 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCo-Initialization of Control Filter and Secondary Path via Meta-Learning for Active Noise Control
Jan 20, 2026Active noise control (ANC) must adapt quickly when the acoustic environment changes, yet early performance is largely dictated by initialization. We address this with a Model-Agnostic Meta-Learning (MAML) co-initialization that jointly sets the control filter and the secondary-path model for FxLMS-based ANC while keeping the runtime algorithm unchanged. The initializer is pre-trained on a small set of measured paths using short two-phase inner loops that mimic identification followed by residual-noise reduction, and is applied by simply setting the learned initial coefficients. In an online secondary path modeling FxLMS testbed, it yields lower early-stage error, shorter time-to-target, reduced auxiliary-noise energy, and faster recovery after path changes than a baseline without re-initialization. The method provides a simple fast start for feedforward ANC under environment changes, requiring a small set of paths to pre-train.
CLR-Wire: Towards Continuous Latent Representations for 3D Curve Wireframe Generation
May 01, 2025We introduce CLR-Wire, a novel framework for 3D curve-based wireframe generation that integrates geometry and topology into a unified Continuous Latent Representation. Unlike conventional methods that decouple vertices, edges, and faces, CLR-Wire encodes curves as Neural Parametric Curves along with their topological connectivity into a continuous and fixed-length latent space using an attention-driven variational autoencoder (VAE). This unified approach facilitates joint learning and generation of both geometry and topology. To generate wireframes, we employ a flow matching model to progressively map Gaussian noise to these latents, which are subsequently decoded into complete 3D wireframes. Our method provides fine-grained modeling of complex shapes and irregular topologies, and supports both unconditional generation and generation conditioned on point cloud or image inputs. Experimental results demonstrate that, compared with state-of-the-art generative approaches, our method achieves substantial improvements in accuracy, novelty, and diversity, offering an efficient and comprehensive solution for CAD design, geometric reconstruction, and 3D content creation.
ArcPro: Architectural Programs for Structured 3D Abstraction of Sparse Points
Mar 05, 2025We introduce ArcPro, a novel learning framework built on architectural programs to recover structured 3D abstractions from highly sparse and low-quality point clouds. Specifically, we design a domain-specific language (DSL) to hierarchically represent building structures as a program, which can be efficiently converted into a mesh. We bridge feedforward and inverse procedural modeling by using a feedforward process for training data synthesis, allowing the network to make reverse predictions. We train an encoder-decoder on the points-program pairs to establish a mapping from unstructured point clouds to architectural programs, where a 3D convolutional encoder extracts point cloud features and a transformer decoder autoregressively predicts the programs in a tokenized form. Inference by our method is highly efficient and produces plausible and faithful 3D abstractions. Comprehensive experiments demonstrate that ArcPro outperforms both traditional architectural proxy reconstruction and learning-based abstraction methods. We further explore its potential to work with multi-view image and natural language inputs.
Spatial features of CO2 for occupancy detection in a naturally ventilated school building
Mar 11, 2024Accurate occupancy information helps to improve building energy efficiency and occupant comfort. Occupancy detection methods based on CO2 sensors have received attention due to their low cost and low intrusiveness. In naturally ventilated buildings, the accuracy of CO2-based occupancy detection is generally low in related studies due to the complex ventilation behavior and the difficulty in measuring the actual air exchange through windows. In this study, we present two novel features for occupancy detection based on the spatial distribution of the CO2 concentration. After a quantitative analysis with Support Vector Machine (SVM) as classifier, it was found that the accuracy of occupancy state detection in naturally ventilated rooms could be improved by up to 14.8 percentage points compared to the baseline, reaching 83.2 % (F1 score 0.84) without any ventilation information. With ventilation information, the accuracy reached 87.6 % (F1 score 0.89). The performance of occupancy quantity detection was significantly improved by up to 25.3 percentage points versus baseline, reaching 56 %, with root mean square error (RMSE) of 11.44 occupants, using only CO2-related features. Additional ventilation information further enhanced the performance to 61.8 % (RMSE 9.02 occupants). By incorporating spatial features, the model using only CO2-related features revealed similar performance as the model containing additional ventilation information, resulting in a better low-cost occupancy detection method for naturally ventilated buildings.
EmoSet: A Large-scale Visual Emotion Dataset with Rich Attributes
Jul 28, 2023Visual Emotion Analysis (VEA) aims at predicting people's emotional responses to visual stimuli. This is a promising, yet challenging, task in affective computing, which has drawn increasing attention in recent years. Most of the existing work in this area focuses on feature design, while little attention has been paid to dataset construction. In this work, we introduce EmoSet, the first large-scale visual emotion dataset annotated with rich attributes, which is superior to existing datasets in four aspects: scale, annotation richness, diversity, and data balance. EmoSet comprises 3.3 million images in total, with 118,102 of these images carefully labeled by human annotators, making it five times larger than the largest existing dataset. EmoSet includes images from social networks, as well as artistic images, and it is well balanced between different emotion categories. Motivated by psychological studies, in addition to emotion category, each image is also annotated with a set of describable emotion attributes: brightness, colorfulness, scene type, object class, facial expression, and human action, which can help understand visual emotions in a precise and interpretable way. The relevance of these emotion attributes is validated by analyzing the correlations between them and visual emotion, as well as by designing an attribute module to help visual emotion recognition. We believe EmoSet will bring some key insights and encourage further research in visual emotion analysis and understanding. Project page: https://vcc.tech/EmoSet.
GenText: Unsupervised Artistic Text Generation via Decoupled Font and Texture Manipulation
Jul 20, 2022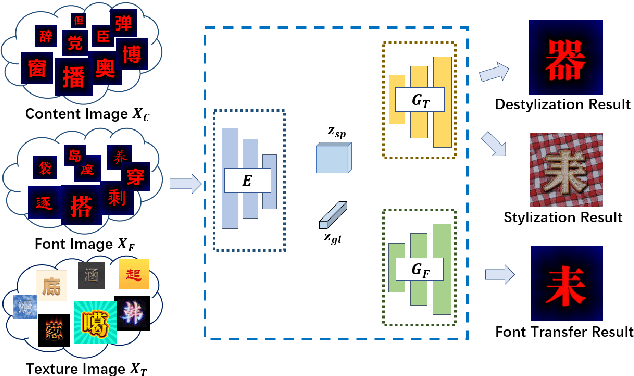
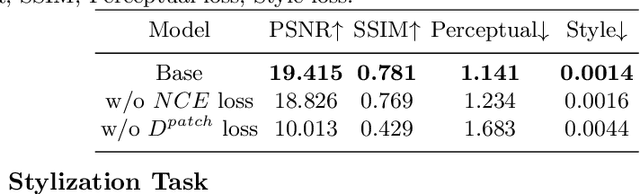
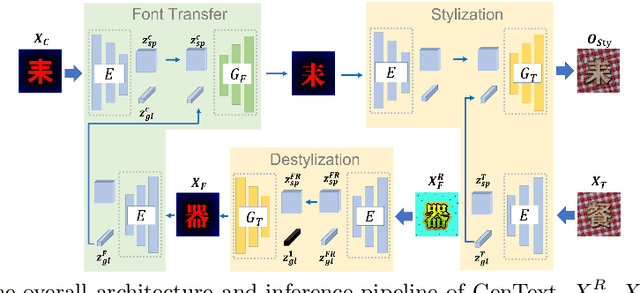
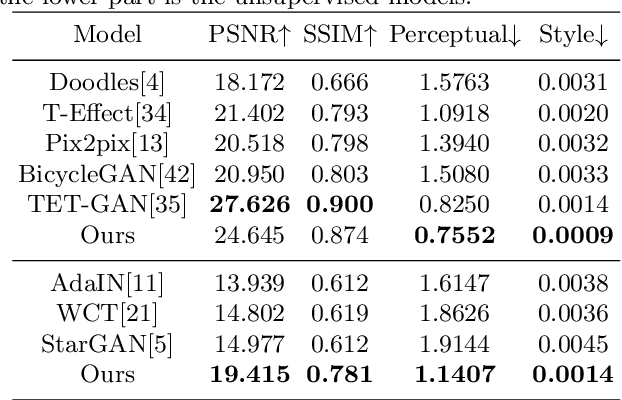
Automatic artistic text generation is an emerging topic which receives increasing attention due to its wide applications. The artistic text can be divided into three components, content, font, and texture, respectively. Existing artistic text generation models usually focus on manipulating one aspect of the above components, which is a sub-optimal solution for controllable general artistic text generation. To remedy this issue, we propose a novel approach, namely GenText, to achieve general artistic text style transfer by separably migrating the font and texture styles from the different source images to the target images in an unsupervised manner. Specifically, our current work incorporates three different stages, stylization, destylization, and font transfer, respectively, into a unified platform with a single powerful encoder network and two separate style generator networks, one for font transfer, the other for stylization and destylization. The destylization stage first extracts the font style of the font reference image, then the font transfer stage generates the target content with the desired font style. Finally, the stylization stage renders the resulted font image with respect to the texture style in the reference image. Moreover, considering the difficult data acquisition of paired artistic text images, our model is designed under the unsupervised setting, where all stages can be effectively optimized from unpaired data. Qualitative and quantitative results are performed on artistic text benchmarks, which demonstrate the superior performance of our proposed model. The code with models will become publicly available in the future.