 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDART-VLN: Test-Time Memory Decay and Anti-Loop Regularization for Discrete Vision-Language Navigation
Jul 01, 2026Memory-based discrete vision-language navigation (VLN) agents must act under partial observability, yet even strong frozen backbones remain vulnerable at test time. Two common failure modes are stale historical evidence at memory readout and inefficient local backtracking during action selection. We present DART-VLN, a training-free test-time control framework for discrete VLN. DART-VLN combines Test-Time Memory Decay, a read-side memory reweighting rule that suppresses stale and redundant evidence without rewriting stored content, with Anti-Loop Regularization, a lightweight next-hop penalty that discourages immediate reversals during action selection. The framework introduces no new learnable parameters and leaves the learned backbone unchanged. Experiments on R2R and REVERIE show a consistent pattern: decay-only provides stable read-side gains, while decay+anti-loop achieves the best overall quality-efficiency trade-off, yielding shorter trajectories, lower runtime, and improved navigation performance in key settings. Behavioral analysis further confirms that anti-loop regularization reduces local backtracking and improves path efficiency under frozen backbones. Overall, the results show that modest test-time control can make memory-based discrete VLN more reliable and efficient without retraining.
Latent Diffusion Policy: Shaping Latent Spaces for Diffusion-Based Robotic Manipulation
Jun 07, 2026Diffusion-based visuomotor policies operating directly in raw action spaces conflate scene comprehension with trajectory generation within a single denoising process. The resulting velocity field must simultaneously encode scene information and generate precise trajectories, increasing learning complexity and limiting performance on tasks demanding precise temporal coordination across multiple arms. To simplify this joint learning problem, we introduce Latent Diffusion Policy (LDP), a two-stage framework performing flow matching in a deliberately shaped latent space. By absorbing scene understanding into an observation-conditioned CVAE encoder, LDP concentrates the conditional distribution of each observation. Consequently, the flow model avoids implicitly resolving scene-dependent structures; instead, it generates within a pre-concentrated distribution featuring a smoother velocity field, simplifying learning from limited demonstrations. Furthermore, to capture temporal dependencies among latent tokens, LDP trains with per-token diffusion forcing and employs staircase inference sampling to resolve the resulting distributional mismatch. We also propose reconstruction FID (rFID) as a lightweight proxy predicting downstream task success solely from latent space statistics. On coordination-intensive tasks from RoboTwin 2.0, LDP outperforms DP3 by a substantial margin and transfers effectively to real-world bimanual deployments.
PerchRL: Vision-Based Agile Perching on Inclined Platforms under Rapid and Irregular Motion
Jun 03, 2026Autonomous vision-based perching of quadrotors on moving inclined platforms is critical for air-ground collaboration but remains challenging due to the limited field of view (FOV). In this paper, we propose PerchRL, a reinforcement learning (RL) framework for vision-based agile perching on inclined platforms under rapid and irregular motion. Specifically, we employ a two-stage learning strategy consisting of state-based pre-training followed by vision-based fine-tuning. To improve generalization across diverse platform motions, we employ randomized platform trajectories to prevent overfitting and temporal augmentation methods to capture latent motion patterns from historical observations. During vision-based fine-tuning, a hybrid learning framework consisting of visibility-aware state augmentation and active perception rewards is presented to improve robustness under intermittent visual loss. Extensive simulation and real-world experiments demonstrate the feasibility, stability, and real-time performance of PerchRL, while successful deployment across distinct quadrotor platforms further validates its adaptability. The source code will be released to benefit the community.
3-D Relative Localization for Multi-Robot Systems with Angle and Self-Displacement Measurements
Apr 02, 2026Realizing relative localization by leveraging inter-robot local measurements is a challenging problem, especially in the presence of measurement noise. Motivated by this challenge, in this paper we propose a novel and systematic 3-D relative localization framework based on inter-robot interior angle and self-displacement measurements. Initially, we propose a linear relative localization theory comprising a distributed linear relative localization algorithm and sufficient conditions for localizability. According to this theory, robots can determine their neighbors' relative positions and orientations in a purely linear manner. Subsequently, in order to deal with measurement noise, we present an advanced Maximum a Posterior (MAP) estimator by addressing three primary challenges existing in the MAP estimator. Firstly, it is common to formulate the MAP problem as an optimization problem, whose inherent non-convexity can result in local optima. To address this issue, we reformulate the linear computation process of the linear relative localization algorithm as a Weighted Total Least Squares (WTLS) optimization problem on manifolds. The optimal solution of the WTLS problem is more accurate, which can then be used as initial values when solving the optimization problem associated with the MAP problem, thereby reducing the risk of falling into local optima. The second challenge is the lack of knowledge of the prior probability density of the robots' relative positions and orientations at the initial time, which is required as an input for the MAP estimator. To deal with it, we combine the WTLS with a Neural Density Estimator (NDE). Thirdly, to prevent the increasing size of the relative positions and orientations to be estimated as the robots continuously move when solving the MAP problem, a marginalization mechanism is designed, which ensures that the computational cost remains constant.
* 29 pages, 28 figures
ProTPS: Prototype-Guided Text Prompt Selection for Continual Learning
Apr 01, 2026For continual learning, text-prompt-based methods leverage text encoders and learnable prompts to encode semantic features for sequentially arrived classes over time. A common challenge encountered by existing works is how to learn unique text prompts, which implicitly carry semantic information of new classes, so that the semantic features of newly arrived classes do not overlap with those of trained classes, thereby mitigating the catastrophic forgetting problem. To address this challenge, we propose a novel approach Prototype-guided Text Prompt Selection (ProTPS)'' to intentionally increase the training flexibility thus encouraging the learning of unique text prompts. Specifically, our ProTPS learns class-specific vision prototypes and text prompts. Vision prototypes guide the selection and learning of text prompts for each class. We first evaluate our ProTPS in both class incremental (CI) setting and cross-datasets continual (CDC) learning setting. Because our ProTPS achieves performance close to the upper bounds, we further collect a real-world dataset with 112 marine species collected over a span of six years, named Marine112, to bring new challenges to the community. Marine112 is authentically suited for the class and domain incremental (CDI) learning setting and is under natural long-tail distribution. The results under three settings show that our ProTPS performs favorably against the recent state-of-the-art methods. The implementation code and Marine112 dataset will be released upon the acceptance of our paper.
Decentralized End-to-End Multi-AAV Pursuit Using Predictive Spatio-Temporal Observation via Deep Reinforcement Learning
Mar 25, 2026Decentralized cooperative pursuit in cluttered environments is challenging for autonomous aerial swarms, especially under partial and noisy perception. Existing methods often rely on abstracted geometric features or privileged ground-truth states, and therefore sidestep perceptual uncertainty in real-world settings. We propose a decentralized end-to-end multi-agent reinforcement learning (MARL) framework that maps raw LiDAR observations directly to continuous control commands. Central to the framework is the Predictive Spatio-Temporal Observation (PSTO), an egocentric grid representation that aligns obstacle geometry with predictive adversarial intent and teammate motion in a unified, fixed-resolution projection. Built on PSTO, a single decentralized policy enables agents to navigate static obstacles, intercept dynamic targets, and maintain cooperative encirclement. Simulations demonstrate that the proposed method achieves superior capture efficiency and competitive success rates compared to state-of-the-art learning-based approaches relying on privileged obstacle information. Furthermore, the unified policy scales seamlessly across different team sizes without retraining. Finally, fully autonomous outdoor experiments validate the framework on a quadrotor swarm relying on only onboard sensing and computing.
C$^2$-Explorer: Contiguity-Driven Task Allocation with Connectivity-Aware Task Representation for Decentralized Multi-UAV Exploration
Mar 08, 2026Efficient multi-UAV exploration under limited communication is severely bottlenecked by inadequate task representation and allocation. Previous task representations either impose heavy communication requirements for coordination or lack the flexibility to handle complex environments, often leading to inefficient traversal. Furthermore, short-horizon allocation strategies neglect spatiotemporal contiguity, causing non-contiguous assignments and frequent cross-region detours. To address this, we propose C$^2$-Explorer, a decentralized framework that constructs a connectivity graph to decompose disconnected unknown components into independent task units. We then introduce a contiguity-driven allocation formulation with a graph-based neighborhood penalty to discourage non-adjacent assignments, promoting more contiguous task sequences over time. Extensive simulation experiments show that C$^2$-Explorer consistently outperforms state-of-the-art (SOTA) baselines, reducing average exploration time by 43.1\% and path length by 33.3\%. Real-world flights further demonstrate the system's feasibility. The code will be released at https://github.com/Robotics-STAR-Lab/C2-Explorer
A Cascaded Information Interaction Network for Precise Image Segmentation
Jan 02, 2026Visual perception plays a pivotal role in enabling autonomous behavior, offering a cost-effective and efficient alternative to complex multi-sensor systems. However, robust segmentation remains a challenge in complex scenarios. To address this, this paper proposes a cascaded convolutional neural network integrated with a novel Global Information Guidance Module. This module is designed to effectively fuse low-level texture details with high-level semantic features across multiple layers, thereby overcoming the inherent limitations of single-scale feature extraction. This architectural innovation significantly enhances segmentation accuracy, particularly in visually cluttered or blurred environments where traditional methods often fail. Experimental evaluations on benchmark image segmentation datasets demonstrate that the proposed framework achieves superior precision, outperforming existing state-of-the-art methods. The results highlight the effectiveness of the approach and its promising potential for deployment in practical robotic applications.
ISS Policy : Scalable Diffusion Policy with Implicit Scene Supervision
Dec 17, 2025Vision-based imitation learning has enabled impressive robotic manipulation skills, but its reliance on object appearance while ignoring the underlying 3D scene structure leads to low training efficiency and poor generalization. To address these challenges, we introduce \emph{Implicit Scene Supervision (ISS) Policy}, a 3D visuomotor DiT-based diffusion policy that predicts sequences of continuous actions from point cloud observations. We extend DiT with a novel implicit scene supervision module that encourages the model to produce outputs consistent with the scene's geometric evolution, thereby improving the performance and robustness of the policy. Notably, ISS Policy achieves state-of-the-art performance on both single-arm manipulation tasks (MetaWorld) and dexterous hand manipulation (Adroit). In real-world experiments, it also demonstrates strong generalization and robustness. Additional ablation studies show that our method scales effectively with both data and parameters. Code and videos will be released.
Agile in the Face of Delay: Asynchronous End-to-End Learning for Real-World Aerial Navigation
Sep 17, 2025
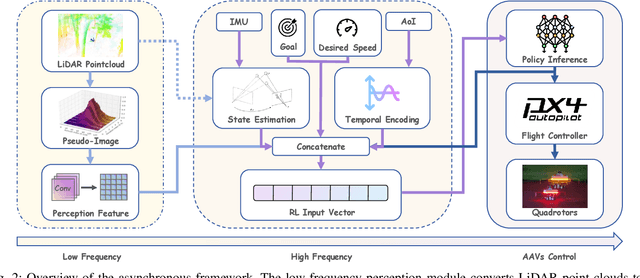
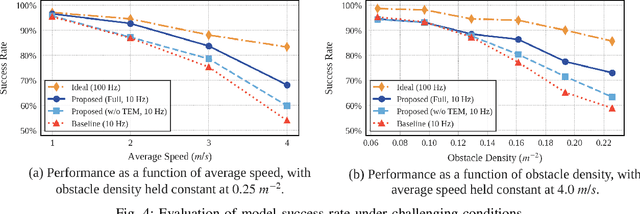
Robust autonomous navigation for Autonomous Aerial Vehicles (AAVs) in complex environments is a critical capability. However, modern end-to-end navigation faces a key challenge: the high-frequency control loop needed for agile flight conflicts with low-frequency perception streams, which are limited by sensor update rates and significant computational cost. This mismatch forces conventional synchronous models into undesirably low control rates. To resolve this, we propose an asynchronous reinforcement learning framework that decouples perception and control, enabling a high-frequency policy to act on the latest IMU state for immediate reactivity, while incorporating perception features asynchronously. To manage the resulting data staleness, we introduce a theoretically-grounded Temporal Encoding Module (TEM) that explicitly conditions the policy on perception delays, a strategy complemented by a two-stage curriculum to ensure stable and efficient training. Validated in extensive simulations, our method was successfully deployed in zero-shot sim-to-real transfer on an onboard NUC, where it sustains a 100~Hz control rate and demonstrates robust, agile navigation in cluttered real-world environments. Our source code will be released for community reference.