 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-label Classification with Panoptic Context Aggregation Networks
Dec 29, 2025Context modeling is crucial for visual recognition, enabling highly discriminative image representations by integrating both intrinsic and extrinsic relationships between objects and labels in images. A limitation in current approaches is their focus on basic geometric relationships or localized features, often neglecting cross-scale contextual interactions between objects. This paper introduces the Deep Panoptic Context Aggregation Network (PanCAN), a novel approach that hierarchically integrates multi-order geometric contexts through cross-scale feature aggregation in a high-dimensional Hilbert space. Specifically, PanCAN learns multi-order neighborhood relationships at each scale by combining random walks with an attention mechanism. Modules from different scales are cascaded, where salient anchors at a finer scale are selected and their neighborhood features are dynamically fused via attention. This enables effective cross-scale modeling that significantly enhances complex scene understanding by combining multi-order and cross-scale context-aware features. Extensive multi-label classification experiments on NUS-WIDE, PASCAL VOC2007, and MS-COCO benchmarks demonstrate that PanCAN consistently achieves competitive results, outperforming state-of-the-art techniques in both quantitative and qualitative evaluations, thereby substantially improving multi-label classification performance.
Label-frugal satellite image change detection with generative virtual exemplar learning
Oct 08, 2025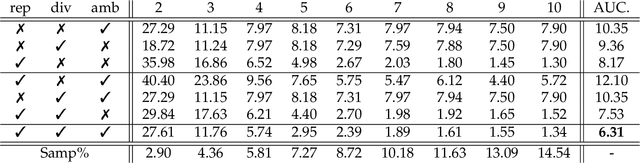

Change detection is a major task in remote sensing which consists in finding all the occurrences of changes in multi-temporal satellite or aerial images. The success of existing methods, and particularly deep learning ones, is tributary to the availability of hand-labeled training data that capture the acquisition conditions and the subjectivity of the user (oracle). In this paper, we devise a novel change detection algorithm, based on active learning. The main contribution of our work resides in a new model that measures how important is each unlabeled sample, and provides an oracle with only the most critical samples (also referred to as virtual exemplars) for further labeling. These exemplars are generated, using an invertible graph convnet, as the optimum of an adversarial loss that (i) measures representativity, diversity and ambiguity of the data, and thereby (ii) challenges (the most) the current change detection criteria, leading to a better re-estimate of these criteria in the subsequent iterations of active learning. Extensive experiments show the positive impact of our label-efficient learning model against comparative methods.
Frugal Incremental Generative Modeling using Variational Autoencoders
May 28, 2025



Continual or incremental learning holds tremendous potential in deep learning with different challenges including catastrophic forgetting. The advent of powerful foundation and generative models has propelled this paradigm even further, making it one of the most viable solution to train these models. However, one of the persisting issues lies in the increasing volume of data particularly with replay-based methods. This growth introduces challenges with scalability since continuously expanding data becomes increasingly demanding as the number of tasks grows. In this paper, we attenuate this issue by devising a novel replay-free incremental learning model based on Variational Autoencoders (VAEs). The main contribution of this work includes (i) a novel incremental generative modelling, built upon a well designed multi-modal latent space, and also (ii) an orthogonality criterion that mitigates catastrophic forgetting of the learned VAEs. The proposed method considers two variants of these VAEs: static and dynamic with no (or at most a controlled) growth in the number of parameters. Extensive experiments show that our method is (at least) an order of magnitude more ``memory-frugal'' compared to the closely related works while achieving SOTA accuracy scores.
Image Classification with Deep Reinforcement Active Learning
Dec 27, 2024



Deep learning is currently reaching outstanding performances on different tasks, including image classification, especially when using large neural networks. The success of these models is tributary to the availability of large collections of labeled training data. In many real-world scenarios, labeled data are scarce, and their hand-labeling is time, effort and cost demanding. Active learning is an alternative paradigm that mitigates the effort in hand-labeling data, where only a small fraction is iteratively selected from a large pool of unlabeled data, and annotated by an expert (a.k.a oracle), and eventually used to update the learning models. However, existing active learning solutions are dependent on handcrafted strategies that may fail in highly variable learning environments (datasets, scenarios, etc). In this work, we devise an adaptive active learning method based on Markov Decision Process (MDP). Our framework leverages deep reinforcement learning and active learning together with a Deep Deterministic Policy Gradient (DDPG) in order to dynamically adapt sample selection strategies to the oracle's feedback and the learning environment. Extensive experiments conducted on three different image classification benchmarks show superior performances against several existing active learning strategies.
Multi-label Classification using Deep Multi-order Context-aware Kernel Networks
Dec 27, 2024Multi-label classification is a challenging task in pattern recognition. Many deep learning methods have been proposed and largely enhanced classification performance. However, most of the existing sophisticated methods ignore context in the models' learning process. Since context may provide additional cues to the learned models, it may significantly boost classification performances. In this work, we make full use of context information (namely geometrical structure of images) in order to learn better context-aware similarities (a.k.a. kernels) between images. We reformulate context-aware kernel design as a feed-forward network that outputs explicit kernel mapping features. Our obtained context-aware kernel network further leverages multiple orders of patch neighbors within different distances, resulting into a more discriminating Deep Multi-order Context-aware Kernel Network (DMCKN) for multi-label classification. We evaluate the proposed method on the challenging Corel5K and NUS-WIDE benchmarks, and empirical results show that our method obtains competitive performances against the related state-of-the-art, and both quantitative and qualitative performances corroborate its effectiveness and superiority for multi-label image classification.
Learning Coarse-to-Fine Pruning of Graph Convolutional Networks for Skeleton-based Recognition
Dec 17, 2024Magnitude Pruning is a staple lightweight network design method which seeks to remove connections with the smallest magnitude. This process is either achieved in a structured or unstructured manner. While structured pruning allows reaching high efficiency, unstructured one is more flexible and leads to better accuracy, but this is achieved at the expense of low computational performance. In this paper, we devise a novel coarse-to-fine (CTF) method that gathers the advantages of structured and unstructured pruning while discarding their inconveniences to some extent. Our method relies on a novel CTF parametrization that models the mask of each connection as the Hadamard product involving four parametrizations which capture channel-wise, column-wise, row-wise and entry-wise pruning respectively. Hence, fine-grained pruning is enabled only when the coarse-grained one is disabled, and this leads to highly efficient networks while being effective. Extensive experiments conducted on the challenging task of skeleton-based recognition, using the standard SBU and FPHA datasets, show the clear advantage of our CTF approach against different baselines as well as the related work.
Designing Semi-Structured Pruning of Graph Convolutional Networks for Skeleton-based Recognition
Dec 16, 2024



Deep neural networks (DNNs) are nowadays witnessing a major success in solving many pattern recognition tasks including skeleton-based classification. The deployment of DNNs on edge-devices, endowed with limited time and memory resources, requires designing lightweight and efficient variants of these networks. Pruning is one of the lightweight network design techniques that operate by removing unnecessary network parts, in a structured or an unstructured manner, including individual weights, neurons or even entire channels. Nonetheless, structured and unstructured pruning methods, when applied separately, may either be inefficient or ineffective. In this paper, we devise a novel semi-structured method that discards the downsides of structured and unstructured pruning while gathering their upsides to some extent. The proposed solution is based on a differentiable cascaded parametrization which combines (i) a band-stop mechanism that prunes weights depending on their magnitudes, (ii) a weight-sharing parametrization that prunes connections either individually or group-wise, and (iii) a gating mechanism which arbitrates between different group-wise and entry-wise pruning. All these cascaded parametrizations are built upon a common latent tensor which is trained end-to-end by minimizing a classification loss and a surrogate tensor rank regularizer. Extensive experiments, conducted on the challenging tasks of action and hand-gesture recognition, show the clear advantage of our proposed semi-structured pruning approach against both structured and unstructured pruning, when taken separately, as well as the related work.
Few-Shot Object Detection with Sparse Context Transformers
Feb 14, 2024



Few-shot detection is a major task in pattern recognition which seeks to localize objects using models trained with few labeled data. One of the mainstream few-shot methods is transfer learning which consists in pretraining a detection model in a source domain prior to its fine-tuning in a target domain. However, it is challenging for fine-tuned models to effectively identify new classes in the target domain, particularly when the underlying labeled training data are scarce. In this paper, we devise a novel sparse context transformer (SCT) that effectively leverages object knowledge in the source domain, and automatically learns a sparse context from only few training images in the target domain. As a result, it combines different relevant clues in order to enhance the discrimination power of the learned detectors and reduce class confusion. We evaluate the proposed method on two challenging few-shot object detection benchmarks, and empirical results show that the proposed method obtains competitive performance compared to the related state-of-the-art.
One-Shot Multi-Rate Pruning of Graph Convolutional Networks
Dec 29, 2023



In this paper, we devise a novel lightweight Graph Convolutional Network (GCN) design dubbed as Multi-Rate Magnitude Pruning (MRMP) that jointly trains network topology and weights. Our method is variational and proceeds by aligning the weight distribution of the learned networks with an a priori distribution. In the one hand, this allows implementing any fixed pruning rate, and also enhancing the generalization performances of the designed lightweight GCNs. In the other hand, MRMP achieves a joint training of multiple GCNs, on top of shared weights, in order to extrapolate accurate networks at any targeted pruning rate without retraining their weights. Extensive experiments conducted on the challenging task of skeleton-based recognition show a substantial gain of our lightweight GCNs particularly at very high pruning regimes.
Reinforcement-based Display-size Selection for Frugal Satellite Image Change Detection
Dec 28, 2023We introduce a novel interactive satellite image change detection algorithm based on active learning. The proposed method is iterative and consists in frugally probing the user (oracle) about the labels of the most critical images, and according to the oracle's annotations, it updates change detection results. First, we consider a probabilistic framework which assigns to each unlabeled sample a relevance measure modeling how critical is that sample when training change detection functions. We obtain these relevance measures by minimizing an objective function mixing diversity, representativity and uncertainty. These criteria when combined allow exploring different data modes and also refining change detections. Then, we further explore the potential of this objective function, by considering a reinforcement learning approach that finds the best combination of diversity, representativity and uncertainty as well as display-sizes through active learning iterations, leading to better generalization as shown through experiments in interactive satellite image change detection.