 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText-guided Eyeglasses Manipulation with Spatial Constraints
Apr 25, 2023Virtual try-on of eyeglasses involves placing eyeglasses of different shapes and styles onto a face image without physically trying them on. While existing methods have shown impressive results, the variety of eyeglasses styles is limited and the interactions are not always intuitive or efficient. To address these limitations, we propose a Text-guided Eyeglasses Manipulation method that allows for control of the eyeglasses shape and style based on a binary mask and text, respectively. Specifically, we introduce a mask encoder to extract mask conditions and a modulation module that enables simultaneous injection of text and mask conditions. This design allows for fine-grained control of the eyeglasses' appearance based on both textual descriptions and spatial constraints. Our approach includes a disentangled mapper and a decoupling strategy that preserves irrelevant areas, resulting in better local editing. We employ a two-stage training scheme to handle the different convergence speeds of the various modality conditions, successfully controlling both the shape and style of eyeglasses. Extensive comparison experiments and ablation analyses demonstrate the effectiveness of our approach in achieving diverse eyeglasses styles while preserving irrelevant areas.
Video2StyleGAN: Encoding Video in Latent Space for Manipulation
Jun 27, 2022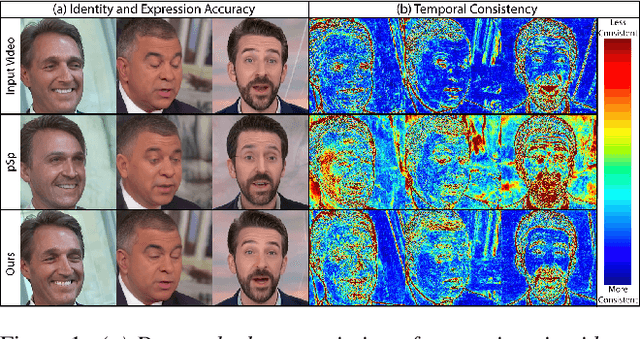
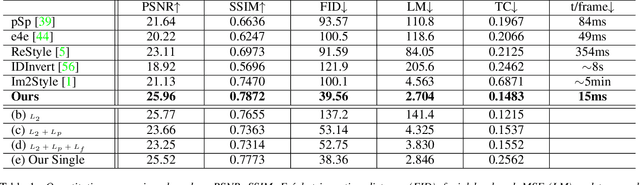
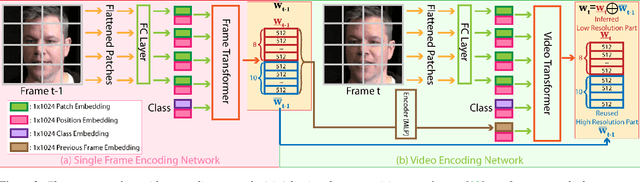
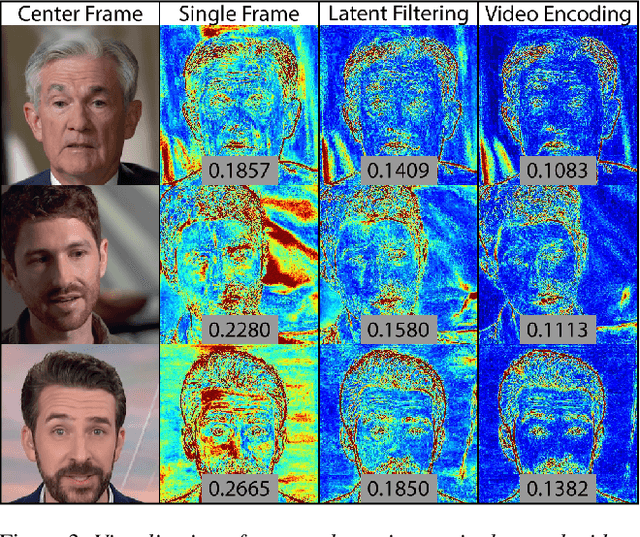
Many recent works have been proposed for face image editing by leveraging the latent space of pretrained GANs. However, few attempts have been made to directly apply them to videos, because 1) they do not guarantee temporal consistency, 2) their application is limited by their processing speed on videos, and 3) they cannot accurately encode details of face motion and expression. To this end, we propose a novel network to encode face videos into the latent space of StyleGAN for semantic face video manipulation. Based on the vision transformer, our network reuses the high-resolution portion of the latent vector to enforce temporal consistency. To capture subtle face motions and expressions, we design novel losses that involve sparse facial landmarks and dense 3D face mesh. We have thoroughly evaluated our approach and successfully demonstrated its application to various face video manipulations. Particularly, we propose a novel network for pose/expression control in a 3D coordinate system. Both qualitative and quantitative results have shown that our approach can significantly outperform existing single image methods, while achieving real-time (66 fps) speed.
A-ACT: Action Anticipation through Cycle Transformations
Apr 02, 2022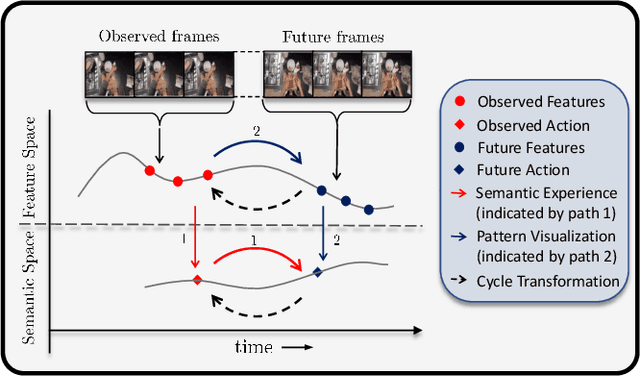
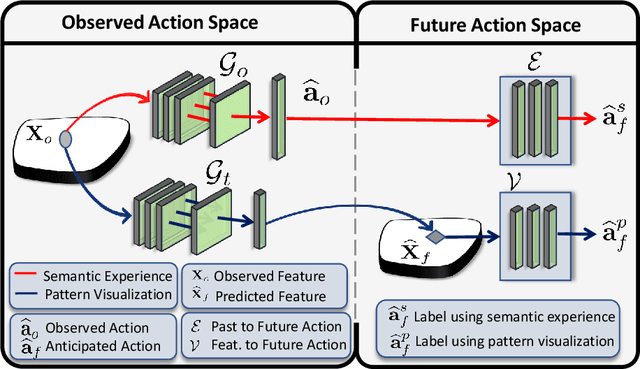
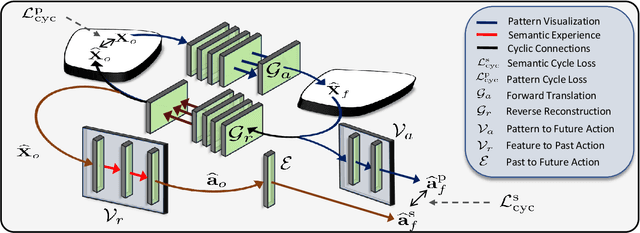
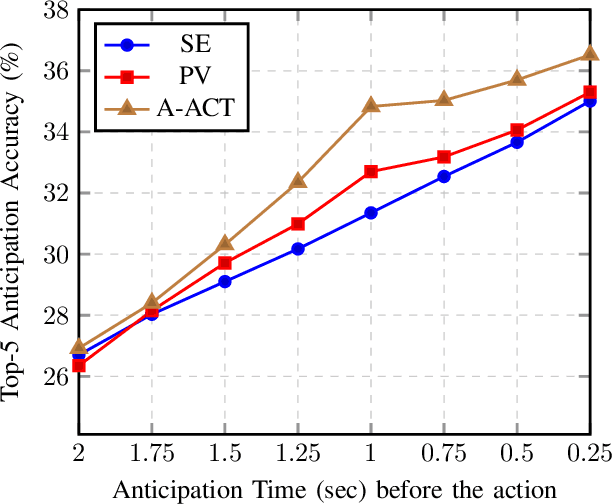
While action anticipation has garnered a lot of research interest recently, most of the works focus on anticipating future action directly through observed visual cues only. In this work, we take a step back to analyze how the human capability to anticipate the future can be transferred to machine learning algorithms. To incorporate this ability in intelligent systems a question worth pondering upon is how exactly do we anticipate? Is it by anticipating future actions from past experiences? Or is it by simulating possible scenarios based on cues from the present? A recent study on human psychology explains that, in anticipating an occurrence, the human brain counts on both systems. In this work, we study the impact of each system for the task of action anticipation and introduce a paradigm to integrate them in a learning framework. We believe that intelligent systems designed by leveraging the psychological anticipation models will do a more nuanced job at the task of human action prediction. Furthermore, we introduce cyclic transformation in the temporal dimension in feature and semantic label space to instill the human ability of reasoning of past actions based on the predicted future. Experiments on Epic-Kitchen, Breakfast, and 50Salads dataset demonstrate that the action anticipation model learned using a combination of the two systems along with the cycle transformation performs favorably against various state-of-the-art approaches.
Cross-modal Contrastive Distillation for Instructional Activity Anticipation
Jan 18, 2022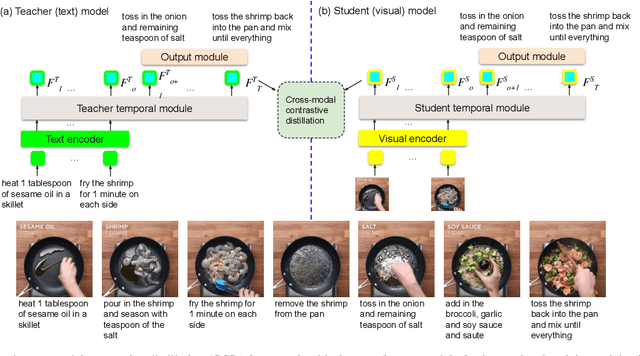
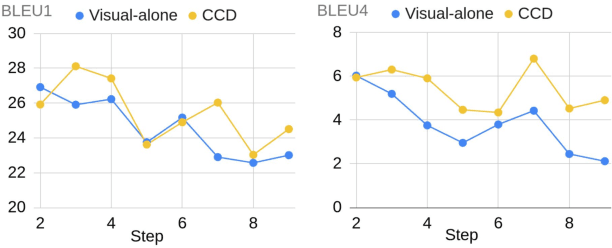

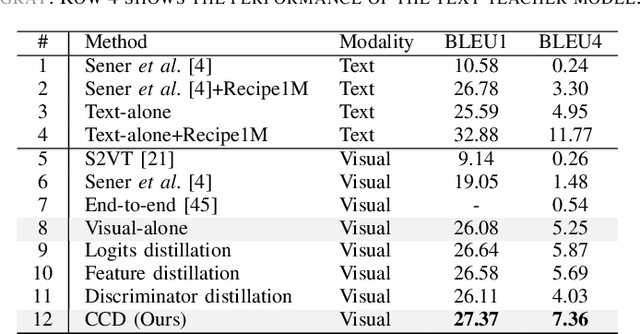
In this study, we aim to predict the plausible future action steps given an observation of the past and study the task of instructional activity anticipation. Unlike previous anticipation tasks that aim at action label prediction, our work targets at generating natural language outputs that provide interpretable and accurate descriptions of future action steps. It is a challenging task due to the lack of semantic information extracted from the instructional videos. To overcome this challenge, we propose a novel knowledge distillation framework to exploit the related external textual knowledge to assist the visual anticipation task. However, previous knowledge distillation techniques generally transfer information within the same modality. To bridge the gap between the visual and text modalities during the distillation process, we devise a novel cross-modal contrastive distillation (CCD) scheme, which facilitates knowledge distillation between teacher and student in heterogeneous modalities with the proposed cross-modal distillation loss. We evaluate our method on the Tasty Videos dataset. CCD improves the anticipation performance of the visual-alone student model by a large margin of 40.2% relatively in BLEU4. Our approach also outperforms the state-of-the-art approaches by a large margin.
Smart Director: An Event-Driven Directing System for Live Broadcasting
Jan 11, 2022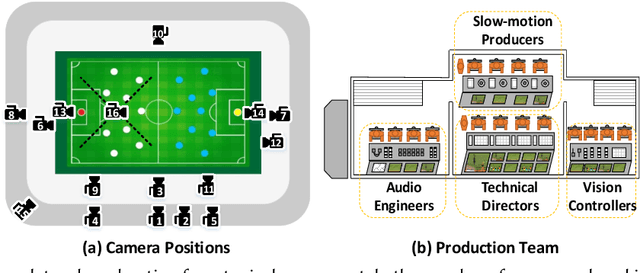
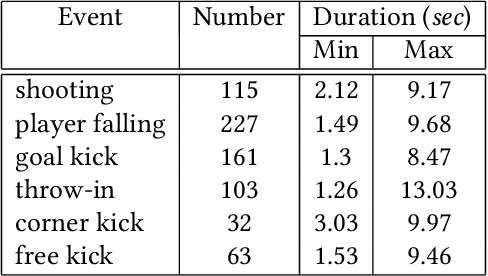
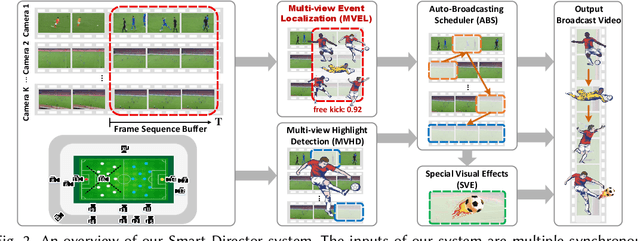
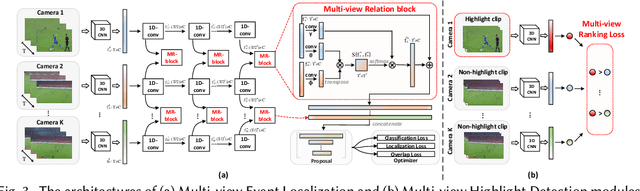
Live video broadcasting normally requires a multitude of skills and expertise with domain knowledge to enable multi-camera productions. As the number of cameras keep increasing, directing a live sports broadcast has now become more complicated and challenging than ever before. The broadcast directors need to be much more concentrated, responsive, and knowledgeable, during the production. To relieve the directors from their intensive efforts, we develop an innovative automated sports broadcast directing system, called Smart Director, which aims at mimicking the typical human-in-the-loop broadcasting process to automatically create near-professional broadcasting programs in real-time by using a set of advanced multi-view video analysis algorithms. Inspired by the so-called "three-event" construction of sports broadcast, we build our system with an event-driven pipeline consisting of three consecutive novel components: 1) the Multi-view Event Localization to detect events by modeling multi-view correlations, 2) the Multi-view Highlight Detection to rank camera views by the visual importance for view selection, 3) the Auto-Broadcasting Scheduler to control the production of broadcasting videos. To our best knowledge, our system is the first end-to-end automated directing system for multi-camera sports broadcasting, completely driven by the semantic understanding of sports events. It is also the first system to solve the novel problem of multi-view joint event detection by cross-view relation modeling. We conduct both objective and subjective evaluations on a real-world multi-camera soccer dataset, which demonstrate the quality of our auto-generated videos is comparable to that of the human-directed. Thanks to its faster response, our system is able to capture more fast-passing and short-duration events which are usually missed by human directors.
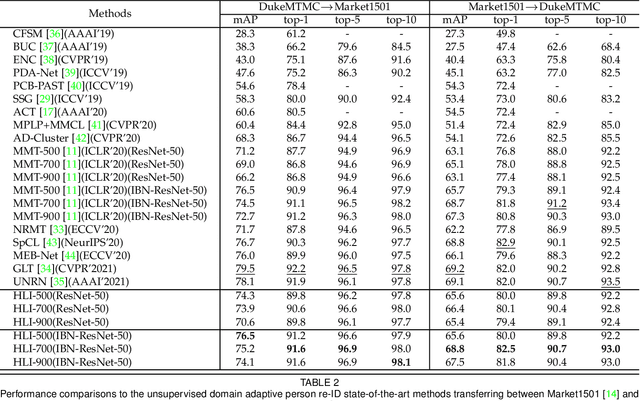
Unsupervised Domain Adaptive Person Re-Identification via Human Learning Imitation
Dec 05, 2021
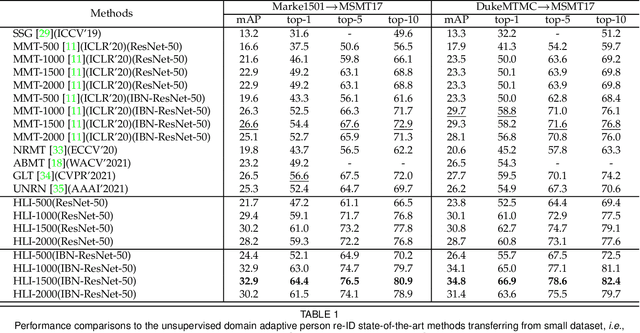
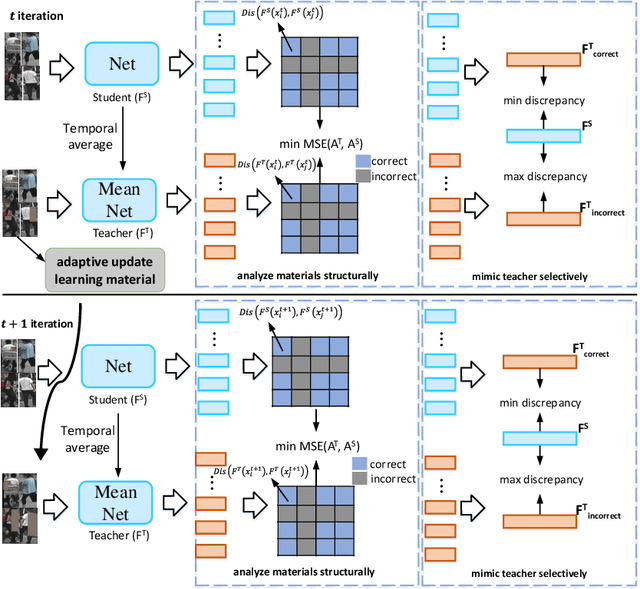
Unsupervised domain adaptive person re-identification has received significant attention due to its high practical value. In past years, by following the clustering and finetuning paradigm, researchers propose to utilize the teacher-student framework in their methods to decrease the domain gap between different person re-identification datasets. Inspired by recent teacher-student framework based methods, which try to mimic the human learning process either by making the student directly copy behavior from the teacher or selecting reliable learning materials, we propose to conduct further exploration to imitate the human learning process from different aspects, \textit{i.e.}, adaptively updating learning materials, selectively imitating teacher behaviors, and analyzing learning materials structures. The explored three components, collaborate together to constitute a new method for unsupervised domain adaptive person re-identification, which is called Human Learning Imitation framework. The experimental results on three benchmark datasets demonstrate the efficacy of our proposed method.
Automated Pulmonary Embolism Detection from CTPA Images Using an End-to-End Convolutional Neural Network
Nov 10, 2021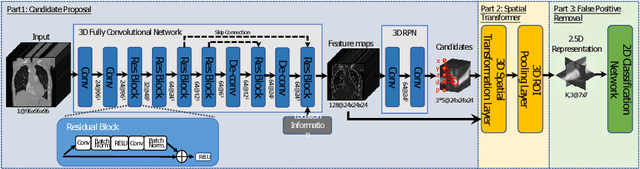
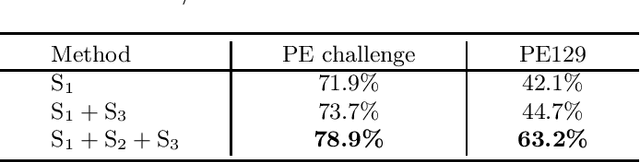
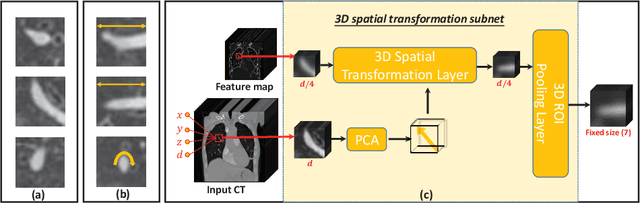
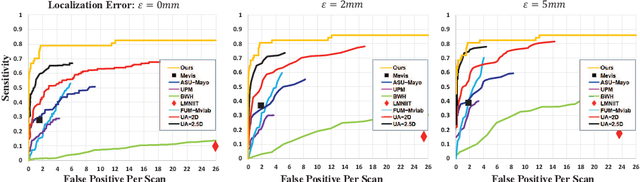
Automated methods for detecting pulmonary embolisms (PEs) on CT pulmonary angiography (CTPA) images are of high demand. Existing methods typically employ separate steps for PE candidate detection and false positive removal, without considering the ability of the other step. As a result, most existing methods usually suffer from a high false positive rate in order to achieve an acceptable sensitivity. This study presents an end-to-end trainable convolutional neural network (CNN) where the two steps are optimized jointly. The proposed CNN consists of three concatenated subnets: 1) a novel 3D candidate proposal network for detecting cubes containing suspected PEs, 2) a 3D spatial transformation subnet for generating fixed-sized vessel-aligned image representation for candidates, and 3) a 2D classification network which takes the three cross-sections of the transformed cubes as input and eliminates false positives. We have evaluated our approach using the 20 CTPA test dataset from the PE challenge, achieving a sensitivity of 78.9%, 80.7% and 80.7% at 2 false positives per volume at 0mm, 2mm and 5mm localization error, which is superior to the state-of-the-art methods. We have further evaluated our system on our own dataset consisting of 129 CTPA data with a total of 269 emboli. Our system achieves a sensitivity of 63.2%, 78.9% and 86.8% at 2 false positives per volume at 0mm, 2mm and 5mm localization error.
Trustworthy AI: From Principles to Practices
Oct 04, 2021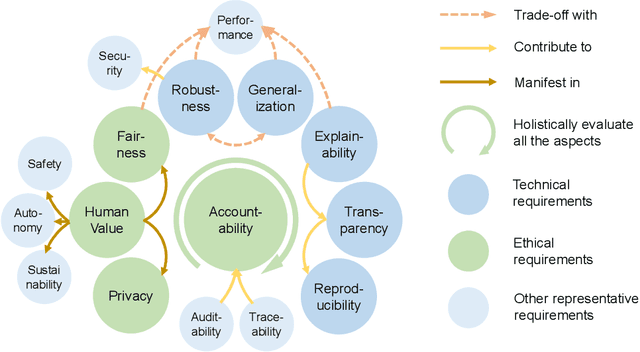
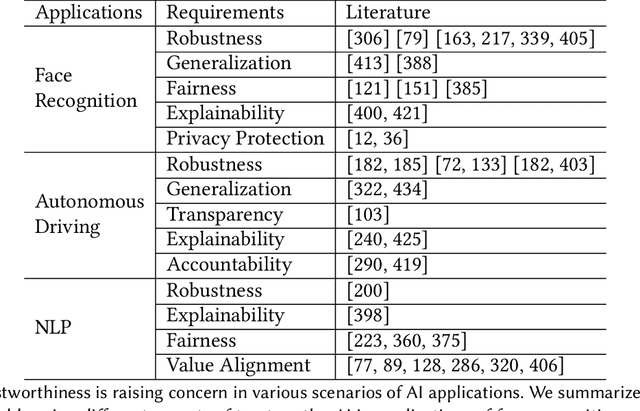
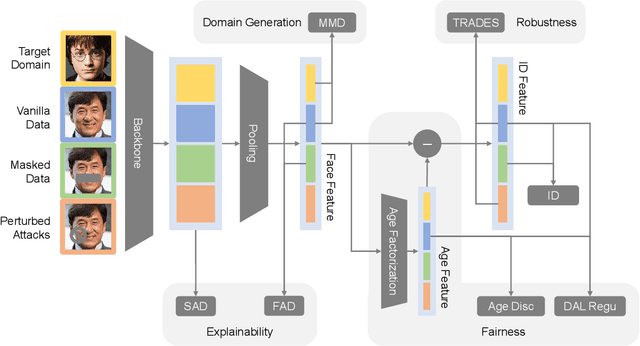
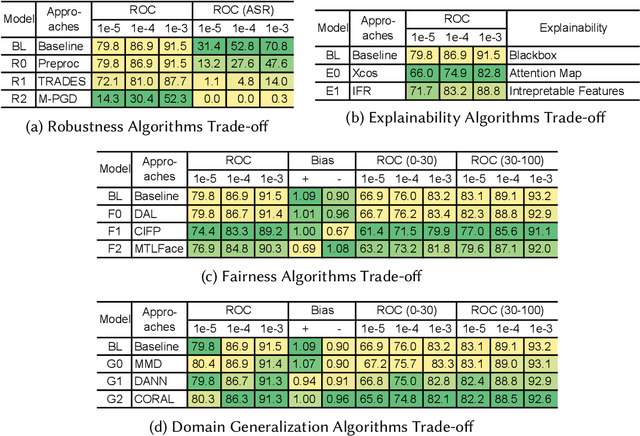
Fast developing artificial intelligence (AI) technology has enabled various applied systems deployed in the real world, impacting people's everyday lives. However, many current AI systems were found vulnerable to imperceptible attacks, biased against underrepresented groups, lacking in user privacy protection, etc., which not only degrades user experience but erodes the society's trust in all AI systems. In this review, we strive to provide AI practitioners a comprehensive guide towards building trustworthy AI systems. We first introduce the theoretical framework of important aspects of AI trustworthiness, including robustness, generalization, explainability, transparency, reproducibility, fairness, privacy preservation, alignment with human values, and accountability. We then survey leading approaches in these aspects in the industry. To unify the current fragmented approaches towards trustworthy AI, we propose a systematic approach that considers the entire lifecycle of AI systems, ranging from data acquisition to model development, to development and deployment, finally to continuous monitoring and governance. In this framework, we offer concrete action items to practitioners and societal stakeholders (e.g., researchers and regulators) to improve AI trustworthiness. Finally, we identify key opportunities and challenges in the future development of trustworthy AI systems, where we identify the need for paradigm shift towards comprehensive trustworthy AI systems.
CoSeg: Cognitively Inspired Unsupervised Generic Event Segmentation
Sep 30, 2021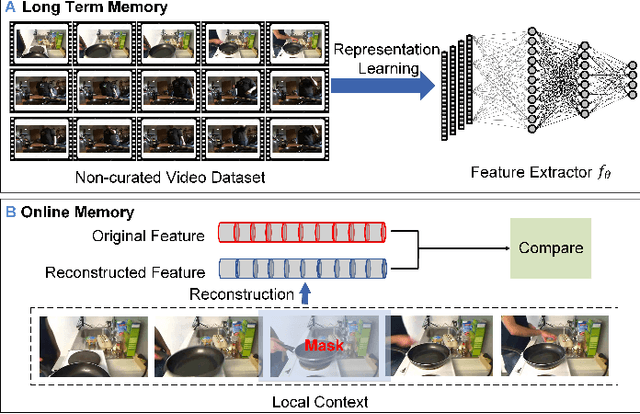
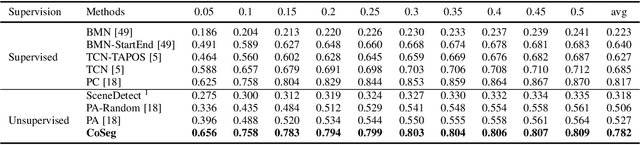
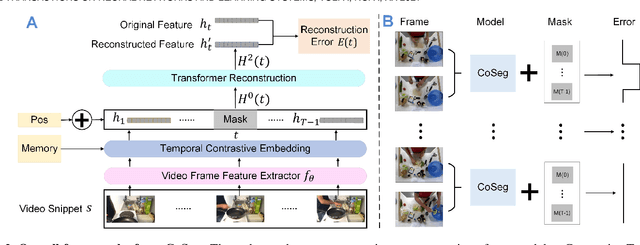
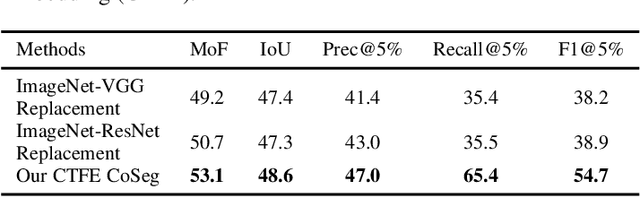
Some cognitive research has discovered that humans accomplish event segmentation as a side effect of event anticipation. Inspired by this discovery, we propose a simple yet effective end-to-end self-supervised learning framework for event segmentation/boundary detection. Unlike the mainstream clustering-based methods, our framework exploits a transformer-based feature reconstruction scheme to detect event boundary by reconstruction errors. This is consistent with the fact that humans spot new events by leveraging the deviation between their prediction and what is actually perceived. Thanks to their heterogeneity in semantics, the frames at boundaries are difficult to be reconstructed (generally with large reconstruction errors), which is favorable for event boundary detection. Additionally, since the reconstruction occurs on the semantic feature level instead of pixel level, we develop a temporal contrastive feature embedding module to learn the semantic visual representation for frame feature reconstruction. This procedure is like humans building up experiences with "long-term memory". The goal of our work is to segment generic events rather than localize some specific ones. We focus on achieving accurate event boundaries. As a result, we adopt F1 score (Precision/Recall) as our primary evaluation metric for a fair comparison with previous approaches. Meanwhile, we also calculate the conventional frame-based MoF and IoU metric. We thoroughly benchmark our work on four publicly available datasets and demonstrate much better results.
Memory-Augmented Non-Local Attention for Video Super-Resolution
Aug 25, 2021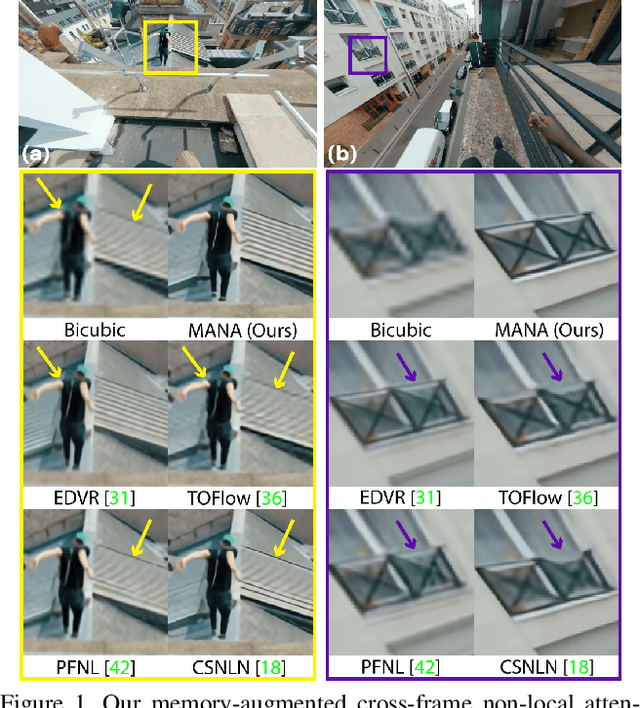
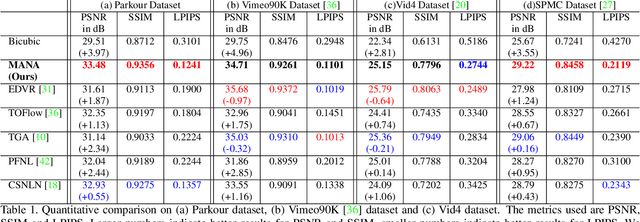
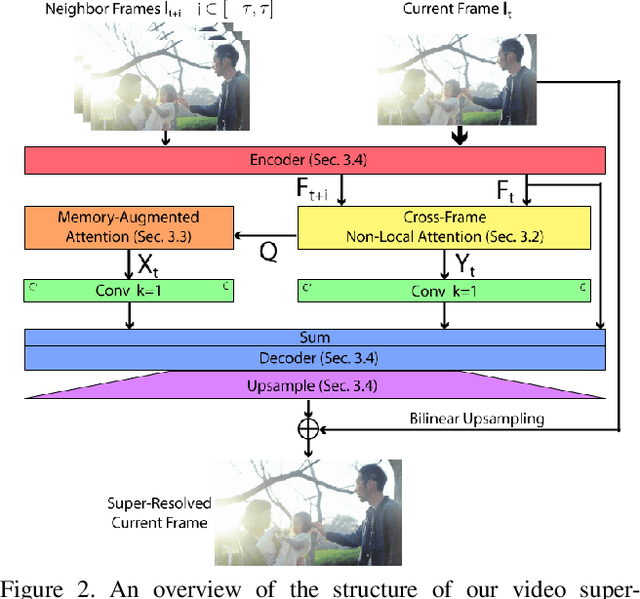
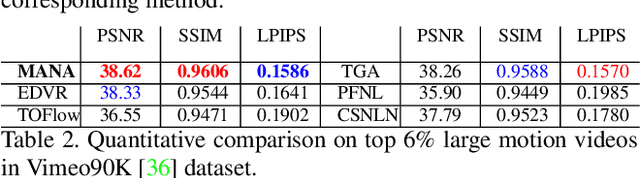
In this paper, we propose a novel video super-resolution method that aims at generating high-fidelity high-resolution (HR) videos from low-resolution (LR) ones. Previous methods predominantly leverage temporal neighbor frames to assist the super-resolution of the current frame. Those methods achieve limited performance as they suffer from the challenge in spatial frame alignment and the lack of useful information from similar LR neighbor frames. In contrast, we devise a cross-frame non-local attention mechanism that allows video super-resolution without frame alignment, leading to be more robust to large motions in the video. In addition, to acquire the information beyond neighbor frames, we design a novel memory-augmented attention module to memorize general video details during the super-resolution training. Experimental results indicate that our method can achieve superior performance on large motion videos comparing to the state-of-the-art methods without aligning frames. Our source code will be released.