 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Multimodal Point Cloud Completion: A Completion-by-Correction Perspective
Nov 15, 2025Point cloud completion aims to reconstruct complete 3D shapes from partial observations, which is a challenging problem due to severe occlusions and missing geometry. Despite recent advances in multimodal techniques that leverage complementary RGB images to compensate for missing geometry, most methods still follow a Completion-by-Inpainting paradigm, synthesizing missing structures from fused latent features. We empirically show that this paradigm often results in structural inconsistencies and topological artifacts due to limited geometric and semantic constraints. To address this, we rethink the task and propose a more robust paradigm, termed Completion-by-Correction, which begins with a topologically complete shape prior generated by a pretrained image-to-3D model and performs feature-space correction to align it with the partial observation. This paradigm shifts completion from unconstrained synthesis to guided refinement, enabling structurally consistent and observation-aligned reconstruction. Building upon this paradigm, we introduce PGNet, a multi-stage framework that conducts dual-feature encoding to ground the generative prior, synthesizes a coarse yet structurally aligned scaffold, and progressively refines geometric details via hierarchical correction. Experiments on the ShapeNetViPC dataset demonstrate the superiority of PGNet over state-of-the-art baselines in terms of average Chamfer Distance (-23.5%) and F-score (+7.1%).
Towards Optimal Adversarial Robust Reinforcement Learning with Infinity Measurement Error
Feb 23, 2025


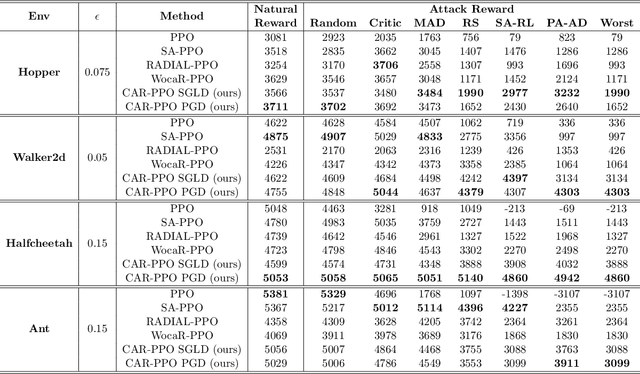
Ensuring the robustness of deep reinforcement learning (DRL) agents against adversarial attacks is critical for their trustworthy deployment. Recent research highlights the challenges of achieving state-adversarial robustness and suggests that an optimal robust policy (ORP) does not always exist, complicating the enforcement of strict robustness constraints. In this paper, we further explore the concept of ORP. We first introduce the Intrinsic State-adversarial Markov Decision Process (ISA-MDP), a novel formulation where adversaries cannot fundamentally alter the intrinsic nature of state observations. ISA-MDP, supported by empirical and theoretical evidence, universally characterizes decision-making under state-adversarial paradigms. We rigorously prove that within ISA-MDP, a deterministic and stationary ORP exists, aligning with the Bellman optimal policy. Our findings theoretically reveal that improving DRL robustness does not necessarily compromise performance in natural environments. Furthermore, we demonstrate the necessity of infinity measurement error (IME) in both $Q$-function and probability spaces to achieve ORP, unveiling vulnerabilities of previous DRL algorithms that rely on $1$-measurement errors. Motivated by these insights, we develop the Consistent Adversarial Robust Reinforcement Learning (CAR-RL) framework, which optimizes surrogates of IME. We apply CAR-RL to both value-based and policy-based DRL algorithms, achieving superior performance and validating our theoretical analysis.
Dual Alignment Maximin Optimization for Offline Model-based RL
Feb 02, 2025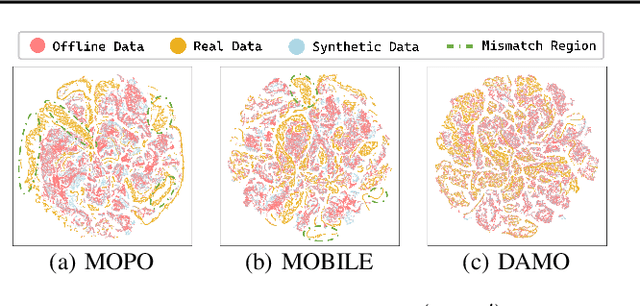
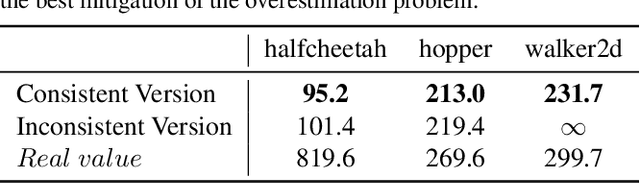
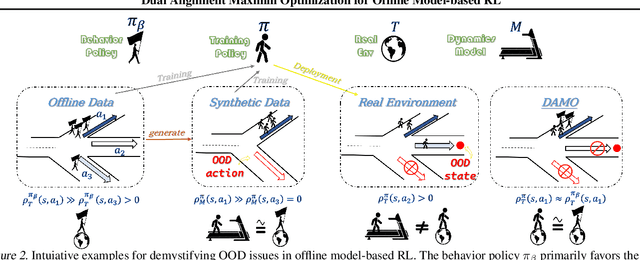
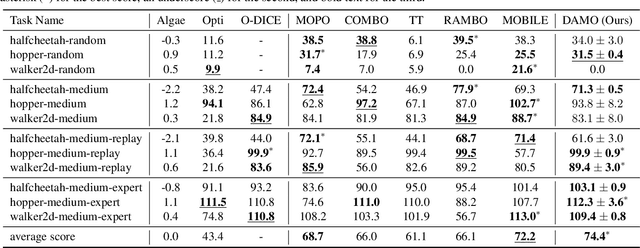
Offline reinforcement learning agents face significant deployment challenges due to the synthetic-to-real distribution mismatch. While most prior research has focused on improving the fidelity of synthetic sampling and incorporating off-policy mechanisms, the directly integrated paradigm often fails to ensure consistent policy behavior in biased models and underlying environmental dynamics, which inherently arise from discrepancies between behavior and learning policies. In this paper, we first shift the focus from model reliability to policy discrepancies while optimizing for expected returns, and then self-consistently incorporate synthetic data, deriving a novel actor-critic paradigm, Dual Alignment Maximin Optimization (DAMO). It is a unified framework to ensure both model-environment policy consistency and synthetic and offline data compatibility. The inner minimization performs dual conservative value estimation, aligning policies and trajectories to avoid out-of-distribution states and actions, while the outer maximization ensures that policy improvements remain consistent with inner value estimates. Empirical evaluations demonstrate that DAMO effectively ensures model and policy alignments, achieving competitive performance across diverse benchmark tasks.
SAMBO-RL: Shifts-aware Model-based Offline Reinforcement Learning
Aug 23, 2024Model-based Offline Reinforcement Learning trains policies based on offline datasets and model dynamics, without direct real-world environment interactions. However, this method is inherently challenged by distribution shift. Previous approaches have primarily focused on tackling this issue directly leveraging off-policy mechanisms and heuristic uncertainty in model dynamics, but they resulted in inconsistent objectives and lacked a unified theoretical foundation. This paper offers a comprehensive analysis that disentangles the problem into two key components: model bias and policy shift. We provide both theoretical insights and empirical evidence to demonstrate how these factors lead to inaccuracies in value function estimation and impose implicit restrictions on policy learning. To address these challenges, we derive adjustment terms for model bias and policy shift within a unified probabilistic inference framework. These adjustments are seamlessly integrated into the vanilla reward function to create a novel Shifts-aware Reward (SAR), aiming at refining value learning and facilitating policy training. Furthermore, we introduce Shifts-aware Model-based Offline Reinforcement Learning (SAMBO-RL), a practical framework that efficiently trains classifiers to approximate the SAR for policy optimization. Empirically, we show that SAR effectively mitigates distribution shift, and SAMBO-RL demonstrates superior performance across various benchmarks, underscoring its practical effectiveness and validating our theoretical analysis.
Towards Optimal Adversarial Robust Q-learning with Bellman Infinity-error
Feb 03, 2024Establishing robust policies is essential to counter attacks or disturbances affecting deep reinforcement learning (DRL) agents. Recent studies explore state-adversarial robustness and suggest the potential lack of an optimal robust policy (ORP), posing challenges in setting strict robustness constraints. This work further investigates ORP: At first, we introduce a consistency assumption of policy (CAP) stating that optimal actions in the Markov decision process remain consistent with minor perturbations, supported by empirical and theoretical evidence. Building upon CAP, we crucially prove the existence of a deterministic and stationary ORP that aligns with the Bellman optimal policy. Furthermore, we illustrate the necessity of $L^{\infty}$-norm when minimizing Bellman error to attain ORP. This finding clarifies the vulnerability of prior DRL algorithms that target the Bellman optimal policy with $L^{1}$-norm and motivates us to train a Consistent Adversarial Robust Deep Q-Network (CAR-DQN) by minimizing a surrogate of Bellman Infinity-error. The top-tier performance of CAR-DQN across various benchmarks validates its practical effectiveness and reinforces the soundness of our theoretical analysis.
Action Unit Memory Network for Weakly Supervised Temporal Action Localization
Apr 29, 2021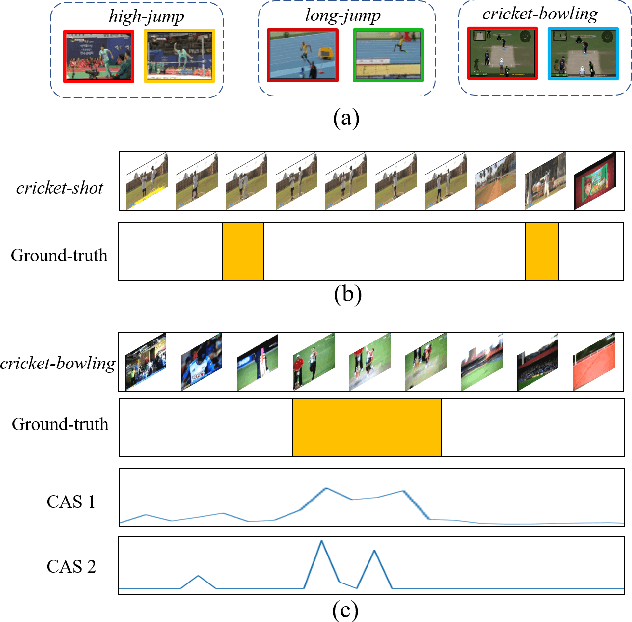

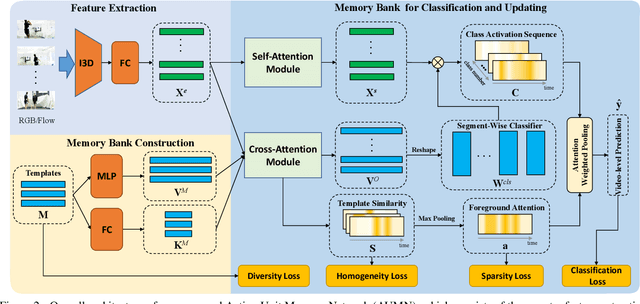

Weakly supervised temporal action localization aims to detect and localize actions in untrimmed videos with only video-level labels during training. However, without frame-level annotations, it is challenging to achieve localization completeness and relieve background interference. In this paper, we present an Action Unit Memory Network (AUMN) for weakly supervised temporal action localization, which can mitigate the above two challenges by learning an action unit memory bank. In the proposed AUMN, two attention modules are designed to update the memory bank adaptively and learn action units specific classifiers. Furthermore, three effective mechanisms (diversity, homogeneity and sparsity) are designed to guide the updating of the memory network. To the best of our knowledge, this is the first work to explicitly model the action units with a memory network. Extensive experimental results on two standard benchmarks (THUMOS14 and ActivityNet) demonstrate that our AUMN performs favorably against state-of-the-art methods. Specifically, the average mAP of IoU thresholds from 0.1 to 0.5 on the THUMOS14 dataset is significantly improved from 47.0% to 52.1%.