 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSub-JEPA: Subspace Gaussian Regularization for Stable End-to-End World Models
May 10, 2026Joint-Embedding Predictive Architectures (JEPAs) provide a simpleframework for learning world models by predicting future latent representations.However, JEPA training is subject to a bias-variance tradeoff.Without sufficient structural constraints, excessive representationalvariance causes the model to collapse to trivial solutions.The recent LeWorldModel (LeWM) shows that this issue can be alleviated bysimply constraining latent embeddings with an isotropic Gaussian prior.However, latent representations inherently lie on low-dimensional manifoldswithin a high-dimensional ambient space, and enforcing an isotropic Gaussianprior directly in this ambient space introduces an overly strong bias.In this work, we propose ame, which seeks a favorable operatingpoint on the bias-variance frontier by applying Gaussian constraints inmultiple random subspaces rather than in the originalembedding space.This design relaxes the global constraint while preserving itsanti-collapse effect, leading to a better balance between trainingstability and representation flexibility.Extensive experiments across fourcontinuous-control environments demonstrate that consistentlyoutperforms LeWM with very clear margins.Our method is simple yet effective, and serves as a strong baseline for future JEPA-based world model research.fdefinedeeemodeThe code is available at https://github.com/intcomp/Sub-JEPA.
SeGPruner: Semantic-Geometric Visual Token Pruner for 3D Question Answering
Mar 31, 2026Vision-language models (VLMs) have been widely adopted for 3D question answering (3D QA). In typical pipelines, visual tokens extracted from multiple viewpoints are concatenated with language tokens and jointly processed by a large language model (LLM) for inference. However, aggregating multi-view observations inevitably introduces severe token redundancy, leading to an overly large visual token set that significantly hinders inference efficiency under constrained token budgets. Visual token pruning has emerged as a prevalent strategy to address this issue. Nevertheless, most existing pruners are primarily tailored to 2D inputs or rely on indirect geometric cues, which limits their ability to explicitly retain semantically critical objects and maintain sufficient spatial coverage for robust 3D reasoning. In this paper, we propose SeGPruner, a semantic-aware and geometry-guided token reduction framework for efficient 3D QA with multi-view images. Specifically, SeGPruner first preserves semantically salient tokens through an attention-based importance module (Saliency-aware Token Selector), ensuring that object-critical evidence is retained. It then complements these tokens with spatially diverse ones via a geometry-guided selector (Geometry-aware Token Diversifier), which jointly considers semantic relevance and 3D geometric distance. This cooperation between saliency preservation and geometry-guided diversification balances object-level evidence and global scene coverage under aggressive token reduction. Extensive experiments on ScanQA and OpenEQA demonstrate that SeGPruner substantially improves inference efficiency, reducing the visual token budget by 91% and inference latency by 86%, while maintaining competitive performance in 3D reasoning tasks.
Fully Spiking Neural Networks with Target Awareness for Energy-Efficient UAV Tracking
Mar 29, 2026Spiking Neural Networks (SNNs), characterized by their event-driven computation and low power consumption, have shown great potential for energy-efficient visual tracking on unmanned aerial vehicles (UAVs). However, existing efficient SNN-based trackers heavily rely on costly event cameras, limiting their deployment on UAVs. To address this limitation, we propose STATrack, an efficient fully spiking neural network framework for UAV visual tracking using RGB inputs only. To the best of our knowledge, this work is the first to investigate spiking neural networks for UAV visual tracking tasks. To mitigate the weakening of target features by background tokens, we propose adaptively maximizing the mutual information between templates and features. Extensive experiments on four widely used UAV tracking benchmarks demonstrate that STATrack achieves competitive tracking performance while maintaining low energy consumption.
STENet: Superpixel Token Enhancing Network for RGB-D Salient Object Detection
Mar 23, 2026Transformer-based methods for RGB-D Salient Object Detection (SOD) have gained significant interest, owing to the transformer's exceptional capacity to capture long-range pixel dependencies. Nevertheless, current RGB-D SOD methods face challenges, such as the quadratic complexity of the attention mechanism and the limited local detail extraction. To overcome these limitations, we propose a novel Superpixel Token Enhancing Network (STENet), which introduces superpixels into cross-modal interaction. STENet follows the two-stream encoder-decoder structure. Its cores are two tailored superpixel-driven cross-modal interaction modules, responsible for global and local feature enhancement. Specifically, we update the superpixel generation method by expanding the neighborhood range of each superpixel, allowing for flexible transformation between pixels and superpixels. With the updated superpixel generation method, we first propose the Superpixel Attention Global Enhancing Module to model the global pixel-to-superpixel relationship rather than the traditional global pixel-to-pixel relationship, which can capture region-level information and reduce computational complexity. We also propose the Superpixel Attention Local Refining Module, which leverages pixel similarity within superpixels to filter out a subset of pixels (i.e., local pixels) and then performs feature enhancement on these local pixels, thereby capturing concerned local details. Furthermore, we fuse the globally and locally enhanced features along with the cross-scale features to achieve comprehensive feature representation. Experiments on seven RGB-D SOD datasets reveal that our STENet achieves competitive performance compared to state-of-the-art methods. The code and results of our method are available at https://github.com/Mark9010/STENet.
LightMoE: Reducing Mixture-of-Experts Redundancy through Expert Replacing
Mar 13, 2026Mixture-of-Experts (MoE) based Large Language Models (LLMs) have demonstrated impressive performance and computational efficiency. However, their deployment is often constrained by substantial memory demands, primarily due to the need to load numerous expert modules. While existing expert compression techniques like pruning or merging attempt to mitigate this, they often suffer from irreversible knowledge loss or high training overhead. In this paper, we propose a novel expert compression paradigm termed expert replacing, which replaces redundant experts with parameter-efficient modules and recovers their capabilities with low training costs. We find that even a straightforward baseline of this paradigm yields promising performance. Building on this foundation, we introduce LightMoE, a framework that enhances the paradigm by introducing adaptive expert selection, hierarchical expert construction, and an annealed recovery strategy. Experimental results show that LightMoE matches the performance of LoRA fine-tuning at a 30% compression ratio. Even under a more aggressive 50% compression rate, it outperforms existing methods and achieves average performance improvements of 5.6% across five diverse tasks. These findings demonstrate that LightMoE strikes a superior balance among memory efficiency, training efficiency, and model performance.
PKI: Prior Knowledge-Infused Neural Network for Few-Shot Class-Incremental Learning
Jan 13, 2026Few-shot class-incremental learning (FSCIL) aims to continually adapt a model on a limited number of new-class examples, facing two well-known challenges: catastrophic forgetting and overfitting to new classes. Existing methods tend to freeze more parts of network components and finetune others with an extra memory during incremental sessions. These methods emphasize preserving prior knowledge to ensure proficiency in recognizing old classes, thereby mitigating catastrophic forgetting. Meanwhile, constraining fewer parameters can help in overcoming overfitting with the assistance of prior knowledge. Following previous methods, we retain more prior knowledge and propose a prior knowledge-infused neural network (PKI) to facilitate FSCIL. PKI consists of a backbone, an ensemble of projectors, a classifier, and an extra memory. In each incremental session, we build a new projector and add it to the ensemble. Subsequently, we finetune the new projector and the classifier jointly with other frozen network components, ensuring the rich prior knowledge is utilized effectively. By cascading projectors, PKI integrates prior knowledge accumulated from previous sessions and learns new knowledge flexibly, which helps to recognize old classes and efficiently learn new classes. Further, to reduce the resource consumption associated with keeping many projectors, we design two variants of the prior knowledge-infused neural network (PKIV-1 and PKIV-2) to trade off a balance between resource consumption and performance by reducing the number of projectors. Extensive experiments on three popular benchmarks demonstrate that our approach outperforms state-of-the-art methods.
Divide and Conquer: Static-Dynamic Collaboration for Few-Shot Class-Incremental Learning
Jan 13, 2026Few-shot class-incremental learning (FSCIL) aims to continuously recognize novel classes under limited data, which suffers from the key stability-plasticity dilemma: balancing the retention of old knowledge with the acquisition of new knowledge. To address this issue, we divide the task into two different stages and propose a framework termed Static-Dynamic Collaboration (SDC) to achieve a better trade-off between stability and plasticity. Specifically, our method divides the normal pipeline of FSCIL into Static Retaining Stage (SRS) and Dynamic Learning Stage (DLS), which harnesses old static and incremental dynamic class information, respectively. During SRS, we train an initial model with sufficient data in the base session and preserve the key part as static memory to retain fundamental old knowledge. During DLS, we introduce an extra dynamic projector jointly trained with the previous static memory. By employing both stages, our method achieves improved retention of old knowledge while continuously adapting to new classes. Extensive experiments on three public benchmarks and a real-world application dataset demonstrate that our method achieves state-of-the-art performance against other competitors.
CapeNext: Rethinking and refining dynamic support information for category-agnostic pose estimation
Nov 17, 2025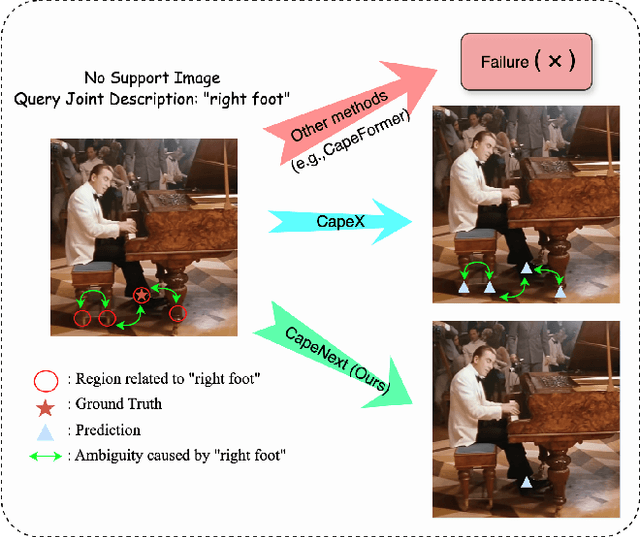
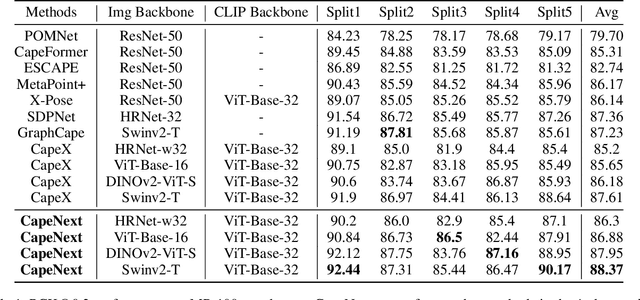
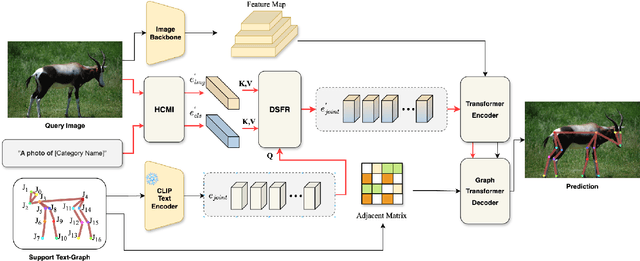
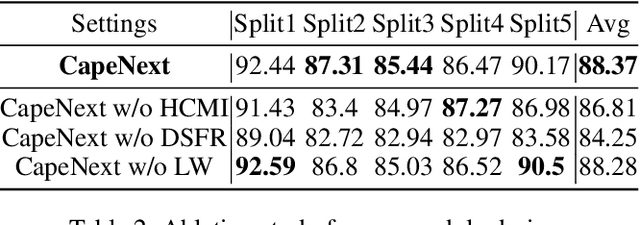
Recent research in Category-Agnostic Pose Estimation (CAPE) has adopted fixed textual keypoint description as semantic prior for two-stage pose matching frameworks. While this paradigm enhances robustness and flexibility by disentangling the dependency of support images, our critical analysis reveals two inherent limitations of static joint embedding: (1) polysemy-induced cross-category ambiguity during the matching process(e.g., the concept "leg" exhibiting divergent visual manifestations across humans and furniture), and (2) insufficient discriminability for fine-grained intra-category variations (e.g., posture and fur discrepancies between a sleeping white cat and a standing black cat). To overcome these challenges, we propose a new framework that innovatively integrates hierarchical cross-modal interaction with dual-stream feature refinement, enhancing the joint embedding with both class-level and instance-specific cues from textual description and specific images. Experiments on the MP-100 dataset demonstrate that, regardless of the network backbone, CapeNext consistently outperforms state-of-the-art CAPE methods by a large margin.
PoRe: Position-Reweighted Visual Token Pruning for Vision Language Models
Aug 25, 2025Vision-Language Models (VLMs) typically process a significantly larger number of visual tokens compared to text tokens due to the inherent redundancy in visual signals. Visual token pruning is a promising direction to reduce the computational cost of VLMs by eliminating redundant visual tokens. The text-visual attention score is a widely adopted criterion for visual token pruning as it reflects the relevance of visual tokens to the text input. However, many sequence models exhibit a recency bias, where tokens appearing later in the sequence exert a disproportionately large influence on the model's output. In VLMs, this bias manifests as inflated attention scores for tokens corresponding to the lower regions of the image, leading to suboptimal pruning that disproportionately retains tokens from the image bottom. In this paper, we present an extremely simple yet effective approach to alleviate the recency bias in visual token pruning. We propose a straightforward reweighting mechanism that adjusts the attention scores of visual tokens according to their spatial positions in the image. Our method, termed Position-reweighted Visual Token Pruning, is a plug-and-play solution that can be seamlessly incorporated into existing visual token pruning frameworks without any changes to the model architecture or extra training. Extensive experiments on LVLMs demonstrate that our method improves the performance of visual token pruning with minimal computational overhead.
SMTrack: End-to-End Trained Spiking Neural Networks for Multi-Object Tracking in RGB Videos
Aug 20, 2025Brain-inspired Spiking Neural Networks (SNNs) exhibit significant potential for low-power computation, yet their application in visual tasks remains largely confined to image classification, object detection, and event-based tracking. In contrast, real-world vision systems still widely use conventional RGB video streams, where the potential of directly-trained SNNs for complex temporal tasks such as multi-object tracking (MOT) remains underexplored. To address this challenge, we propose SMTrack-the first directly trained deep SNN framework for end-to-end multi-object tracking on standard RGB videos. SMTrack introduces an adaptive and scale-aware Normalized Wasserstein Distance loss (Asa-NWDLoss) to improve detection and localization performance under varying object scales and densities. Specifically, the method computes the average object size within each training batch and dynamically adjusts the normalization factor, thereby enhancing sensitivity to small objects. For the association stage, we incorporate the TrackTrack identity module to maintain robust and consistent object trajectories. Extensive evaluations on BEE24, MOT17, MOT20, and DanceTrack show that SMTrack achieves performance on par with leading ANN-based MOT methods, advancing robust and accurate SNN-based tracking in complex scenarios.