 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-end training of deep kernel map networks for image classification
Paper and Code
Jun 26, 2020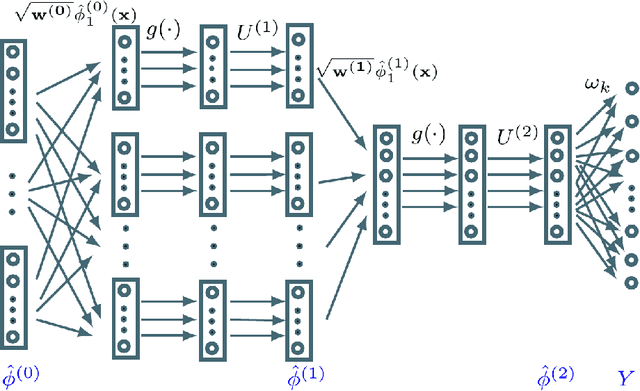



Deep kernel map networks have shown excellent performances in various classification problems including image annotation. Their general recipe consists in aggregating several layers of singular value decompositions (SVDs) -- that map data from input spaces into high dimensional spaces -- while preserving the similarity of the underlying kernels. However, the potential of these deep map networks has not been fully explored as the original setting of these networks focuses mainly on the approximation quality of their kernels and ignores their discrimination power. In this paper, we introduce a novel "end-to-end" design for deep kernel map learning that balances the approximation quality of kernels and their discrimination power. Our method proceeds in two steps; first, layerwise SVD is applied in order to build initial deep kernel map approximations and then an "end-to-end" supervised learning is employed to further enhance their discrimination power while maintaining their efficiency. Extensive experiments, conducted on the challenging ImageCLEF annotation benchmark, show the high efficiency and the out-performance of this two-step process with respect to different related methods.