 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoSeg: Cognitively Inspired Unsupervised Generic Event Segmentation
Paper and Code
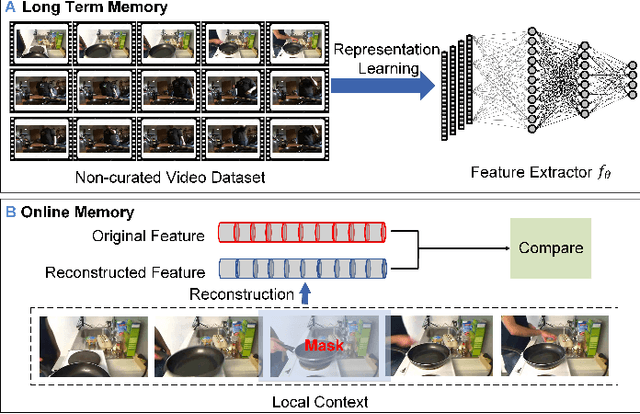
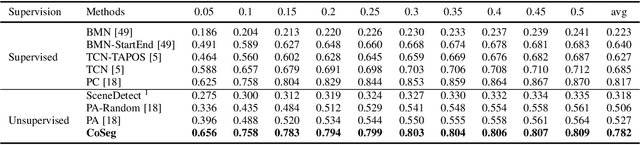
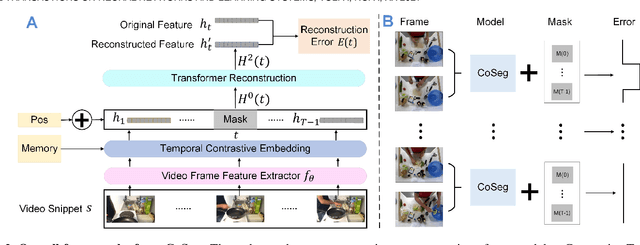
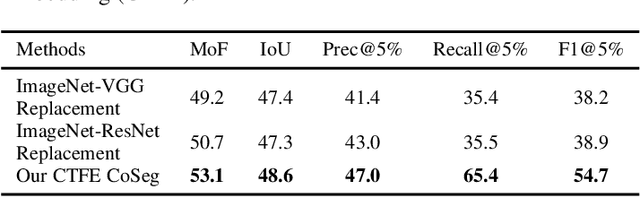
Some cognitive research has discovered that humans accomplish event segmentation as a side effect of event anticipation. Inspired by this discovery, we propose a simple yet effective end-to-end self-supervised learning framework for event segmentation/boundary detection. Unlike the mainstream clustering-based methods, our framework exploits a transformer-based feature reconstruction scheme to detect event boundary by reconstruction errors. This is consistent with the fact that humans spot new events by leveraging the deviation between their prediction and what is actually perceived. Thanks to their heterogeneity in semantics, the frames at boundaries are difficult to be reconstructed (generally with large reconstruction errors), which is favorable for event boundary detection. Additionally, since the reconstruction occurs on the semantic feature level instead of pixel level, we develop a temporal contrastive feature embedding module to learn the semantic visual representation for frame feature reconstruction. This procedure is like humans building up experiences with "long-term memory". The goal of our work is to segment generic events rather than localize some specific ones. We focus on achieving accurate event boundaries. As a result, we adopt F1 score (Precision/Recall) as our primary evaluation metric for a fair comparison with previous approaches. Meanwhile, we also calculate the conventional frame-based MoF and IoU metric. We thoroughly benchmark our work on four publicly available datasets and demonstrate much better results.