 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMotion Capture from Inertial and Vision Sensors
Jul 23, 2024



Human motion capture is the foundation for many computer vision and graphics tasks. While industrial motion capture systems with complex camera arrays or expensive wearable sensors have been widely adopted in movie and game production, consumer-affordable and easy-to-use solutions for personal applications are still far from mature. To utilize a mixture of a monocular camera and very few inertial measurement units (IMUs) for accurate multi-modal human motion capture in daily life, we contribute MINIONS in this paper, a large-scale Motion capture dataset collected from INertial and visION Sensors. MINIONS has several featured properties: 1) large scale of over five million frames and 400 minutes duration; 2) multi-modality data of IMUs signals and RGB videos labeled with joint positions, joint rotations, SMPL parameters, etc.; 3) a diverse set of 146 fine-grained single and interactive actions with textual descriptions. With the proposed MINIONS, we conduct experiments on multi-modal motion capture and explore the possibilities of consumer-affordable motion capture using a monocular camera and very few IMUs. The experiment results emphasize the unique advantages of inertial and vision sensors, showcasing the promise of consumer-affordable multi-modal motion capture and providing a valuable resource for further research and development.
TRACE: 5D Temporal Regression of Avatars with Dynamic Cameras in 3D Environments
Jun 05, 2023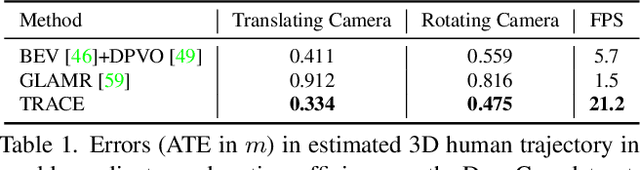
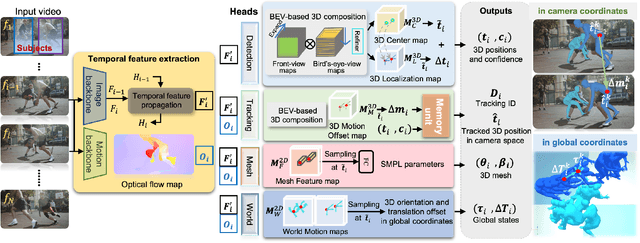
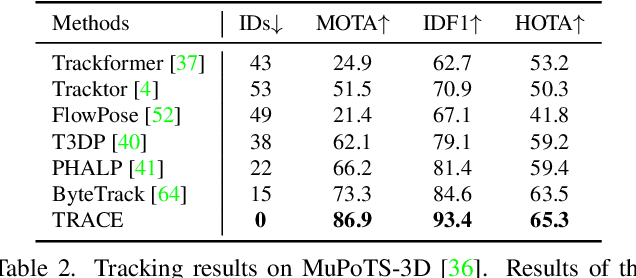

Although the estimation of 3D human pose and shape (HPS) is rapidly progressing, current methods still cannot reliably estimate moving humans in global coordinates, which is critical for many applications. This is particularly challenging when the camera is also moving, entangling human and camera motion. To address these issues, we adopt a novel 5D representation (space, time, and identity) that enables end-to-end reasoning about people in scenes. Our method, called TRACE, introduces several novel architectural components. Most importantly, it uses two new "maps" to reason about the 3D trajectory of people over time in camera, and world, coordinates. An additional memory unit enables persistent tracking of people even during long occlusions. TRACE is the first one-stage method to jointly recover and track 3D humans in global coordinates from dynamic cameras. By training it end-to-end, and using full image information, TRACE achieves state-of-the-art performance on tracking and HPS benchmarks. The code and dataset are released for research purposes.
DPIT: Dual-Pipeline Integrated Transformer for Human Pose Estimation
Sep 02, 2022
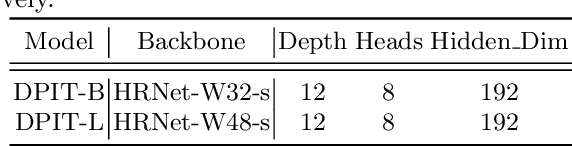
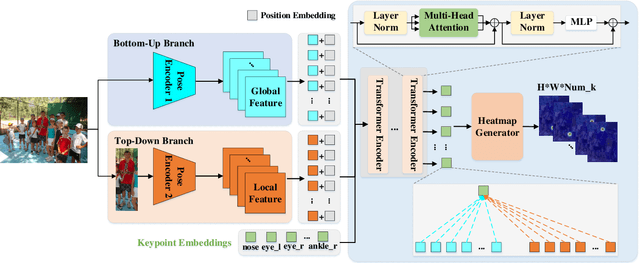
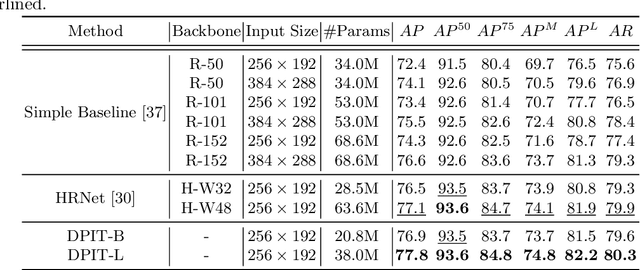
Human pose estimation aims to figure out the keypoints of all people in different scenes. Current approaches still face some challenges despite promising results. Existing top-down methods deal with a single person individually, without the interaction between different people and the scene they are situated in. Consequently, the performance of human detection degrades when serious occlusion happens. On the other hand, existing bottom-up methods consider all people at the same time and capture the global knowledge of the entire image. However, they are less accurate than the top-down methods due to the scale variation. To address these problems, we propose a novel Dual-Pipeline Integrated Transformer (DPIT) by integrating top-down and bottom-up pipelines to explore the visual clues of different receptive fields and achieve their complementarity. Specifically, DPIT consists of two branches, the bottom-up branch deals with the whole image to capture the global visual information, while the top-down branch extracts the feature representation of local vision from the single-human bounding box. Then, the extracted feature representations from bottom-up and top-down branches are fed into the transformer encoder to fuse the global and local knowledge interactively. Moreover, we define the keypoint queries to explore both full-scene and single-human posture visual clues to realize the mutual complementarity of the two pipelines. To the best of our knowledge, this is one of the first works to integrate the bottom-up and top-down pipelines with transformers for human pose estimation. Extensive experiments on COCO and MPII datasets demonstrate that our DPIT achieves comparable performance to the state-of-the-art methods.
WOC: A Handy Webcam-based 3D Online Chatroom
Sep 02, 2022

We develop WOC, a webcam-based 3D virtual online chatroom for multi-person interaction, which captures the 3D motion of users and drives their individual 3D virtual avatars in real-time. Compared to the existing wearable equipment-based solution, WOC offers convenient and low-cost 3D motion capture with a single camera. To promote the immersive chat experience, WOC provides high-fidelity virtual avatar manipulation, which also supports the user-defined characters. With the distributed data flow service, the system delivers highly synchronized motion and voice for all users. Deployed on the website and no installation required, users can freely experience the virtual online chat at https://yanch.cloud.
Smart Director: An Event-Driven Directing System for Live Broadcasting
Jan 11, 2022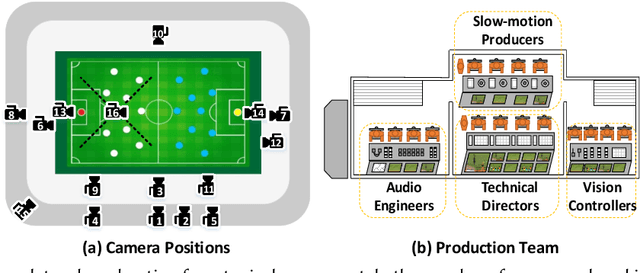
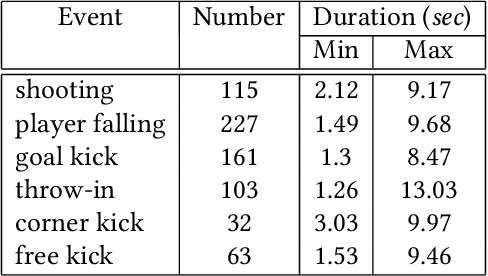
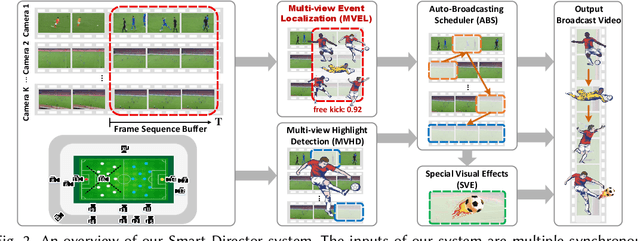
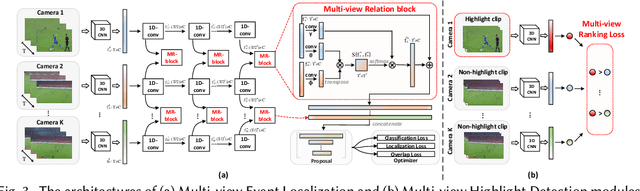
Live video broadcasting normally requires a multitude of skills and expertise with domain knowledge to enable multi-camera productions. As the number of cameras keep increasing, directing a live sports broadcast has now become more complicated and challenging than ever before. The broadcast directors need to be much more concentrated, responsive, and knowledgeable, during the production. To relieve the directors from their intensive efforts, we develop an innovative automated sports broadcast directing system, called Smart Director, which aims at mimicking the typical human-in-the-loop broadcasting process to automatically create near-professional broadcasting programs in real-time by using a set of advanced multi-view video analysis algorithms. Inspired by the so-called "three-event" construction of sports broadcast, we build our system with an event-driven pipeline consisting of three consecutive novel components: 1) the Multi-view Event Localization to detect events by modeling multi-view correlations, 2) the Multi-view Highlight Detection to rank camera views by the visual importance for view selection, 3) the Auto-Broadcasting Scheduler to control the production of broadcasting videos. To our best knowledge, our system is the first end-to-end automated directing system for multi-camera sports broadcasting, completely driven by the semantic understanding of sports events. It is also the first system to solve the novel problem of multi-view joint event detection by cross-view relation modeling. We conduct both objective and subjective evaluations on a real-world multi-camera soccer dataset, which demonstrate the quality of our auto-generated videos is comparable to that of the human-directed. Thanks to its faster response, our system is able to capture more fast-passing and short-duration events which are usually missed by human directors.
Putting People in their Place: Monocular Regression of 3D People in Depth
Dec 15, 2021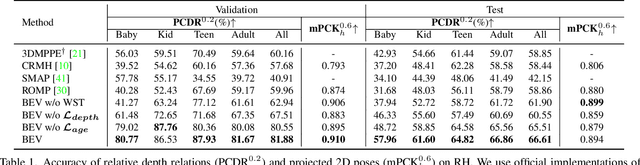
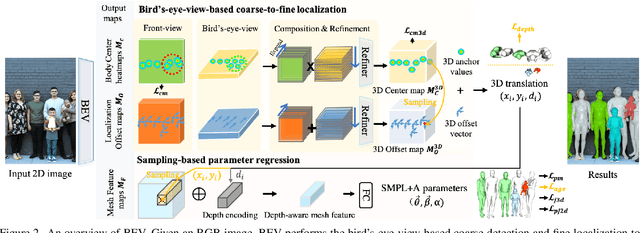
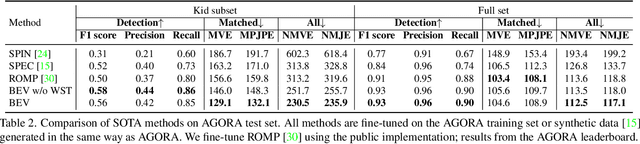

Given an image with multiple people, our goal is to directly regress the pose and shape of all the people as well as their relative depth. Inferring the depth of a person in an image, however, is fundamentally ambiguous without knowing their height. This is particularly problematic when the scene contains people of very different sizes, e.g. from infants to adults. To solve this, we need several things. First, we develop a novel method to infer the poses and depth of multiple people in a single image. While previous work that estimates multiple people does so by reasoning in the image plane, our method, called BEV, adds an additional imaginary Bird's-Eye-View representation to explicitly reason about depth. BEV reasons simultaneously about body centers in the image and in depth and, by combing these, estimates 3D body position. Unlike prior work, BEV is a single-shot method that is end-to-end differentiable. Second, height varies with age, making it impossible to resolve depth without also estimating the age of people in the image. To do so, we exploit a 3D body model space that lets BEV infer shapes from infants to adults. Third, to train BEV, we need a new dataset. Specifically, we create a "Relative Human" (RH) dataset that includes age labels and relative depth relationships between the people in the images. Extensive experiments on RH and AGORA demonstrate the effectiveness of the model and training scheme. BEV outperforms existing methods on depth reasoning, child shape estimation, and robustness to occlusion. The code and dataset will be released for research purposes.
Recent Advances in Monocular 2D and 3D Human Pose Estimation: A Deep Learning Perspective
Apr 23, 2021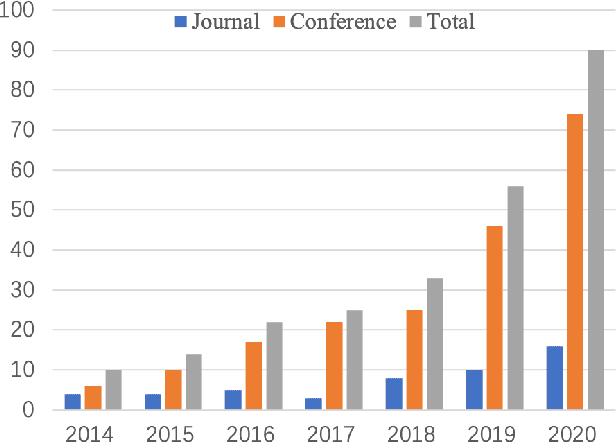
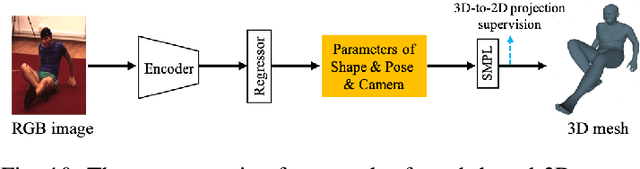

Estimation of the human pose from a monocular camera has been an emerging research topic in the computer vision community with many applications. Recently, benefited from the deep learning technologies, a significant amount of research efforts have greatly advanced the monocular human pose estimation both in 2D and 3D areas. Although there have been some works to summarize the different approaches, it still remains challenging for researchers to have an in-depth view of how these approaches work. In this paper, we provide a comprehensive and holistic 2D-to-3D perspective to tackle this problem. We categorize the mainstream and milestone approaches since the year 2014 under unified frameworks. By systematically summarizing the differences and connections between these approaches, we further analyze the solutions for challenging cases, such as the lack of data, the inherent ambiguity between 2D and 3D, and the complex multi-person scenarios. We also summarize the pose representation styles, benchmarks, evaluation metrics, and the quantitative performance of popular approaches. Finally, we discuss the challenges and give deep thinking of promising directions for future research. We believe this survey will provide the readers with a deep and insightful understanding of monocular human pose estimation.
Synthetic Training for Monocular Human Mesh Recovery
Oct 27, 2020
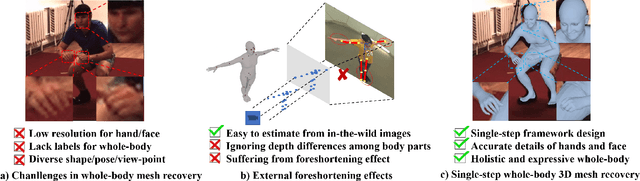
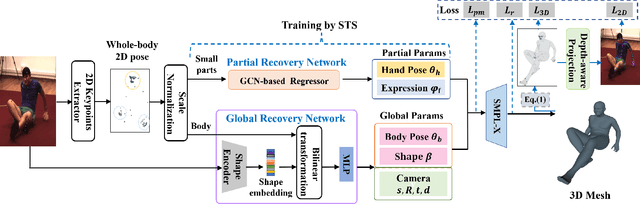
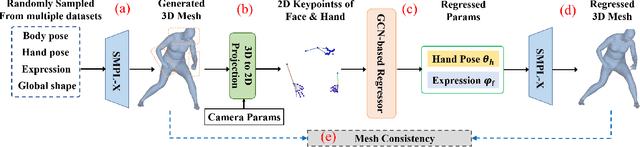
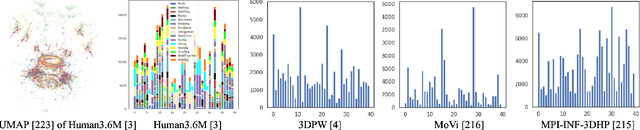
Recovering 3D human mesh from monocular images is a popular topic in computer vision and has a wide range of applications. This paper aims to estimate 3D mesh of multiple body parts (e.g., body, hands) with large-scale differences from a single RGB image. Existing methods are mostly based on iterative optimization, which is very time-consuming. We propose to train a single-shot model to achieve this goal. The main challenge is lacking training data that have complete 3D annotations of all body parts in 2D images. To solve this problem, we design a multi-branch framework to disentangle the regression of different body properties, enabling us to separate each component's training in a synthetic training manner using unpaired data available. Besides, to strengthen the generalization ability, most existing methods have used in-the-wild 2D pose datasets to supervise the estimated 3D pose via 3D-to-2D projection. However, we observe that the commonly used weak-perspective model performs poorly in dealing with the external foreshortening effect of camera projection. Therefore, we propose a depth-to-scale (D2S) projection to incorporate the depth difference into the projection function to derive per-joint scale variants for more proper supervision. The proposed method outperforms previous methods on the CMU Panoptic Studio dataset according to the evaluation results and achieves comparable results on the Human3.6M body and STB hand benchmarks. More impressively, the performance in close shot images gets significantly improved using the proposed D2S projection for weak supervision, while maintains obvious superiority in computational efficiency.
CenterHMR: a Bottom-up Single-shot Method for Multi-person 3D Mesh Recovery from a Single Image
Aug 27, 2020
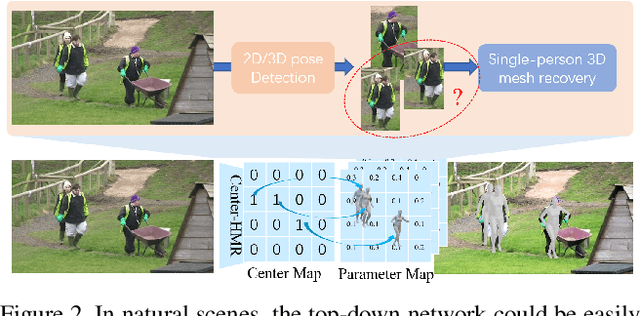
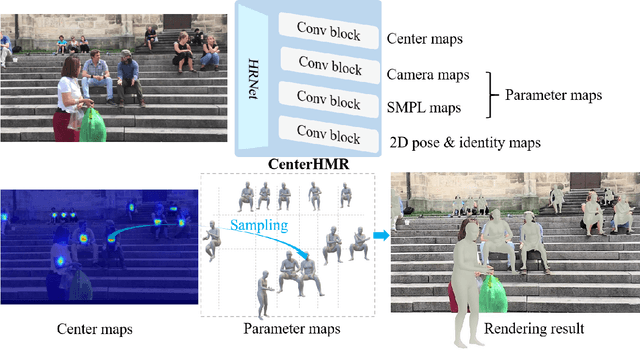

In this paper, we propose a method to recover multi-person 3D mesh from a single image. Existing methods follow a multi-stage detection-based pipeline, where the 3D mesh of each person is regressed from the cropped image patch. They have to suffer from the high complexity of the multi-stage process and the ambiguity of the image-level features. For example, it is hard for them to estimate multi-person 3D mesh from the inseparable crowded cases. Instead, in this paper, we present a novel bottom-up single-shot method, Center-based Human Mesh Recovery network (CenterHMR). The model is trained to simultaneously predict two maps, which represent the location of each human body center and the corresponding parameter vector of 3D human mesh at each center. This explicit center-based representation guarantees the pixel-level feature encoding. Besides, the 3D mesh result of each person is estimated from the features centered at the visible body parts, which improves the robustness under occlusion. CenterHMR surpasses previous methods on multi-person in-the-wild benchmark 3DPW and occlusion dataset 3DOH50K. Besides, CenterHMR has achieved a 2-nd place on ECCV 2020 3DPW Challenge. The code is released on https://github.com/Arthur151/CenterHMR.