 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage Classification with Deep Reinforcement Active Learning
Dec 27, 2024



Deep learning is currently reaching outstanding performances on different tasks, including image classification, especially when using large neural networks. The success of these models is tributary to the availability of large collections of labeled training data. In many real-world scenarios, labeled data are scarce, and their hand-labeling is time, effort and cost demanding. Active learning is an alternative paradigm that mitigates the effort in hand-labeling data, where only a small fraction is iteratively selected from a large pool of unlabeled data, and annotated by an expert (a.k.a oracle), and eventually used to update the learning models. However, existing active learning solutions are dependent on handcrafted strategies that may fail in highly variable learning environments (datasets, scenarios, etc). In this work, we devise an adaptive active learning method based on Markov Decision Process (MDP). Our framework leverages deep reinforcement learning and active learning together with a Deep Deterministic Policy Gradient (DDPG) in order to dynamically adapt sample selection strategies to the oracle's feedback and the learning environment. Extensive experiments conducted on three different image classification benchmarks show superior performances against several existing active learning strategies.
Boosting Cross-Domain Point Classification via Distilling Relational Priors from 2D Transformers
Jul 26, 2024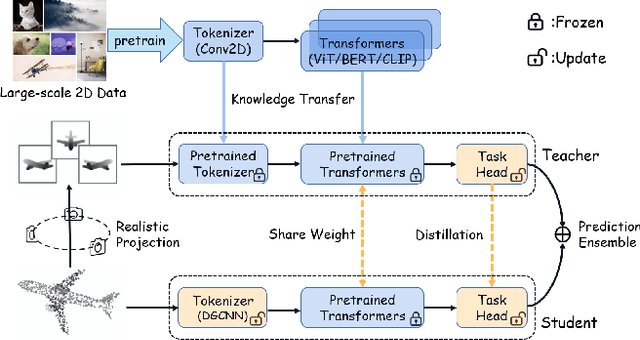
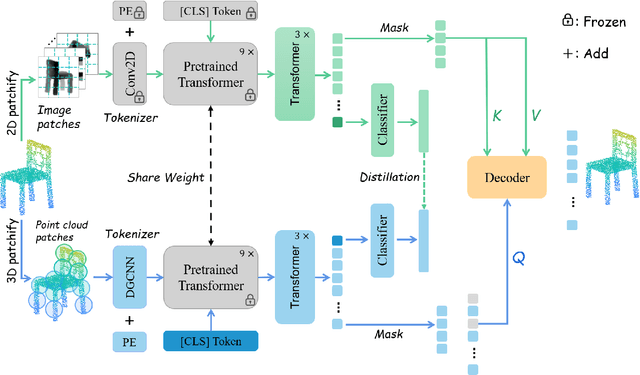
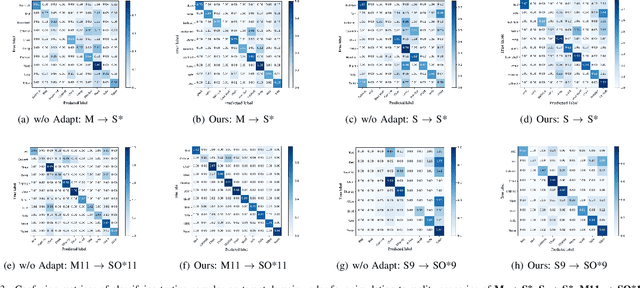
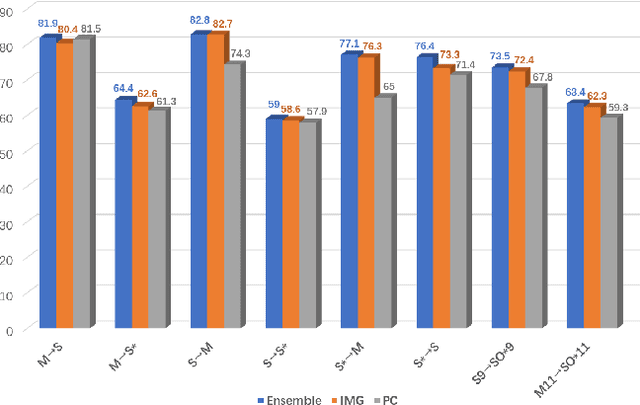
Semantic pattern of an object point cloud is determined by its topological configuration of local geometries. Learning discriminative representations can be challenging due to large shape variations of point sets in local regions and incomplete surface in a global perspective, which can be made even more severe in the context of unsupervised domain adaptation (UDA). In specific, traditional 3D networks mainly focus on local geometric details and ignore the topological structure between local geometries, which greatly limits their cross-domain generalization. Recently, the transformer-based models have achieved impressive performance gain in a range of image-based tasks, benefiting from its strong generalization capability and scalability stemming from capturing long range correlation across local patches. Inspired by such successes of visual transformers, we propose a novel Relational Priors Distillation (RPD) method to extract relational priors from the well-trained transformers on massive images, which can significantly empower cross-domain representations with consistent topological priors of objects. To this end, we establish a parameter-frozen pre-trained transformer module shared between 2D teacher and 3D student models, complemented by an online knowledge distillation strategy for semantically regularizing the 3D student model. Furthermore, we introduce a novel self-supervised task centered on reconstructing masked point cloud patches using corresponding masked multi-view image features, thereby empowering the model with incorporating 3D geometric information. Experiments on the PointDA-10 and the Sim-to-Real datasets verify that the proposed method consistently achieves the state-of-the-art performance of UDA for point cloud classification. The source code of this work is available at https://github.com/zou-longkun/RPD.git.
Evaluation of Multi-indicator And Multi-organ Medical Image Segmentation Models
Jun 01, 2023



In recent years, "U-shaped" neural networks featuring encoder and decoder structures have gained popularity in the field of medical image segmentation. Various variants of this model have been developed. Nevertheless, the evaluation of these models has received less attention compared to model development. In response, we propose a comprehensive method for evaluating medical image segmentation models for multi-indicator and multi-organ (named MIMO). MIMO allows models to generate independent thresholds which are then combined with multi-indicator evaluation and confidence estimation to screen and measure each organ. As a result, MIMO offers detailed information on the segmentation of each organ in each sample, thereby aiding developers in analyzing and improving the model. Additionally, MIMO can produce concise usability and comprehensiveness scores for different models. Models with higher scores are deemed to be excellent models, which is convenient for clinical evaluation. Our research tests eight different medical image segmentation models on two abdominal multi-organ datasets and evaluates them from four perspectives: correctness, confidence estimation, Usable Region and MIMO. Furthermore, robustness experiments are tested. Experimental results demonstrate that MIMO offers novel insights into multi-indicator and multi-organ medical image evaluation and provides a specific and concise measure for the usability and comprehensiveness of the model. Code: https://github.com/SCUT-ML-GUO/MIMO
ShuffleMix: Improving Representations via Channel-Wise Shuffle of Interpolated Hidden States
May 30, 2023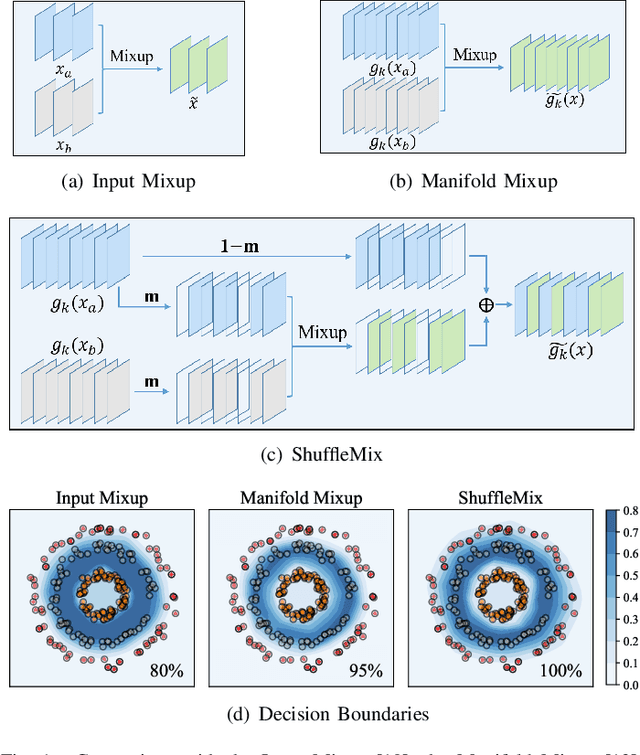

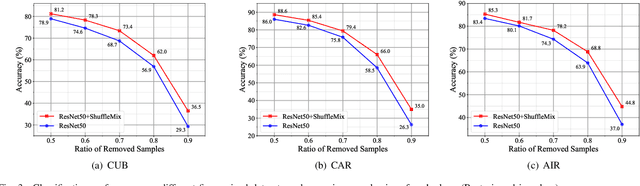
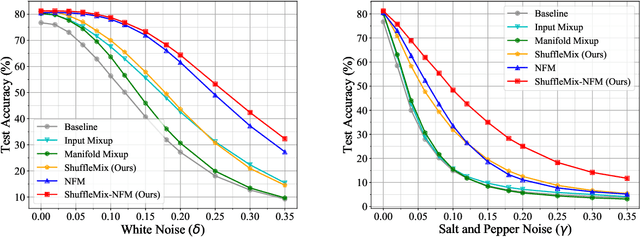
Mixup style data augmentation algorithms have been widely adopted in various tasks as implicit network regularization on representation learning to improve model generalization, which can be achieved by a linear interpolation of labeled samples in input or feature space as well as target space. Inspired by good robustness of alternative dropout strategies against over-fitting on limited patterns of training samples, this paper introduces a novel concept of ShuffleMix -- Shuffle of Mixed hidden features, which can be interpreted as a kind of dropout operation in feature space. Specifically, our ShuffleMix method favors a simple linear shuffle of randomly selected feature channels for feature mixup in-between training samples to leverage semantic interpolated supervision signals, which can be extended to a generalized shuffle operation via additionally combining linear interpolations of intra-channel features. Compared to its direct competitor of feature augmentation -- the Manifold Mixup, the proposed ShuffleMix can gain superior generalization, owing to imposing more flexible and smooth constraints on generating samples and achieving regularization effects of channel-wise feature dropout. Experimental results on several public benchmarking datasets of single-label and multi-label visual classification tasks can confirm the effectiveness of our method on consistently improving representations over the state-of-the-art mixup augmentation.
A Subabdominal MRI Image Segmentation Algorithm Based on Multi-Scale Feature Pyramid Network and Dual Attention Mechanism
May 19, 2023This study aimed to solve the semantic gap and misalignment issue between encoding and decoding because of multiple convolutional and pooling operations in U-Net when segmenting subabdominal MRI images during rectal cancer treatment. A MRI Image Segmentation is proposed based on a multi-scale feature pyramid network and dual attention mechanism. Our innovation is the design of two modules: 1) a dilated convolution and multi-scale feature pyramid network are used in the encoding to avoid the semantic gap. 2) a dual attention mechanism is designed to maintain spatial information of U-Net and reduce misalignment. Experiments on a subabdominal MRI image dataset show the proposed method achieves better performance than others methods. In conclusion, a multi-scale feature pyramid network can reduce the semantic gap, and the dual attention mechanism can make an alignment of features between encoding and decoding.
SECP-Net: SE-Connection Pyramid Network of Organ At Risk Segmentation for Nasopharyngeal Carcinoma
Dec 28, 2021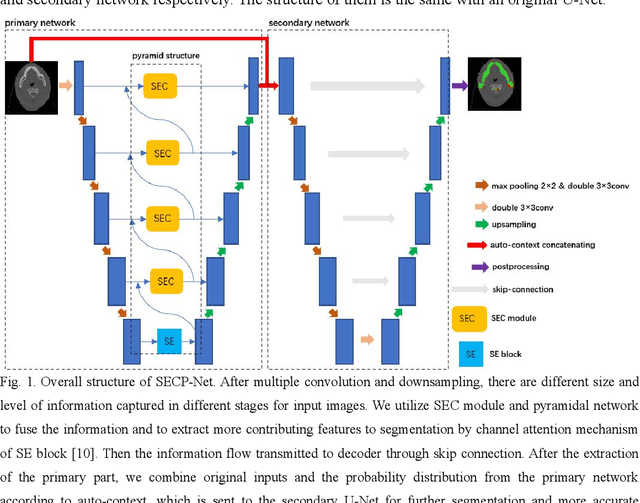
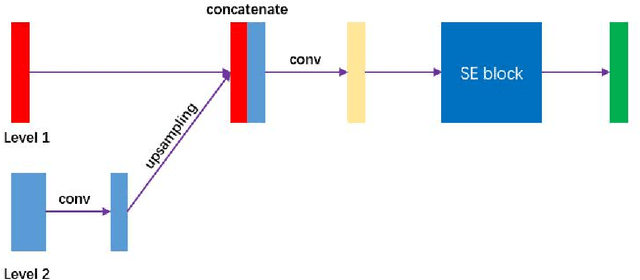
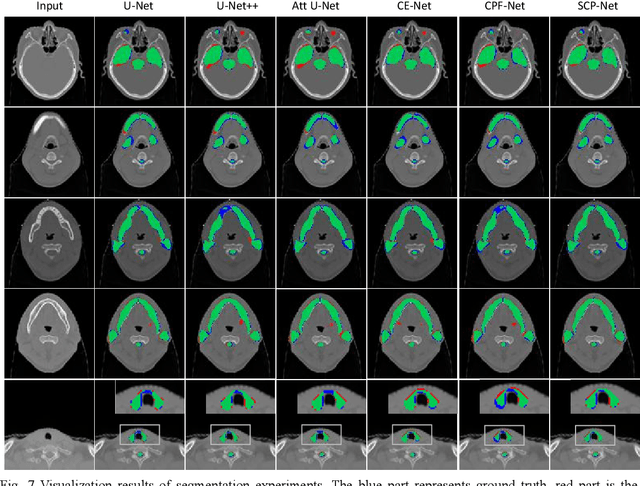
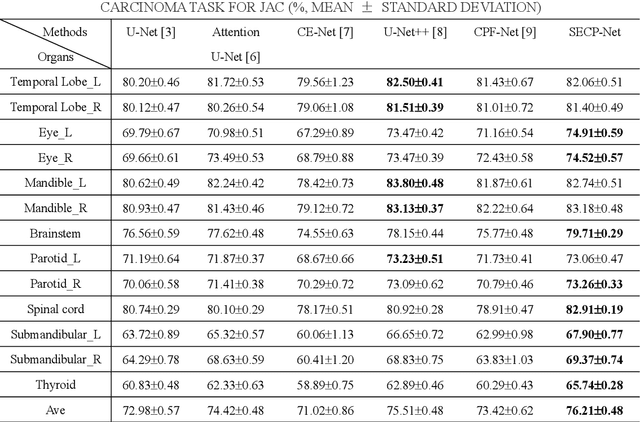
Nasopharyngeal carcinoma (NPC) is a kind of malignant tumor. Accurate and automatic segmentation of organs at risk (OAR) of computed tomography (CT) images is clinically significant. In recent years, deep learning models represented by U-Net have been widely applied in medical image segmentation tasks, which can help doctors with reduction of workload and get accurate results more quickly. In OAR segmentation of NPC, the sizes of OAR are variable, especially, some of them are small. Traditional deep neural networks underperform during segmentation due to the lack use of global and multi-size information. This paper proposes a new SE-Connection Pyramid Network (SECP-Net). SECP-Net extracts global and multi-size information flow with se connection (SEC) modules and a pyramid structure of network for improving the segmentation performance, especially that of small organs. SECP-Net also designs an auto-context cascaded network to further improve the segmentation performance. Comparative experiments are conducted between SECP-Net and other recently methods on a dataset with CT images of head and neck. Five-fold cross validation is used to evaluate the performance based on two metrics, i.e., Dice and Jaccard similarity. Experimental results show that SECP-Net can achieve SOTA performance in this challenging task.
PARN: Position-Aware Relation Networks for Few-Shot Learning
Sep 10, 2019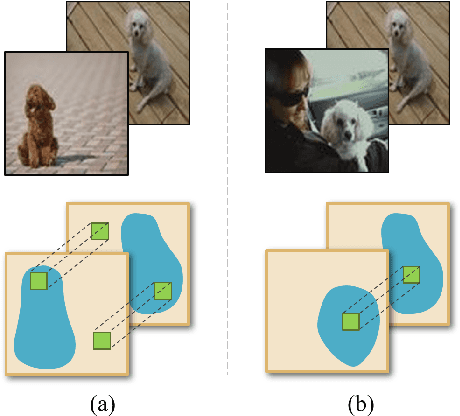
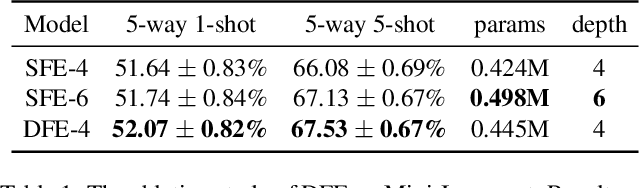
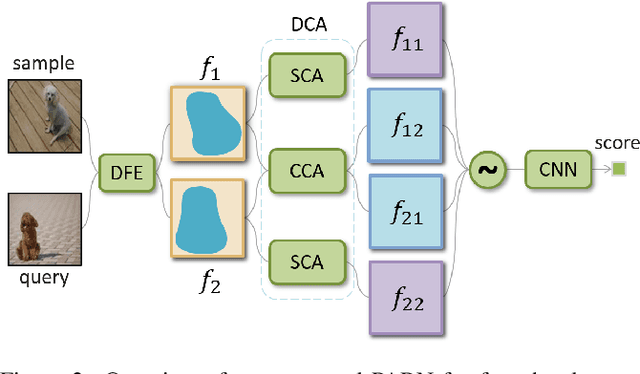
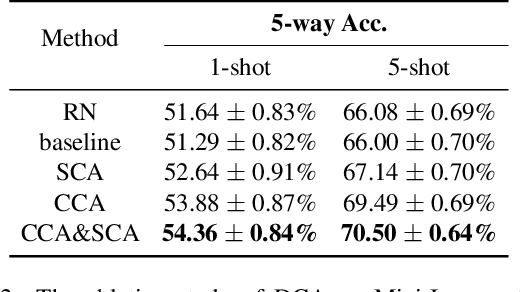
Few-shot learning presents a challenge that a classifier must quickly adapt to new classes that do not appear in the training set, given only a few labeled examples of each new class. This paper proposes a position-aware relation network (PARN) to learn a more flexible and robust metric ability for few-shot learning. Relation networks (RNs), a kind of architectures for relational reasoning, can acquire a deep metric ability for images by just being designed as a simple convolutional neural network (CNN) [23]. However, due to the inherent local connectivity of CNN, the CNN-based relation network (RN) can be sensitive to the spatial position relationship of semantic objects in two compared images. To address this problem, we introduce a deformable feature extractor (DFE) to extract more efficient features, and design a dual correlation attention mechanism (DCA) to deal with its inherent local connectivity. Successfully, our proposed approach extents the potential of RN to be position-aware of semantic objects by introducing only a small number of parameters. We evaluate our approach on two major benchmark datasets, i.e., Omniglot and Mini-Imagenet, and on both of the datasets our approach achieves state-of-the-art performance with the setting of using a shallow feature extraction network. It's worth noting that our 5-way 1-shot result on Omniglot even outperforms the previous 5-way 5-shot results.