 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRadioFormer: A Multiple-Granularity Radio Map Estimation Transformer with 1\textpertenthousand Spatial Sampling
Apr 27, 2025The task of radio map estimation aims to generate a dense representation of electromagnetic spectrum quantities, such as the received signal strength at each grid point within a geographic region, based on measurements from a subset of spatially distributed nodes (represented as pixels). Recently, deep vision models such as the U-Net have been adapted to radio map estimation, whose effectiveness can be guaranteed with sufficient spatial observations (typically 0.01% to 1% of pixels) in each map, to model local dependency of observed signal power. However, such a setting of sufficient measurements can be less practical in real-world scenarios, where extreme sparsity in spatial sampling can be widely encountered. To address this challenge, we propose RadioFormer, a novel multiple-granularity transformer designed to handle the constraints posed by spatial sparse observations. Our RadioFormer, through a dual-stream self-attention (DSA) module, can respectively discover the correlation of pixel-wise observed signal power and also learn patch-wise buildings' geometries in a style of multiple granularities, which are integrated into multi-scale representations of radio maps by a cross stream cross-attention (CCA) module. Extensive experiments on the public RadioMapSeer dataset demonstrate that RadioFormer outperforms state-of-the-art methods in radio map estimation while maintaining the lowest computational cost. Furthermore, the proposed approach exhibits exceptional generalization capabilities and robust zero-shot performance, underscoring its potential to advance radio map estimation in a more practical setting with very limited observation nodes.
Delving Deep into Semantic Relation Distillation
Mar 27, 2025Knowledge distillation has become a cornerstone technique in deep learning, facilitating the transfer of knowledge from complex models to lightweight counterparts. Traditional distillation approaches focus on transferring knowledge at the instance level, but fail to capture nuanced semantic relationships within the data. In response, this paper introduces a novel methodology, Semantics-based Relation Knowledge Distillation (SeRKD), which reimagines knowledge distillation through a semantics-relation lens among each sample. By leveraging semantic components, \ie, superpixels, SeRKD enables a more comprehensive and context-aware transfer of knowledge, which skillfully integrates superpixel-based semantic extraction with relation-based knowledge distillation for a sophisticated model compression and distillation. Particularly, the proposed method is naturally relevant in the domain of Vision Transformers (ViTs), where visual tokens serve as fundamental units of representation. Experimental evaluations on benchmark datasets demonstrate the superiority of SeRKD over existing methods, underscoring its efficacy in enhancing model performance and generalization capabilities.
ArcPro: Architectural Programs for Structured 3D Abstraction of Sparse Points
Mar 05, 2025We introduce ArcPro, a novel learning framework built on architectural programs to recover structured 3D abstractions from highly sparse and low-quality point clouds. Specifically, we design a domain-specific language (DSL) to hierarchically represent building structures as a program, which can be efficiently converted into a mesh. We bridge feedforward and inverse procedural modeling by using a feedforward process for training data synthesis, allowing the network to make reverse predictions. We train an encoder-decoder on the points-program pairs to establish a mapping from unstructured point clouds to architectural programs, where a 3D convolutional encoder extracts point cloud features and a transformer decoder autoregressively predicts the programs in a tokenized form. Inference by our method is highly efficient and produces plausible and faithful 3D abstractions. Comprehensive experiments demonstrate that ArcPro outperforms both traditional architectural proxy reconstruction and learning-based abstraction methods. We further explore its potential to work with multi-view image and natural language inputs.
Improving Deep Representation Learning via Auxiliary Learnable Target Coding
May 30, 2023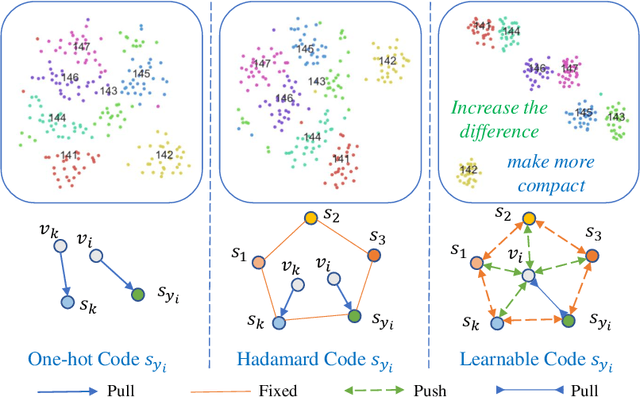
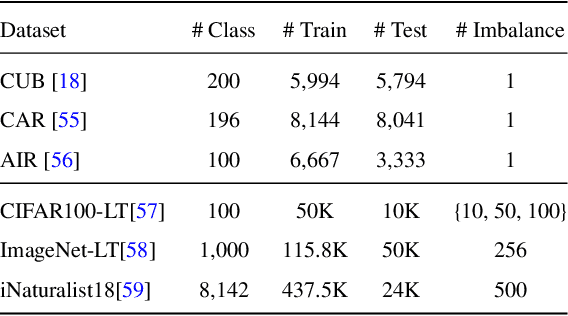
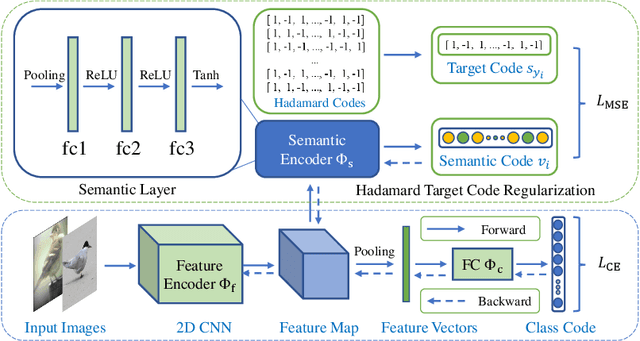
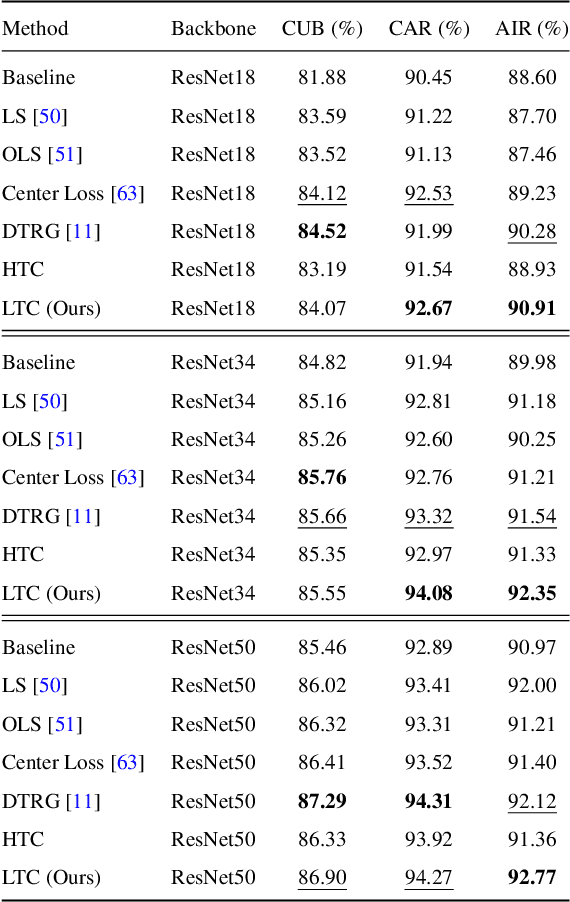
Deep representation learning is a subfield of machine learning that focuses on learning meaningful and useful representations of data through deep neural networks. However, existing methods for semantic classification typically employ pre-defined target codes such as the one-hot and the Hadamard codes, which can either fail or be less flexible to model inter-class correlation. In light of this, this paper introduces a novel learnable target coding as an auxiliary regularization of deep representation learning, which can not only incorporate latent dependency across classes but also impose geometric properties of target codes into representation space. Specifically, a margin-based triplet loss and a correlation consistency loss on the proposed target codes are designed to encourage more discriminative representations owing to enlarging between-class margins in representation space and favoring equal semantic correlation of learnable target codes respectively. Experimental results on several popular visual classification and retrieval benchmarks can demonstrate the effectiveness of our method on improving representation learning, especially for imbalanced data.
ShuffleMix: Improving Representations via Channel-Wise Shuffle of Interpolated Hidden States
May 30, 2023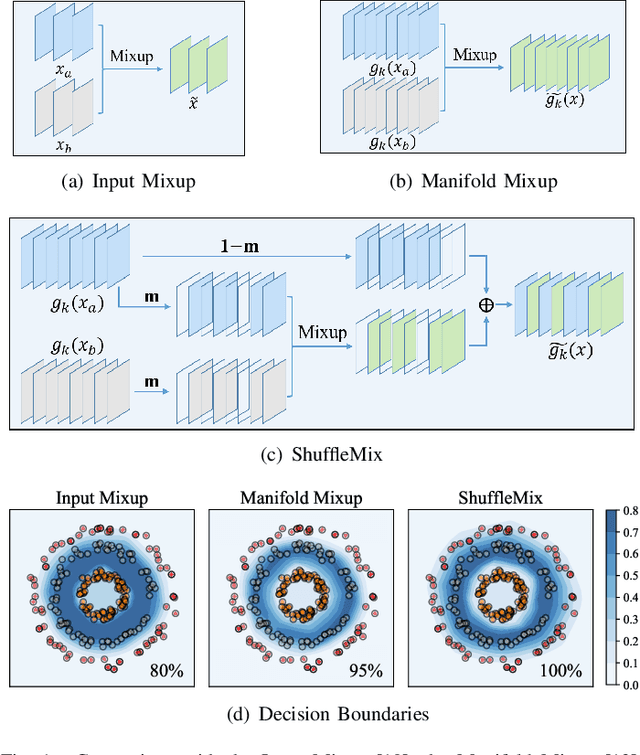

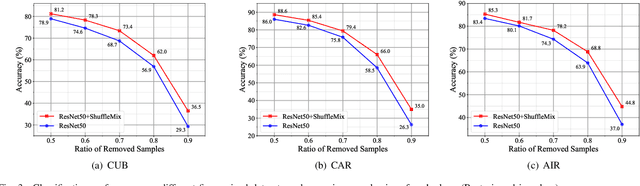
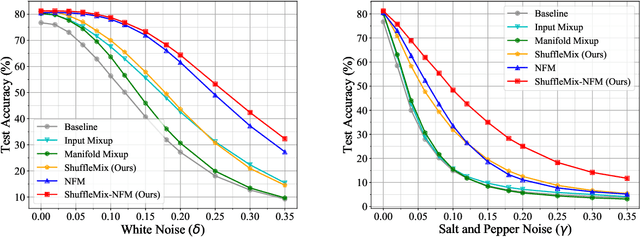
Mixup style data augmentation algorithms have been widely adopted in various tasks as implicit network regularization on representation learning to improve model generalization, which can be achieved by a linear interpolation of labeled samples in input or feature space as well as target space. Inspired by good robustness of alternative dropout strategies against over-fitting on limited patterns of training samples, this paper introduces a novel concept of ShuffleMix -- Shuffle of Mixed hidden features, which can be interpreted as a kind of dropout operation in feature space. Specifically, our ShuffleMix method favors a simple linear shuffle of randomly selected feature channels for feature mixup in-between training samples to leverage semantic interpolated supervision signals, which can be extended to a generalized shuffle operation via additionally combining linear interpolations of intra-channel features. Compared to its direct competitor of feature augmentation -- the Manifold Mixup, the proposed ShuffleMix can gain superior generalization, owing to imposing more flexible and smooth constraints on generating samples and achieving regularization effects of channel-wise feature dropout. Experimental results on several public benchmarking datasets of single-label and multi-label visual classification tasks can confirm the effectiveness of our method on consistently improving representations over the state-of-the-art mixup augmentation.
Convolutional Fine-Grained Classification with Self-Supervised Target Relation Regularization
Aug 03, 2022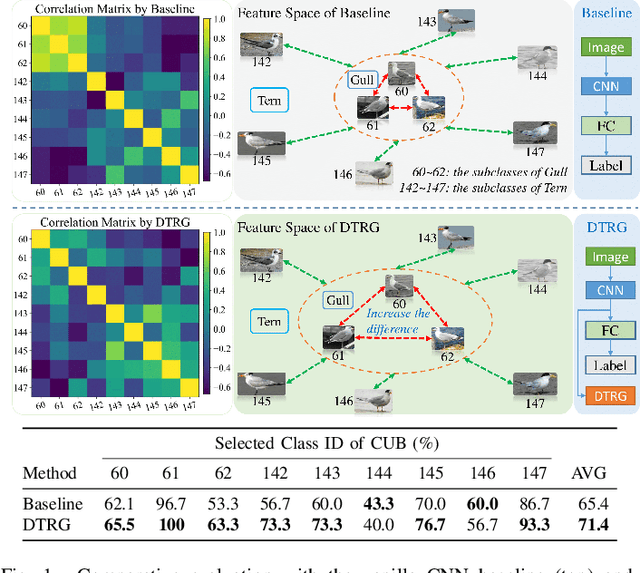
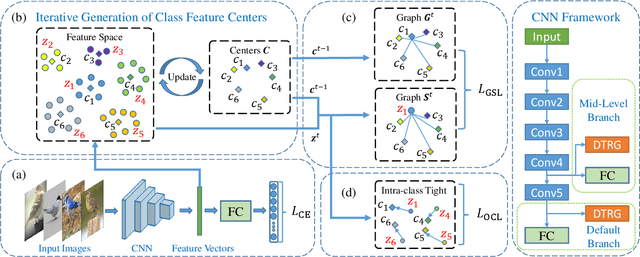

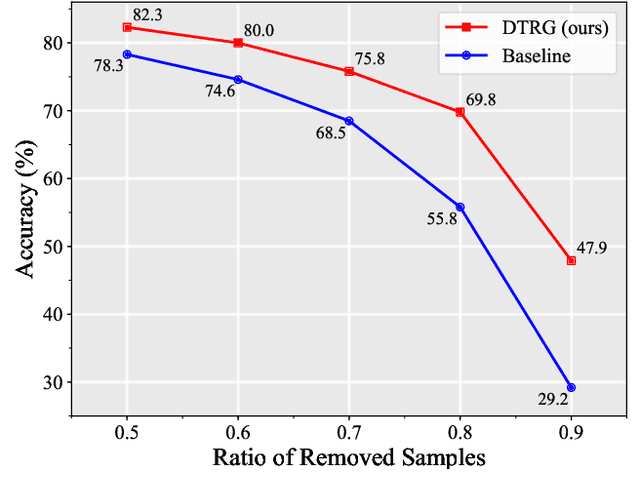
Fine-grained visual classification can be addressed by deep representation learning under supervision of manually pre-defined targets (e.g., one-hot or the Hadamard codes). Such target coding schemes are less flexible to model inter-class correlation and are sensitive to sparse and imbalanced data distribution as well. In light of this, this paper introduces a novel target coding scheme -- dynamic target relation graphs (DTRG), which, as an auxiliary feature regularization, is a self-generated structural output to be mapped from input images. Specifically, online computation of class-level feature centers is designed to generate cross-category distance in the representation space, which can thus be depicted by a dynamic graph in a non-parametric manner. Explicitly minimizing intra-class feature variations anchored on those class-level centers can encourage learning of discriminative features. Moreover, owing to exploiting inter-class dependency, the proposed target graphs can alleviate data sparsity and imbalanceness in representation learning. Inspired by recent success of the mixup style data augmentation, this paper introduces randomness into soft construction of dynamic target relation graphs to further explore relation diversity of target classes. Experimental results can demonstrate the effectiveness of our method on a number of diverse benchmarks of multiple visual classification tasks, especially achieving the state-of-the-art performance on popular fine-grained object benchmarks and superior robustness against sparse and imbalanced data. Source codes are made publicly available at https://github.com/AkonLau/DTRG.