 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-label Classification with Panoptic Context Aggregation Networks
Dec 29, 2025Context modeling is crucial for visual recognition, enabling highly discriminative image representations by integrating both intrinsic and extrinsic relationships between objects and labels in images. A limitation in current approaches is their focus on basic geometric relationships or localized features, often neglecting cross-scale contextual interactions between objects. This paper introduces the Deep Panoptic Context Aggregation Network (PanCAN), a novel approach that hierarchically integrates multi-order geometric contexts through cross-scale feature aggregation in a high-dimensional Hilbert space. Specifically, PanCAN learns multi-order neighborhood relationships at each scale by combining random walks with an attention mechanism. Modules from different scales are cascaded, where salient anchors at a finer scale are selected and their neighborhood features are dynamically fused via attention. This enables effective cross-scale modeling that significantly enhances complex scene understanding by combining multi-order and cross-scale context-aware features. Extensive multi-label classification experiments on NUS-WIDE, PASCAL VOC2007, and MS-COCO benchmarks demonstrate that PanCAN consistently achieves competitive results, outperforming state-of-the-art techniques in both quantitative and qualitative evaluations, thereby substantially improving multi-label classification performance.
NTIRE 2025 Challenge on Cross-Domain Few-Shot Object Detection: Methods and Results
Apr 14, 2025Cross-Domain Few-Shot Object Detection (CD-FSOD) poses significant challenges to existing object detection and few-shot detection models when applied across domains. In conjunction with NTIRE 2025, we organized the 1st CD-FSOD Challenge, aiming to advance the performance of current object detectors on entirely novel target domains with only limited labeled data. The challenge attracted 152 registered participants, received submissions from 42 teams, and concluded with 13 teams making valid final submissions. Participants approached the task from diverse perspectives, proposing novel models that achieved new state-of-the-art (SOTA) results under both open-source and closed-source settings. In this report, we present an overview of the 1st NTIRE 2025 CD-FSOD Challenge, highlighting the proposed solutions and summarizing the results submitted by the participants.
Multi-label Classification using Deep Multi-order Context-aware Kernel Networks
Dec 27, 2024Multi-label classification is a challenging task in pattern recognition. Many deep learning methods have been proposed and largely enhanced classification performance. However, most of the existing sophisticated methods ignore context in the models' learning process. Since context may provide additional cues to the learned models, it may significantly boost classification performances. In this work, we make full use of context information (namely geometrical structure of images) in order to learn better context-aware similarities (a.k.a. kernels) between images. We reformulate context-aware kernel design as a feed-forward network that outputs explicit kernel mapping features. Our obtained context-aware kernel network further leverages multiple orders of patch neighbors within different distances, resulting into a more discriminating Deep Multi-order Context-aware Kernel Network (DMCKN) for multi-label classification. We evaluate the proposed method on the challenging Corel5K and NUS-WIDE benchmarks, and empirical results show that our method obtains competitive performances against the related state-of-the-art, and both quantitative and qualitative performances corroborate its effectiveness and superiority for multi-label image classification.
Image Classification with Deep Reinforcement Active Learning
Dec 27, 2024



Deep learning is currently reaching outstanding performances on different tasks, including image classification, especially when using large neural networks. The success of these models is tributary to the availability of large collections of labeled training data. In many real-world scenarios, labeled data are scarce, and their hand-labeling is time, effort and cost demanding. Active learning is an alternative paradigm that mitigates the effort in hand-labeling data, where only a small fraction is iteratively selected from a large pool of unlabeled data, and annotated by an expert (a.k.a oracle), and eventually used to update the learning models. However, existing active learning solutions are dependent on handcrafted strategies that may fail in highly variable learning environments (datasets, scenarios, etc). In this work, we devise an adaptive active learning method based on Markov Decision Process (MDP). Our framework leverages deep reinforcement learning and active learning together with a Deep Deterministic Policy Gradient (DDPG) in order to dynamically adapt sample selection strategies to the oracle's feedback and the learning environment. Extensive experiments conducted on three different image classification benchmarks show superior performances against several existing active learning strategies.
Few-Shot Object Detection with Sparse Context Transformers
Feb 14, 2024



Few-shot detection is a major task in pattern recognition which seeks to localize objects using models trained with few labeled data. One of the mainstream few-shot methods is transfer learning which consists in pretraining a detection model in a source domain prior to its fine-tuning in a target domain. However, it is challenging for fine-tuned models to effectively identify new classes in the target domain, particularly when the underlying labeled training data are scarce. In this paper, we devise a novel sparse context transformer (SCT) that effectively leverages object knowledge in the source domain, and automatically learns a sparse context from only few training images in the target domain. As a result, it combines different relevant clues in order to enhance the discrimination power of the learned detectors and reduce class confusion. We evaluate the proposed method on two challenging few-shot object detection benchmarks, and empirical results show that the proposed method obtains competitive performance compared to the related state-of-the-art.
Alternative design of DeepPDNet in the context of image restoration
Feb 20, 2022
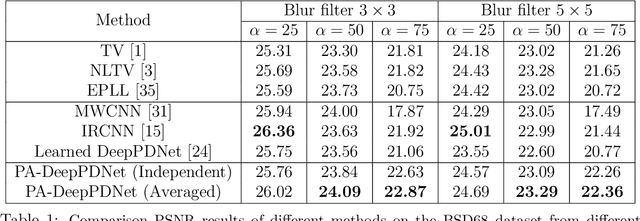
This work designs an image restoration deep network relying on unfolded Chambolle-Pock primal-dual iterations. Each layer of our network is built from Chambolle-Pock iterations when specified for minimizing a sum of a $\ell_2$-norm data-term and an analysis sparse prior. The parameters of our network are the step-sizes of the Chambolle-Pock scheme and the linear operator involved in sparsity-based penalization, including implicitly the regularization parameter. A backpropagation procedure is fully described. Preliminary experiments illustrate the good behavior of such a deep primal-dual network in the context of image restoration on BSD68 database.
Image Annotation based on Deep Hierarchical Context Networks
Dec 21, 2020


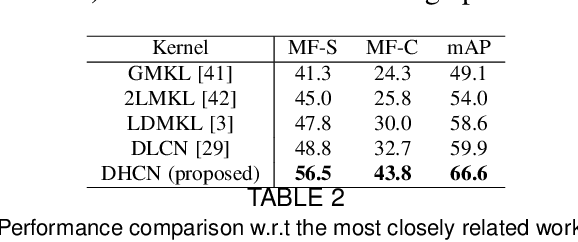
Context modeling is one of the most fertile subfields of visual recognition which aims at designing discriminant image representations while incorporating their intrinsic and extrinsic relationships. However, the potential of context modeling is currently underexplored and most of the existing solutions are either context-free or restricted to simple handcrafted geometric relationships. We introduce in this paper DHCN: a novel Deep Hierarchical Context Network that leverages different sources of contexts including geometric and semantic relationships. The proposed method is based on the minimization of an objective function mixing a fidelity term, a context criterion and a regularizer. The solution of this objective function defines the architecture of a bi-level hierarchical context network; the first level of this network captures scene geometry while the second one corresponds to semantic relationships. We solve this representation learning problem by training its underlying deep network whose parameters correspond to the most influencing bi-level contextual relationships and we evaluate its performances on image annotation using the challenging ImageCLEF benchmark.
A deep primal-dual proximal network for image restoration
Jul 02, 2020

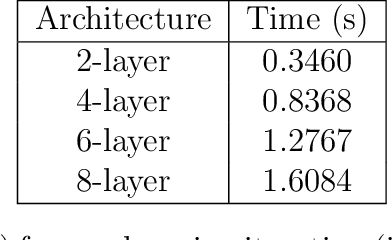
Image restoration remains a challenging task in image processing. Numerous methods have been proposed to tackle this problem, which is often solved by minimizing a non-smooth penalized likelihood function. Although the solution is easily interpretable with theoretic guarantees, its estimation relies on an optimization process. Considering the important research efforts in deep learning for image classification, they offers an alternative to perform image restoration but its adaptation to inverse problem is still challenging. In this work, we design a deep network, named DeepPDNet, built from primal-dual proximal iterations associated with the minimization of a standard penalized likelihood with an analysis prior, allowing us to take advantages from both worlds. We reformulate a specific instance of the Condat-Vu primal-dual hybrid gradient (PDHG) algorithm as a deep network with fixed layers. Each layer corresponds to one iteration of the primal-dual algorithm. The learned parameters are the primal-dual proximal algorithm step-size and the analysis linear operator involved in the penalization. These parameters are allowed to vary from a layer to another one. Two different learning strategies: "Full learning" and "Partial learning" are proposed, the first one is the most efficient numerically while the second one relies on standard constraints insuring convergence in the standard PDHG iterations. Moreover, global and local sparse analysis prior are studied to seek the better feature representation. We experiment the proposed DeepPDNet on the MNIST and BSD68 datasets with different blur and additive Gaussian noise. Extensive results shows that the proposed deep primal-dual proximal networks demonstrate excellent performance on the MNIST dataset compared to other state-of-the-art methods and better or at least comparable performance on the more complex BSD68 dataset.
End-to-end training of deep kernel map networks for image classification
Jun 26, 2020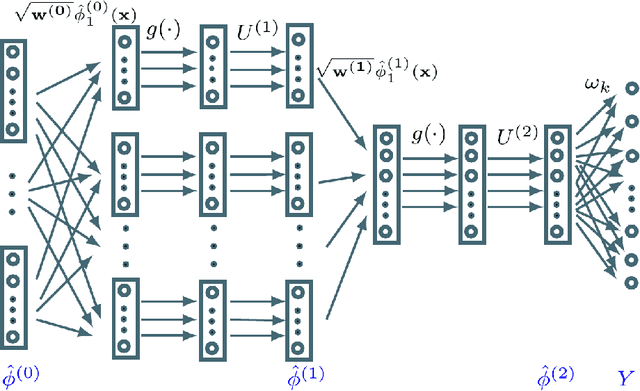



Deep kernel map networks have shown excellent performances in various classification problems including image annotation. Their general recipe consists in aggregating several layers of singular value decompositions (SVDs) -- that map data from input spaces into high dimensional spaces -- while preserving the similarity of the underlying kernels. However, the potential of these deep map networks has not been fully explored as the original setting of these networks focuses mainly on the approximation quality of their kernels and ignores their discrimination power. In this paper, we introduce a novel "end-to-end" design for deep kernel map learning that balances the approximation quality of kernels and their discrimination power. Our method proceeds in two steps; first, layerwise SVD is applied in order to build initial deep kernel map approximations and then an "end-to-end" supervised learning is employed to further enhance their discrimination power while maintaining their efficiency. Extensive experiments, conducted on the challenging ImageCLEF annotation benchmark, show the high efficiency and the out-performance of this two-step process with respect to different related methods.
Deep Context-Aware Kernel Networks
Dec 29, 2019
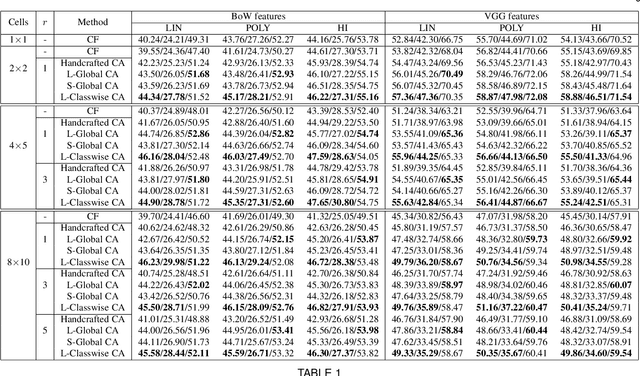

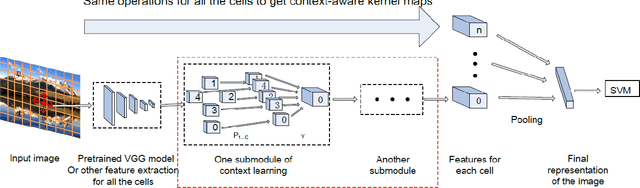
Context plays a crucial role in visual recognition as it provides complementary clues for different learning tasks including image classification and annotation. As the performances of these tasks are currently reaching a plateau, any extra knowledge, including context, should be leveraged in order to seek significant leaps in these performances. In the particular scenario of kernel machines, context-aware kernel design aims at learning positive semi-definite similarity functions which return high values not only when data share similar contents, but also similar structures (a.k.a contexts). However, the use of context in kernel design has not been fully explored; indeed, context in these solutions is handcrafted instead of being learned. In this paper, we introduce a novel deep network architecture that learns context in kernel design. This architecture is fully determined by the solution of an objective function mixing a content term that captures the intrinsic similarity between data, a context criterion which models their structure and a regularization term that helps designing smooth kernel network representations. The solution of this objective function defines a particular deep network architecture whose parameters correspond to different variants of learned contexts including layerwise, stationary and classwise; larger values of these parameters correspond to the most influencing contextual relationships between data. Extensive experiments conducted on the challenging ImageCLEF Photo Annotation and Corel5k benchmarks show that our deep context networks are highly effective for image classification and the learned contexts further enhance the performance of image annotation.