 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-modal Contrastive Distillation for Instructional Activity Anticipation
Paper and Code
Jan 18, 2022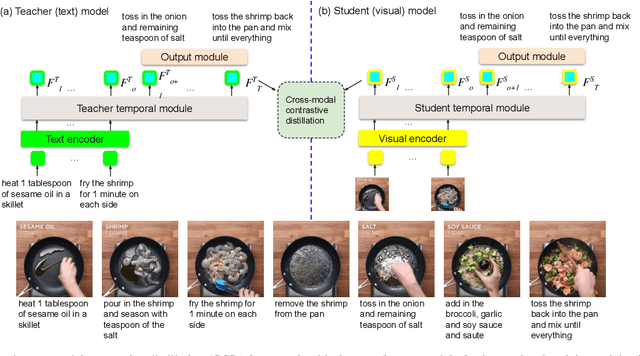
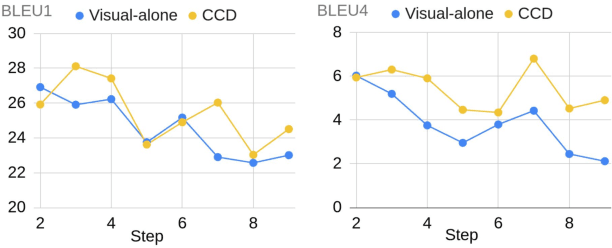

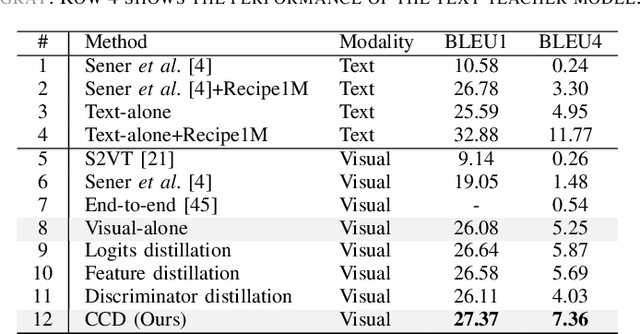
In this study, we aim to predict the plausible future action steps given an observation of the past and study the task of instructional activity anticipation. Unlike previous anticipation tasks that aim at action label prediction, our work targets at generating natural language outputs that provide interpretable and accurate descriptions of future action steps. It is a challenging task due to the lack of semantic information extracted from the instructional videos. To overcome this challenge, we propose a novel knowledge distillation framework to exploit the related external textual knowledge to assist the visual anticipation task. However, previous knowledge distillation techniques generally transfer information within the same modality. To bridge the gap between the visual and text modalities during the distillation process, we devise a novel cross-modal contrastive distillation (CCD) scheme, which facilitates knowledge distillation between teacher and student in heterogeneous modalities with the proposed cross-modal distillation loss. We evaluate our method on the Tasty Videos dataset. CCD improves the anticipation performance of the visual-alone student model by a large margin of 40.2% relatively in BLEU4. Our approach also outperforms the state-of-the-art approaches by a large margin.