 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDPIT: Dual-Pipeline Integrated Transformer for Human Pose Estimation
Sep 02, 2022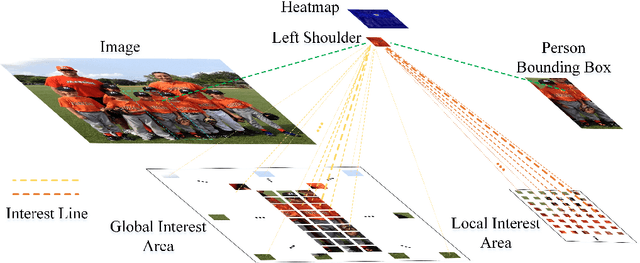
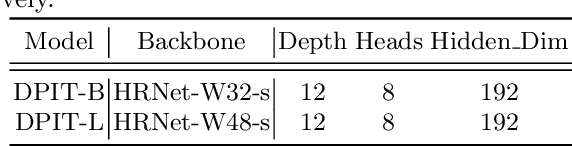
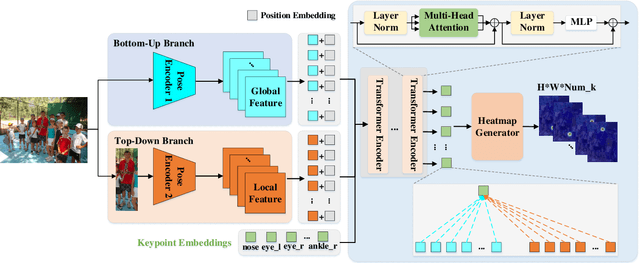
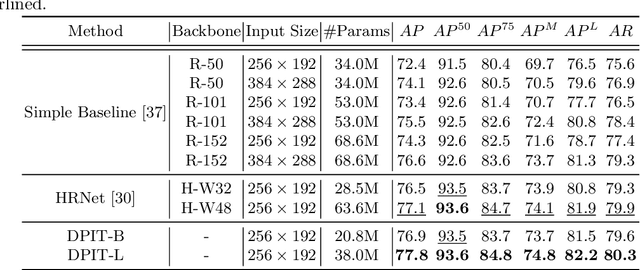
Human pose estimation aims to figure out the keypoints of all people in different scenes. Current approaches still face some challenges despite promising results. Existing top-down methods deal with a single person individually, without the interaction between different people and the scene they are situated in. Consequently, the performance of human detection degrades when serious occlusion happens. On the other hand, existing bottom-up methods consider all people at the same time and capture the global knowledge of the entire image. However, they are less accurate than the top-down methods due to the scale variation. To address these problems, we propose a novel Dual-Pipeline Integrated Transformer (DPIT) by integrating top-down and bottom-up pipelines to explore the visual clues of different receptive fields and achieve their complementarity. Specifically, DPIT consists of two branches, the bottom-up branch deals with the whole image to capture the global visual information, while the top-down branch extracts the feature representation of local vision from the single-human bounding box. Then, the extracted feature representations from bottom-up and top-down branches are fed into the transformer encoder to fuse the global and local knowledge interactively. Moreover, we define the keypoint queries to explore both full-scene and single-human posture visual clues to realize the mutual complementarity of the two pipelines. To the best of our knowledge, this is one of the first works to integrate the bottom-up and top-down pipelines with transformers for human pose estimation. Extensive experiments on COCO and MPII datasets demonstrate that our DPIT achieves comparable performance to the state-of-the-art methods.