilities of previous DRL algorithms that rely on $1$-measurement errors. Motivated by these insights, we develop the Consistent Adversarial Robust Reinforcement Learning (CAR-RL) framework, which optimizes surrogates of IME. We apply CAR-RL to both value-based and policy-based DRL algorithms, achieving superior performance and validating our theoretical analysis.