 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoarse-to-Fine Open-Set Graph Node Classification with Large Language Models
Dec 21, 2025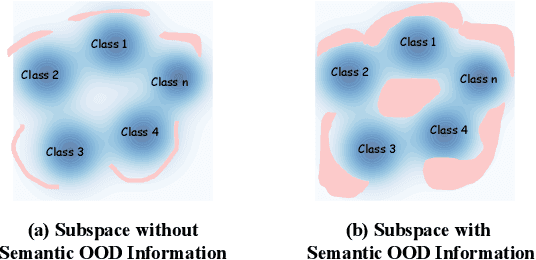
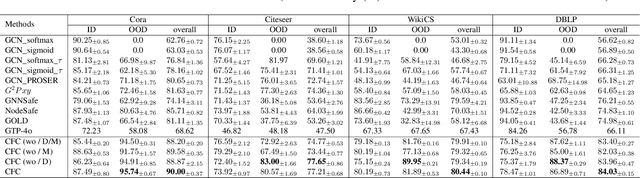

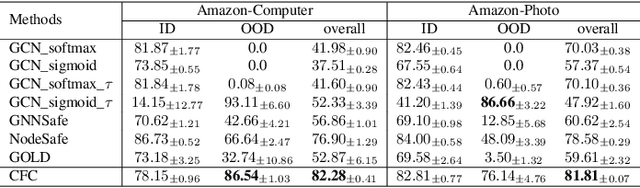
Developing open-set classification methods capable of classifying in-distribution (ID) data while detecting out-of-distribution (OOD) samples is essential for deploying graph neural networks (GNNs) in open-world scenarios. Existing methods typically treat all OOD samples as a single class, despite real-world applications, especially high-stake settings such as fraud detection and medical diagnosis, demanding deeper insights into OOD samples, including their probable labels. This raises a critical question: can OOD detection be extended to OOD classification without true label information? To address this question, we propose a Coarse-to-Fine open-set Classification (CFC) framework that leverages large language models (LLMs) for graph datasets. CFC consists of three key components: a coarse classifier that uses LLM prompts for OOD detection and outlier label generation, a GNN-based fine classifier trained with OOD samples identified by the coarse classifier for enhanced OOD detection and ID classification, and refined OOD classification achieved through LLM prompts and post-processed OOD labels. Unlike methods that rely on synthetic or auxiliary OOD samples, CFC employs semantic OOD instances that are genuinely out-of-distribution based on their inherent meaning, improving interpretability and practical utility. Experimental results show that CFC improves OOD detection by ten percent over state-of-the-art methods on graph and text domains and achieves up to seventy percent accuracy in OOD classification on graph datasets.
Investigating The Functional Roles of Attention Heads in Vision Language Models: Evidence for Reasoning Modules
Dec 11, 2025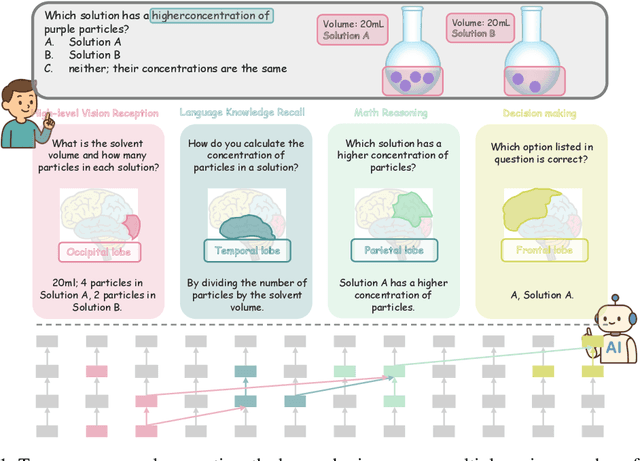
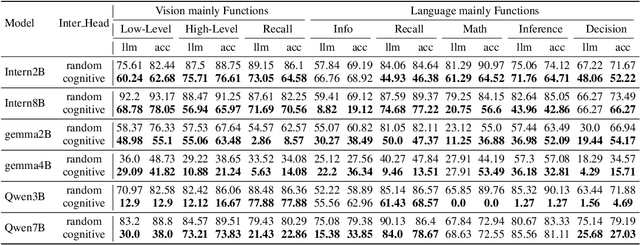
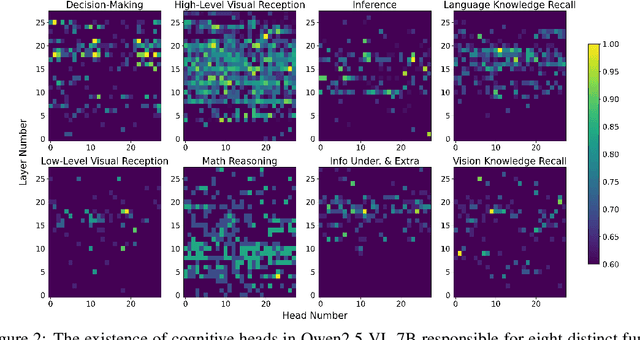

Despite excelling on multimodal benchmarks, vision-language models (VLMs) largely remain a black box. In this paper, we propose a novel interpretability framework to systematically analyze the internal mechanisms of VLMs, focusing on the functional roles of attention heads in multimodal reasoning. To this end, we introduce CogVision, a dataset that decomposes complex multimodal questions into step-by-step subquestions designed to simulate human reasoning through a chain-of-thought paradigm, with each subquestion associated with specific receptive or cognitive functions such as high-level visual reception and inference. Using a probing-based methodology, we identify attention heads that specialize in these functions and characterize them as functional heads. Our analysis across diverse VLM families reveals that these functional heads are universally sparse, vary in number and distribution across functions, and mediate interactions and hierarchical organization. Furthermore, intervention experiments demonstrate their critical role in multimodal reasoning: removing functional heads leads to performance degradation, while emphasizing them enhances accuracy. These findings provide new insights into the cognitive organization of VLMs and suggest promising directions for designing models with more human-aligned perceptual and reasoning abilities.
Hunyuan3D Studio: End-to-End AI Pipeline for Game-Ready 3D Asset Generation
Sep 16, 2025



The creation of high-quality 3D assets, a cornerstone of modern game development, has long been characterized by labor-intensive and specialized workflows. This paper presents Hunyuan3D Studio, an end-to-end AI-powered content creation platform designed to revolutionize the game production pipeline by automating and streamlining the generation of game-ready 3D assets. At its core, Hunyuan3D Studio integrates a suite of advanced neural modules (such as Part-level 3D Generation, Polygon Generation, Semantic UV, etc.) into a cohesive and user-friendly system. This unified framework allows for the rapid transformation of a single concept image or textual description into a fully-realized, production-quality 3D model complete with optimized geometry and high-fidelity PBR textures. We demonstrate that assets generated by Hunyuan3D Studio are not only visually compelling but also adhere to the stringent technical requirements of contemporary game engines, significantly reducing iteration time and lowering the barrier to entry for 3D content creation. By providing a seamless bridge from creative intent to technical asset, Hunyuan3D Studio represents a significant leap forward for AI-assisted workflows in game development and interactive media.
CLR-Wire: Towards Continuous Latent Representations for 3D Curve Wireframe Generation
May 01, 2025We introduce CLR-Wire, a novel framework for 3D curve-based wireframe generation that integrates geometry and topology into a unified Continuous Latent Representation. Unlike conventional methods that decouple vertices, edges, and faces, CLR-Wire encodes curves as Neural Parametric Curves along with their topological connectivity into a continuous and fixed-length latent space using an attention-driven variational autoencoder (VAE). This unified approach facilitates joint learning and generation of both geometry and topology. To generate wireframes, we employ a flow matching model to progressively map Gaussian noise to these latents, which are subsequently decoded into complete 3D wireframes. Our method provides fine-grained modeling of complex shapes and irregular topologies, and supports both unconditional generation and generation conditioned on point cloud or image inputs. Experimental results demonstrate that, compared with state-of-the-art generative approaches, our method achieves substantial improvements in accuracy, novelty, and diversity, offering an efficient and comprehensive solution for CAD design, geometric reconstruction, and 3D content creation.
GenUDC: High Quality 3D Mesh Generation with Unsigned Dual Contouring Representation
Oct 23, 2024Generating high-quality meshes with complex structures and realistic surfaces is the primary goal of 3D generative models. Existing methods typically employ sequence data or deformable tetrahedral grids for mesh generation. However, sequence-based methods have difficulty producing complex structures with many faces due to memory limits. The deformable tetrahedral grid-based method MeshDiffusion fails to recover realistic surfaces due to the inherent ambiguity in deformable grids. We propose the GenUDC framework to address these challenges by leveraging the Unsigned Dual Contouring (UDC) as the mesh representation. UDC discretizes a mesh in a regular grid and divides it into the face and vertex parts, recovering both complex structures and fine details. As a result, the one-to-one mapping between UDC and mesh resolves the ambiguity problem. In addition, GenUDC adopts a two-stage, coarse-to-fine generative process for 3D mesh generation. It first generates the face part as a rough shape and then the vertex part to craft a detailed shape. Extensive evaluations demonstrate the superiority of UDC as a mesh representation and the favorable performance of GenUDC in mesh generation. The code and trained models are available at https://github.com/TrepangCat/GenUDC.
Generating 3D House Wireframes with Semantics
Jul 17, 2024We present a new approach for generating 3D house wireframes with semantic enrichment using an autoregressive model. Unlike conventional generative models that independently process vertices, edges, and faces, our approach employs a unified wire-based representation for improved coherence in learning 3D wireframe structures. By re-ordering wire sequences based on semantic meanings, we facilitate seamless semantic integration during sequence generation. Our two-phase technique merges a graph-based autoencoder with a transformer-based decoder to learn latent geometric tokens and generate semantic-aware wireframes. Through iterative prediction and decoding during inference, our model produces detailed wireframes that can be easily segmented into distinct components, such as walls, roofs, and rooms, reflecting the semantic essence of the shape. Empirical results on a comprehensive house dataset validate the superior accuracy, novelty, and semantic fidelity of our model compared to existing generative models. More results and details can be found on https://vcc.tech/research/2024/3DWire.
Dual-perspective Cross Contrastive Learning in Graph Transformers
Jun 01, 2024Graph contrastive learning (GCL) is a popular method for leaning graph representations by maximizing the consistency of features across augmented views. Traditional GCL methods utilize single-perspective i.e. data or model-perspective) augmentation to generate positive samples, restraining the diversity of positive samples. In addition, these positive samples may be unreliable due to uncontrollable augmentation strategies that potentially alter the semantic information. To address these challenges, this paper proposed a innovative framework termed dual-perspective cross graph contrastive learning (DC-GCL), which incorporates three modifications designed to enhance positive sample diversity and reliability: 1) We propose dual-perspective augmentation strategy that provide the model with more diverse training data, enabling the model effective learning of feature consistency across different views. 2) From the data perspective, we slightly perturb the original graphs using controllable data augmentation, effectively preserving their semantic information. 3) From the model perspective, we enhance the encoder by utilizing more powerful graph transformers instead of graph neural networks. Based on the model's architecture, we propose three pruning-based strategies to slightly perturb the encoder, providing more reliable positive samples. These modifications collectively form the DC-GCL's foundation and provide more diverse and reliable training inputs, offering significant improvements over traditional GCL methods. Extensive experiments on various benchmarks demonstrate that DC-GCL consistently outperforms different baselines on various datasets and tasks.
Hi-GMAE: Hierarchical Graph Masked Autoencoders
May 17, 2024Graph Masked Autoencoders (GMAEs) have emerged as a notable self-supervised learning approach for graph-structured data. Existing GMAE models primarily focus on reconstructing node-level information, categorizing them as single-scale GMAEs. This methodology, while effective in certain contexts, tends to overlook the complex hierarchical structures inherent in many real-world graphs. For instance, molecular graphs exhibit a clear hierarchical organization in the form of the atoms-functional groups-molecules structure. Hence, the inability of single-scale GMAE models to incorporate these hierarchical relationships often leads to their inadequate capture of crucial high-level graph information, resulting in a noticeable decline in performance. To address this limitation, we propose Hierarchical Graph Masked AutoEncoders (Hi-GMAE), a novel multi-scale GMAE framework designed to handle the hierarchical structures within graphs. First, Hi-GMAE constructs a multi-scale graph hierarchy through graph pooling, enabling the exploration of graph structures across different granularity levels. To ensure masking uniformity of subgraphs across these scales, we propose a novel coarse-to-fine strategy that initiates masking at the coarsest scale and progressively back-projects the mask to the finer scales. Furthermore, we integrate a gradual recovery strategy with the masking process to mitigate the learning challenges posed by completely masked subgraphs. Diverging from the standard graph neural network (GNN) used in GMAE models, Hi-GMAE modifies its encoder and decoder into hierarchical structures. This entails using GNN at the finer scales for detailed local graph analysis and employing a graph transformer at coarser scales to capture global information. Our experiments on 15 graph datasets consistently demonstrate that Hi-GMAE outperforms 17 state-of-the-art self-supervised competitors.
Gradformer: Graph Transformer with Exponential Decay
Apr 24, 2024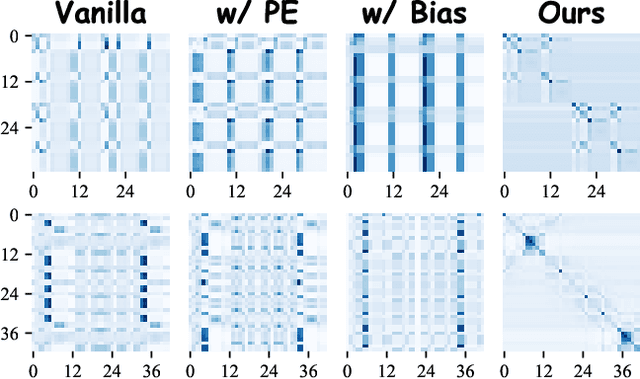
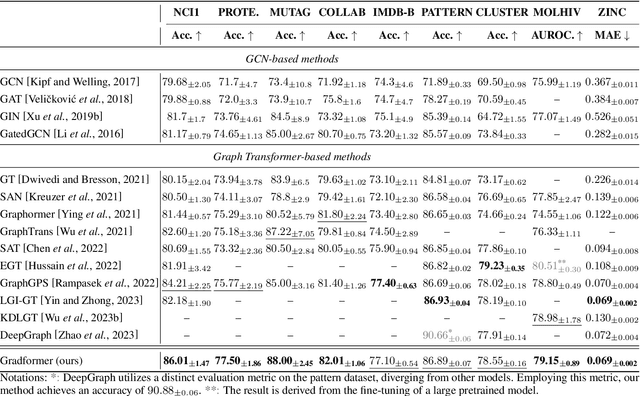
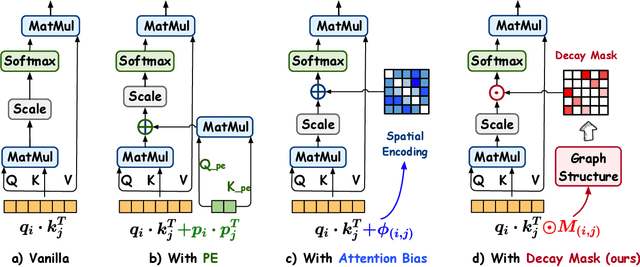
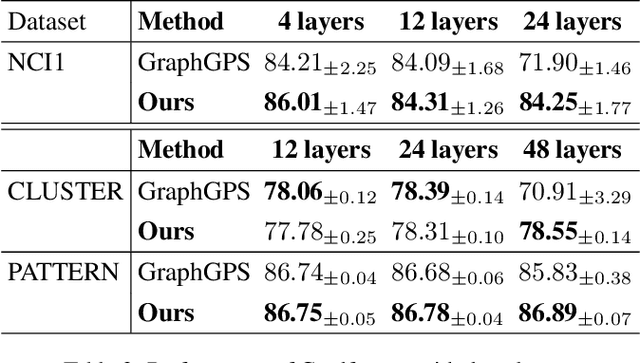
Graph Transformers (GTs) have demonstrated their advantages across a wide range of tasks. However, the self-attention mechanism in GTs overlooks the graph's inductive biases, particularly biases related to structure, which are crucial for the graph tasks. Although some methods utilize positional encoding and attention bias to model inductive biases, their effectiveness is still suboptimal analytically. Therefore, this paper presents Gradformer, a method innovatively integrating GT with the intrinsic inductive bias by applying an exponential decay mask to the attention matrix. Specifically, the values in the decay mask matrix diminish exponentially, correlating with the decreasing node proximities within the graph structure. This design enables Gradformer to retain its ability to capture information from distant nodes while focusing on the graph's local details. Furthermore, Gradformer introduces a learnable constraint into the decay mask, allowing different attention heads to learn distinct decay masks. Such an design diversifies the attention heads, enabling a more effective assimilation of diverse structural information within the graph. Extensive experiments on various benchmarks demonstrate that Gradformer consistently outperforms the Graph Neural Network and GT baseline models in various graph classification and regression tasks. Additionally, Gradformer has proven to be an effective method for training deep GT models, maintaining or even enhancing accuracy compared to shallow models as the network deepens, in contrast to the significant accuracy drop observed in other GT models.Codes are available at \url{https://github.com/LiuChuang0059/Gradformer}.
Where to Mask: Structure-Guided Masking for Graph Masked Autoencoders
Apr 24, 2024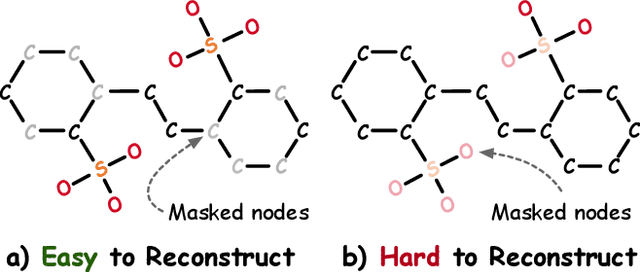
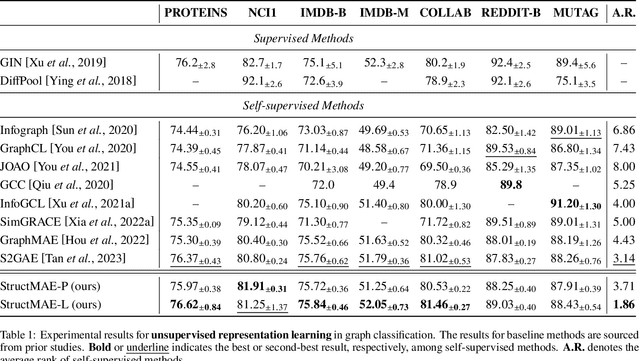
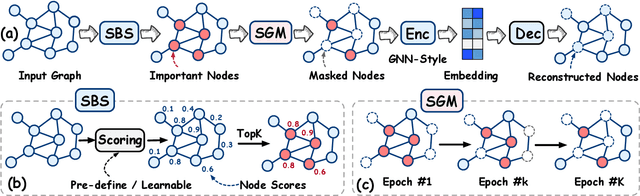
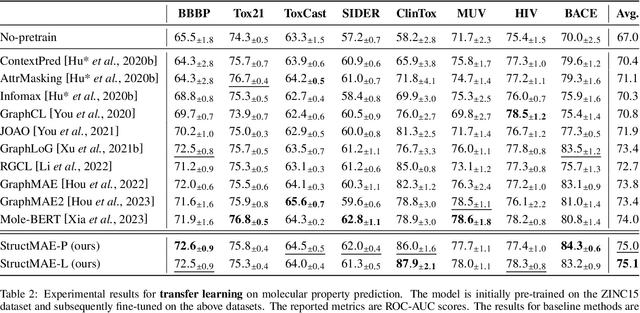
Graph masked autoencoders (GMAE) have emerged as a significant advancement in self-supervised pre-training for graph-structured data. Previous GMAE models primarily utilize a straightforward random masking strategy for nodes or edges during training. However, this strategy fails to consider the varying significance of different nodes within the graph structure. In this paper, we investigate the potential of leveraging the graph's structural composition as a fundamental and unique prior in the masked pre-training process. To this end, we introduce a novel structure-guided masking strategy (i.e., StructMAE), designed to refine the existing GMAE models. StructMAE involves two steps: 1) Structure-based Scoring: Each node is evaluated and assigned a score reflecting its structural significance. Two distinct types of scoring manners are proposed: predefined and learnable scoring. 2) Structure-guided Masking: With the obtained assessment scores, we develop an easy-to-hard masking strategy that gradually increases the structural awareness of the self-supervised reconstruction task. Specifically, the strategy begins with random masking and progresses to masking structure-informative nodes based on the assessment scores. This design gradually and effectively guides the model in learning graph structural information. Furthermore, extensive experiments consistently demonstrate that our StructMAE method outperforms existing state-of-the-art GMAE models in both unsupervised and transfer learning tasks. Codes are available at https://github.com/LiuChuang0059/StructMAE.