 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDIS2: Disentanglement Meets Distillation with Classwise Attention for Robust Remote Sensing Segmentation under Missing Modalities
Jan 20, 2026The efficacy of multimodal learning in remote sensing (RS) is severely undermined by missing modalities. The challenge is exacerbated by the RS highly heterogeneous data and huge scale variation. Consequently, paradigms proven effective in other domains often fail when confronted with these unique data characteristics. Conventional disentanglement learning, which relies on significant feature overlap between modalities (modality-invariant), is insufficient for this heterogeneity. Similarly, knowledge distillation becomes an ill-posed mimicry task where a student fails to focus on the necessary compensatory knowledge, leaving the semantic gap unaddressed. Our work is therefore built upon three pillars uniquely designed for RS: (1) principled missing information compensation, (2) class-specific modality contribution, and (3) multi-resolution feature importance. We propose a novel method DIS2, a new paradigm shifting from modality-shared feature dependence and untargeted imitation to active, guided missing features compensation. Its core novelty lies in a reformulated synergy between disentanglement learning and knowledge distillation, termed DLKD. Compensatory features are explicitly captured which, when fused with the features of the available modality, approximate the ideal fused representation of the full-modality case. To address the class-specific challenge, our Classwise Feature Learning Module (CFLM) adaptively learn discriminative evidence for each target depending on signal availability. Both DLKD and CFLM are supported by a hierarchical hybrid fusion (HF) structure using features across resolutions to strengthen prediction. Extensive experiments validate that our proposed approach significantly outperforms state-of-the-art methods across benchmarks.
3rd Workshop on Maritime Computer Vision (MaCVi) 2025: Challenge Results
Jan 17, 2025The 3rd Workshop on Maritime Computer Vision (MaCVi) 2025 addresses maritime computer vision for Unmanned Surface Vehicles (USV) and underwater. This report offers a comprehensive overview of the findings from the challenges. We provide both statistical and qualitative analyses, evaluating trends from over 700 submissions. All datasets, evaluation code, and the leaderboard are available to the public at https://macvi.org/workshop/macvi25.
Zoom-shot: Fast and Efficient Unsupervised Zero-Shot Transfer of CLIP to Vision Encoders with Multimodal Loss
Jan 22, 2024The fusion of vision and language has brought about a transformative shift in computer vision through the emergence of Vision-Language Models (VLMs). However, the resource-intensive nature of existing VLMs poses a significant challenge. We need an accessible method for developing the next generation of VLMs. To address this issue, we propose Zoom-shot, a novel method for transferring the zero-shot capabilities of CLIP to any pre-trained vision encoder. We do this by exploiting the multimodal information (i.e. text and image) present in the CLIP latent space through the use of specifically designed multimodal loss functions. These loss functions are (1) cycle-consistency loss and (2) our novel prompt-guided knowledge distillation loss (PG-KD). PG-KD combines the concept of knowledge distillation with CLIP's zero-shot classification, to capture the interactions between text and image features. With our multimodal losses, we train a $\textbf{linear mapping}$ between the CLIP latent space and the latent space of a pre-trained vision encoder, for only a $\textbf{single epoch}$. Furthermore, Zoom-shot is entirely unsupervised and is trained using $\textbf{unpaired}$ data. We test the zero-shot capabilities of a range of vision encoders augmented as new VLMs, on coarse and fine-grained classification datasets, outperforming the previous state-of-the-art in this problem domain. In our ablations, we find Zoom-shot allows for a trade-off between data and compute during training; and our state-of-the-art results can be obtained by reducing training from 20% to 1% of the ImageNet training data with 20 epochs. All code and models are available on GitHub.
SafeSea: Synthetic Data Generation for Adverse & Low Probability Maritime Conditions
Nov 24, 2023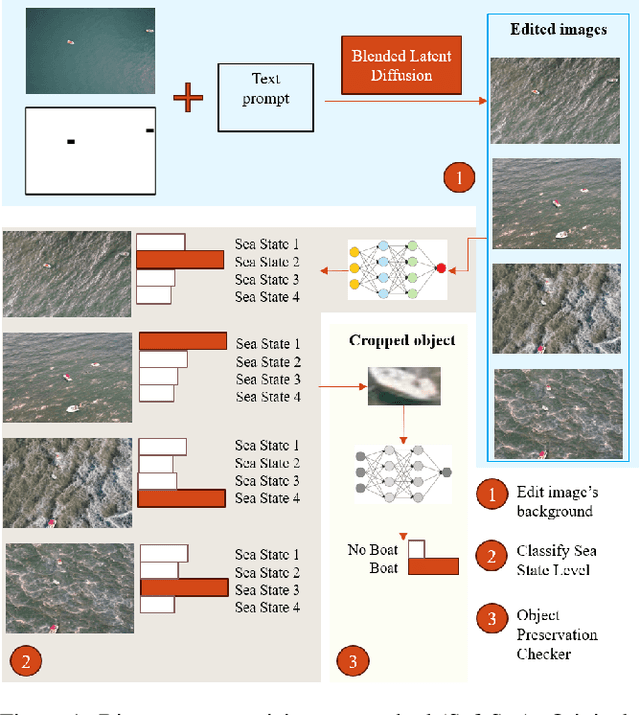



High-quality training data is essential for enhancing the robustness of object detection models. Within the maritime domain, obtaining a diverse real image dataset is particularly challenging due to the difficulty of capturing sea images with the presence of maritime objects , especially in stormy conditions. These challenges arise due to resource limitations, in addition to the unpredictable appearance of maritime objects. Nevertheless, acquiring data from stormy conditions is essential for training effective maritime detection models, particularly for search and rescue, where real-world conditions can be unpredictable. In this work, we introduce SafeSea, which is a stepping stone towards transforming actual sea images with various Sea State backgrounds while retaining maritime objects. Compared to existing generative methods such as Stable Diffusion Inpainting~\cite{stableDiffusion}, this approach reduces the time and effort required to create synthetic datasets for training maritime object detection models. The proposed method uses two automated filters to only pass generated images that meet the criteria. In particular, these filters will first classify the sea condition according to its Sea State level and then it will check whether the objects from the input image are still preserved. This method enabled the creation of the SafeSea dataset, offering diverse weather condition backgrounds to supplement the training of maritime models. Lastly, we observed that a maritime object detection model faced challenges in detecting objects in stormy sea backgrounds, emphasizing the impact of weather conditions on detection accuracy. The code, and dataset are available at https://github.com/martin-3240/SafeSea.
The 2nd Workshop on Maritime Computer Vision 2024
Nov 23, 2023



The 2nd Workshop on Maritime Computer Vision (MaCVi) 2024 addresses maritime computer vision for Unmanned Aerial Vehicles (UAV) and Unmanned Surface Vehicles (USV). Three challenges categories are considered: (i) UAV-based Maritime Object Tracking with Re-identification, (ii) USV-based Maritime Obstacle Segmentation and Detection, (iii) USV-based Maritime Boat Tracking. The USV-based Maritime Obstacle Segmentation and Detection features three sub-challenges, including a new embedded challenge addressing efficicent inference on real-world embedded devices. This report offers a comprehensive overview of the findings from the challenges. We provide both statistical and qualitative analyses, evaluating trends from over 195 submissions. All datasets, evaluation code, and the leaderboard are available to the public at https://macvi.org/workshop/macvi24.
Boosting Zero-shot Classification with Synthetic Data Diversity via Stable Diffusion
Feb 08, 2023



Recent research has shown it is possible to perform zero-shot classification tasks by training a classifier with synthetic data generated by a diffusion model. However, the performance of this approach is still inferior to that of recent vision-language models. It has been suggested that the reason for this is a domain gap between the synthetic and real data. In our work, we show that this domain gap is not the main issue, and that diversity in the synthetic dataset is more important. We propose a $\textit{bag of tricks}$ to improve diversity and are able to achieve performance on par with one of the vision-language models, CLIP. More importantly, this insight allows us to endow zero-shot classification capabilities on any classification model.
Does Interference Exist When Training a Once-For-All Network?
Apr 20, 2022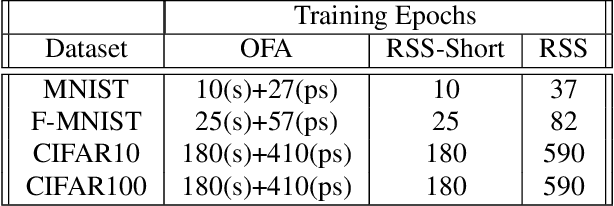
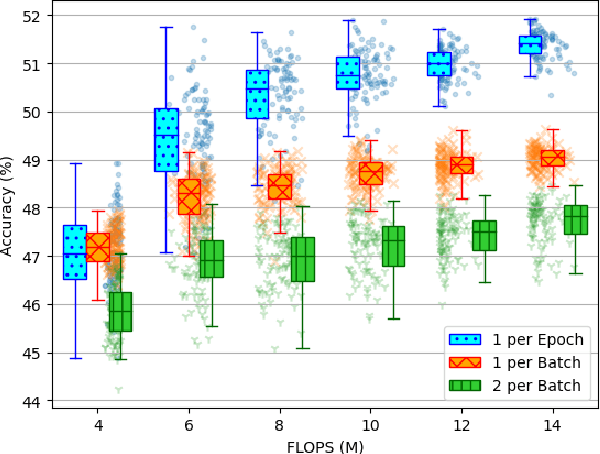

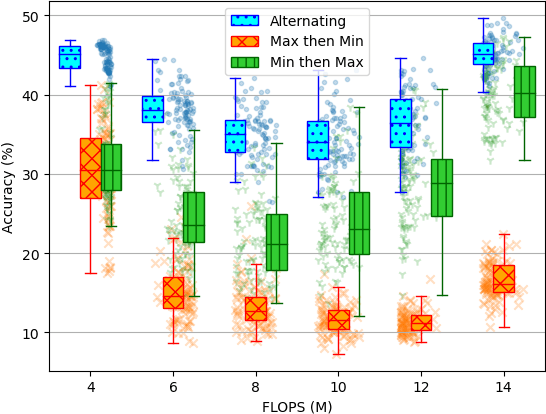
The Once-For-All (OFA) method offers an excellent pathway to deploy a trained neural network model into multiple target platforms by utilising the supernet-subnet architecture. Once trained, a subnet can be derived from the supernet (both architecture and trained weights) and deployed directly to the target platform with little to no retraining or fine-tuning. To train the subnet population, OFA uses a novel training method called Progressive Shrinking (PS) which is designed to limit the negative impact of interference during training. It is believed that higher interference during training results in lower subnet population accuracies. In this work we take a second look at this interference effect. Surprisingly, we find that interference mitigation strategies do not have a large impact on the overall subnet population performance. Instead, we find the subnet architecture selection bias during training to be a more important aspect. To show this, we propose a simple-yet-effective method called Random Subnet Sampling (RSS), which does not have mitigation on the interference effect. Despite no mitigation, RSS is able to produce a better performing subnet population than PS in four small-to-medium-sized datasets; suggesting that the interference effect does not play a pivotal role in these datasets. Due to its simplicity, RSS provides a $1.9\times$ reduction in training times compared to PS. A $6.1\times$ reduction can also be achieved with a reasonable drop in performance when the number of RSS training epochs are reduced. Code available at https://github.com/Jordan-HS/RSS-Interference-CVPRW2022.
Unsupervised Domain Adaptive Object Detection using Forward-Backward Cyclic Adaptation
Feb 03, 2020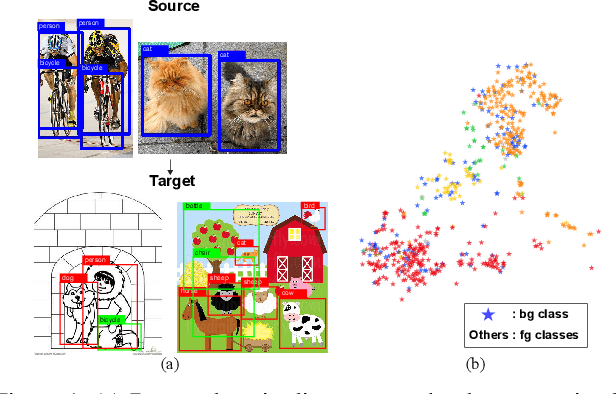

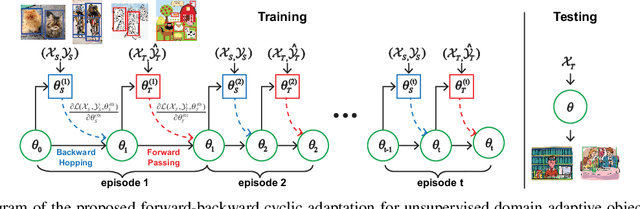
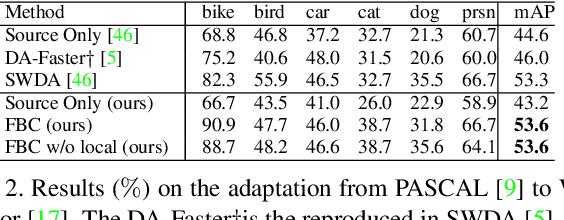
We present a novel approach to perform the unsupervised domain adaptation for object detection through forward-backward cyclic (FBC) training. Recent adversarial training based domain adaptation methods have shown their effectiveness on minimizing domain discrepancy via marginal feature distributions alignment. However, aligning the marginal feature distributions does not guarantee the alignment of class conditional distributions. This limitation is more evident when adapting object detectors as the domain discrepancy is larger compared to the image classification task, e.g. various number of objects exist in one image and the majority of content in an image is the background. This motivates us to learn domain invariance for category level semantics via gradient alignment. Intuitively, if the gradients of two domains point in similar directions, then the learning of one domain can improve that of another domain. To achieve gradient alignment, we propose Forward-Backward Cyclic Adaptation, which iteratively computes adaptation from source to target via backward hopping and from target to source via forward passing. In addition, we align low-level features for adapting holistic color/texture via adversarial training. However, the detector performs well on both domains is not ideal for target domain. As such, in each cycle, domain diversity is enforced by maximum entropy regularization on the source domain to penalize confident source-specific learning and minimum entropy regularization on target domain to intrigue target-specific learning. Theoretical analysis of the training process is provided, and extensive experiments on challenging cross-domain object detection datasets have shown the superiority of our approach over the state-of-the-art.
To What Extent Does Downsampling, Compression, and Data Scarcity Impact Renal Image Analysis?
Sep 22, 2019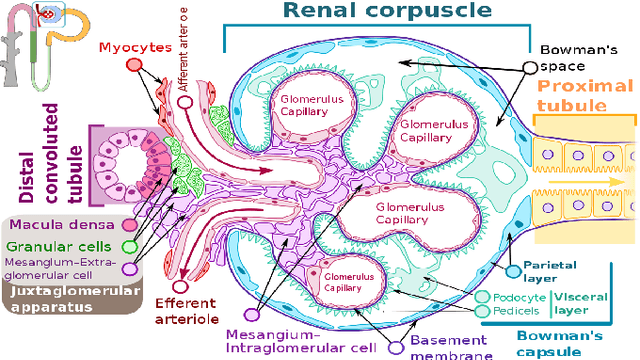
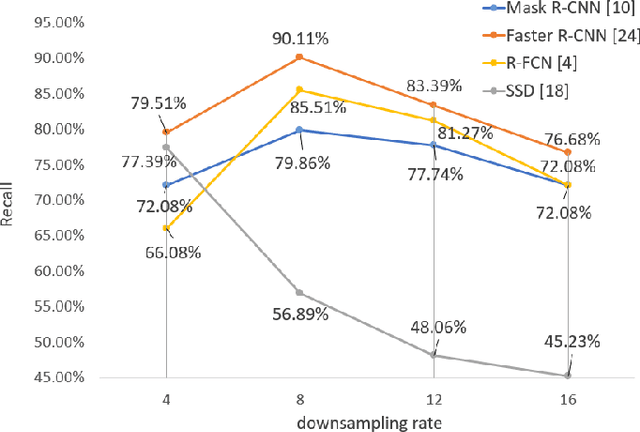
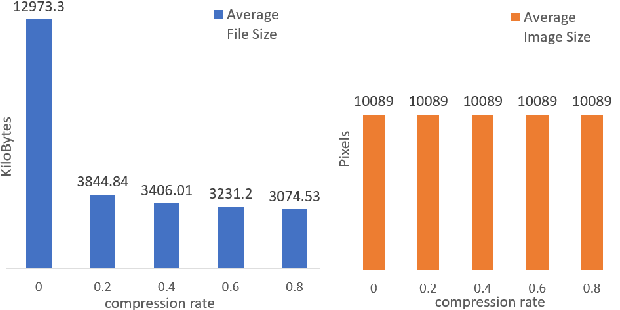
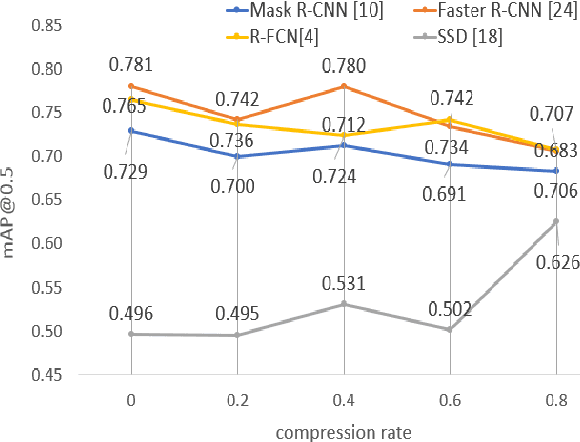
The condition of the Glomeruli, or filter sacks, in renal Direct Immunofluorescence (DIF) specimens is a critical indicator for diagnosing kidney diseases. A digital pathology system which digitizes a glass histology slide into a Whole Slide Image (WSI) and then automatically detects and zooms in on the glomeruli with a higher magnification objective will be extremely helpful for pathologists. In this paper, using glomerulus detection as the study case, we provide analysis and observations on several important issues to help with the development of Computer Aided Diagnostic (CAD) systems to process WSIs. Large image resolution, large file size, and data scarcity are always challenging to deal with. To this end, we first examine image downsampling rates in terms of their effect on detection accuracy. Second, we examine the impact of image compression. Third, we examine the relationship between the size of the training set and detection accuracy. To understand the above issues, experiments are performed on the state-of-the-art detectors: Faster R-CNN, R-FCN, Mask R-CNN and SSD. Critical findings are observed: (1) The best balance between detection accuracy, detection speed and file size is achieved at 8 times downsampling captured with a $40\times$ objective; (2) compression which reduces the file size dramatically, does not necessarily have an adverse effect on overall accuracy; (3) reducing the amount of training data to some extents causes a drop in precision but has a negligible impact on the recall; (4) in most cases, Faster R-CNN achieves the best accuracy in the glomerulus detection task. We show that the image file size of $40\times$ WSI images can be reduced by a factor of over 6000 with negligible loss of glomerulus detection accuracy.
Deep inspection: an electrical distribution pole parts study via deep neural networks
Jul 16, 2019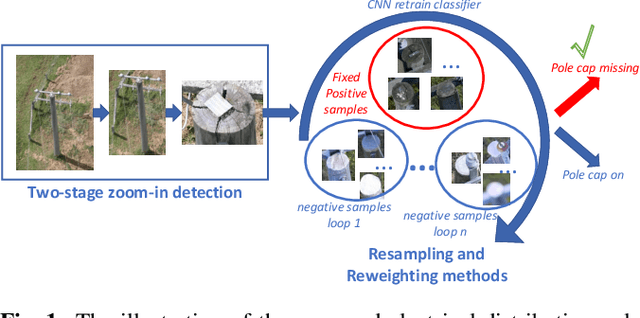

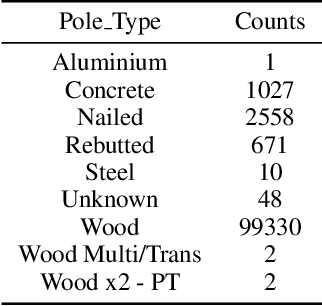

Electrical distribution poles are important assets in electricity supply. These poles need to be maintained in good condition to ensure they protect community safety, maintain reliability of supply, and meet legislative obligations. However, maintaining such a large volumes of assets is an expensive and challenging task. To address this, recent approaches utilise imagery data captured from helicopter and/or drone inspections. Whilst reducing the cost for manual inspection, manual analysis on each image is still required. As such, several image-based automated inspection systems have been proposed. In this paper, we target two major challenges: tiny object detection and extremely imbalanced datasets, which currently hinder the wide deployment of the automatic inspection. We propose a novel two-stage zoom-in detection method to gradually focus on the object of interest. To address the imbalanced dataset problem, we propose the resampling as well as reweighting schemes to iteratively adapt the model to the large intra-class variation of major class and balance the contributions to the loss from each class. Finally, we integrate these components together and devise a novel automatic inspection framework. Extensive experiments demonstrate that our proposed approaches are effective and can boost the performance compared to the baseline methods.