 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Collapse-Inspired Multi-Label Federated Learning under Label-Distribution Skew
Sep 16, 2025Federated Learning (FL) enables collaborative model training across distributed clients while preserving data privacy. However, the performance of deep learning often deteriorates in FL due to decentralized and heterogeneous data. This challenge is further amplified in multi-label scenarios, where data exhibit complex characteristics such as label co-occurrence, inter-label dependency, and discrepancies between local and global label relationships. While most existing FL research primarily focuses on single-label classification, many real-world applications, particularly in domains such as medical imaging, often involve multi-label settings. In this paper, we address this important yet underexplored scenario in FL, where clients hold multi-label data with skewed label distributions. Neural Collapse (NC) describes a geometric structure in the latent feature space where features of each class collapse to their class mean with vanishing intra-class variance, and the class means form a maximally separated configuration. Motivated by this theory, we propose a method to align feature distributions across clients and to learn high-quality, well-clustered representations. To make the NC-structure applicable to multi-label settings, where image-level features may contain multiple semantic concepts, we introduce a feature disentanglement module that extracts semantically specific features. The clustering of these disentangled class-wise features is guided by a predefined shared NC structure, which mitigates potential conflicts between client models due to diverse local data distributions. In addition, we design regularisation losses to encourage compact clustering in the latent feature space. Experiments conducted on four benchmark datasets across eight diverse settings demonstrate that our approach outperforms existing methods, validating its effectiveness in this challenging FL scenario.
Federated Continual 3D Segmentation With Single-round Communication
Mar 19, 2025



Federated learning seeks to foster collaboration among distributed clients while preserving the privacy of their local data. Traditionally, federated learning methods assume a fixed setting in which client data and learning objectives remain constant. However, in real-world scenarios, new clients may join, and existing clients may expand the segmentation label set as task requirements evolve. In such a dynamic federated analysis setup, the conventional federated communication strategy of model aggregation per communication round is suboptimal. As new clients join, this strategy requires retraining, linearly increasing communication and computation overhead. It also imposes requirements for synchronized communication, which is difficult to achieve among distributed clients. In this paper, we propose a federated continual learning strategy that employs a one-time model aggregation at the server through multi-model distillation. This approach builds and updates the global model while eliminating the need for frequent server communication. When integrating new data streams or onboarding new clients, this approach efficiently reuses previous client models, avoiding the need to retrain the global model across the entire federation. By minimizing communication load and bypassing the need to put unchanged clients online, our approach relaxes synchronization requirements among clients, providing an efficient and scalable federated analysis framework suited for real-world applications. Using multi-class 3D abdominal CT segmentation as an application task, we demonstrate the effectiveness of the proposed approach.
WalnutData: A UAV Remote Sensing Dataset of Green Walnuts and Model Evaluation
Feb 27, 2025



The UAV technology is gradually maturing and can provide extremely powerful support for smart agriculture and precise monitoring. Currently, there is no dataset related to green walnuts in the field of agricultural computer vision. Thus, in order to promote the algorithm design in the field of agricultural computer vision, we used UAV to collect remote-sensing data from 8 walnut sample plots. Considering that green walnuts are subject to various lighting conditions and occlusion, we constructed a large-scale dataset with a higher-granularity of target features - WalnutData. This dataset contains a total of 30,240 images and 706,208 instances, and there are 4 target categories: being illuminated by frontal light and unoccluded (A1), being backlit and unoccluded (A2), being illuminated by frontal light and occluded (B1), and being backlit and occluded (B2). Subsequently, we evaluated many mainstream algorithms on WalnutData and used these evaluation results as the baseline standard. The dataset and all evaluation results can be obtained at https://github.com/1wuming/WalnutData.
F$^3$OCUS -- Federated Finetuning of Vision-Language Foundation Models with Optimal Client Layer Updating Strategy via Multi-objective Meta-Heuristics
Nov 17, 2024



Effective training of large Vision-Language Models (VLMs) on resource-constrained client devices in Federated Learning (FL) requires the usage of parameter-efficient fine-tuning (PEFT) strategies. To this end, we demonstrate the impact of two factors \textit{viz.}, client-specific layer importance score that selects the most important VLM layers for fine-tuning and inter-client layer diversity score that encourages diverse layer selection across clients for optimal VLM layer selection. We first theoretically motivate and leverage the principal eigenvalue magnitude of layerwise Neural Tangent Kernels and show its effectiveness as client-specific layer importance score. Next, we propose a novel layer updating strategy dubbed F$^3$OCUS that jointly optimizes the layer importance and diversity factors by employing a data-free, multi-objective, meta-heuristic optimization on the server. We explore 5 different meta-heuristic algorithms and compare their effectiveness for selecting model layers and adapter layers towards PEFT-FL. Furthermore, we release a new MedVQA-FL dataset involving overall 707,962 VQA triplets and 9 modality-specific clients and utilize it to train and evaluate our method. Overall, we conduct more than 10,000 client-level experiments on 6 Vision-Language FL task settings involving 58 medical image datasets and 4 different VLM architectures of varying sizes to demonstrate the effectiveness of the proposed method.
Inductive Graph Few-shot Class Incremental Learning
Nov 11, 2024



Node classification with Graph Neural Networks (GNN) under a fixed set of labels is well known in contrast to Graph Few-Shot Class Incremental Learning (GFSCIL), which involves learning a GNN classifier as graph nodes and classes growing over time sporadically. We introduce inductive GFSCIL that continually learns novel classes with newly emerging nodes while maintaining performance on old classes without accessing previous data. This addresses the practical concern of transductive GFSCIL, which requires storing the entire graph with historical data. Compared to the transductive GFSCIL, the inductive setting exacerbates catastrophic forgetting due to inaccessible previous data during incremental training, in addition to overfitting issue caused by label sparsity. Thus, we propose a novel method, called Topology-based class Augmentation and Prototype calibration (TAP). To be specific, it first creates a triple-branch multi-topology class augmentation method to enhance model generalization ability. As each incremental session receives a disjoint subgraph with nodes of novel classes, the multi-topology class augmentation method helps replicate such a setting in the base session to boost backbone versatility. In incremental learning, given the limited number of novel class samples, we propose an iterative prototype calibration to improve the separation of class prototypes. Furthermore, as backbone fine-tuning poses the feature distribution drift, prototypes of old classes start failing over time, we propose the prototype shift method for old classes to compensate for the drift. We showcase the proposed method on four datasets.
Multivariate Prototype Representation for Domain-Generalized Incremental Learning
Sep 24, 2023



Deep learning models suffer from catastrophic forgetting when being fine-tuned with samples of new classes. This issue becomes even more pronounced when faced with the domain shift between training and testing data. In this paper, we study the critical and less explored Domain-Generalized Class-Incremental Learning (DGCIL). We design a DGCIL approach that remembers old classes, adapts to new classes, and can classify reliably objects from unseen domains. Specifically, our loss formulation maintains classification boundaries and suppresses the domain-specific information of each class. With no old exemplars stored, we use knowledge distillation and estimate old class prototype drift as incremental training advances. Our prototype representations are based on multivariate Normal distributions whose means and covariances are constantly adapted to changing model features to represent old classes well by adapting to the feature space drift. For old classes, we sample pseudo-features from the adapted Normal distributions with the help of Cholesky decomposition. In contrast to previous pseudo-feature sampling strategies that rely solely on average mean prototypes, our method excels at capturing varying semantic information. Experiments on several benchmarks validate our claims.
Conditioned Generative Transformers for Histopathology Image Synthetic Augmentation
Dec 20, 2022



Deep learning networks have demonstrated state-of-the-art performance on medical image analysis tasks. However, the majority of the works rely heavily on abundantly labeled data, which necessitates extensive involvement of domain experts. Vision transformer (ViT) based generative adversarial networks (GANs) recently demonstrated superior potential in general image synthesis, yet are less explored for histopathology images. In this paper, we address these challenges by proposing a pure ViT-based conditional GAN model for histopathology image synthetic augmentation. To alleviate training instability and improve generation robustness, we first introduce a conditioned class projection method to facilitate class separation. We then implement a multi-loss weighing function to dynamically balance the losses between classification tasks. We further propose a selective augmentation mechanism to actively choose the appropriate generated images and bring additional performance improvements. Extensive experiments on the histopathology datasets show that leveraging our synthetic augmentation framework results in significant and consistent improvements in classification performance.
Few-Shot Class-Incremental Learning from an Open-Set Perspective
Jul 30, 2022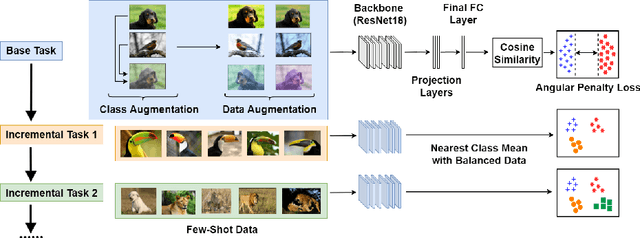
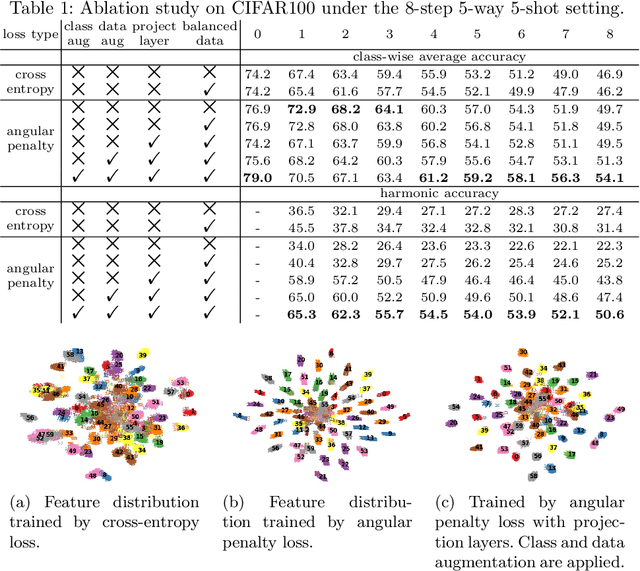
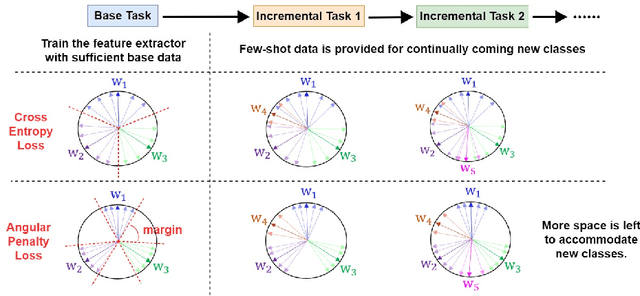
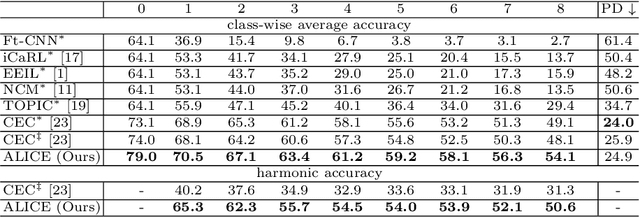
The continual appearance of new objects in the visual world poses considerable challenges for current deep learning methods in real-world deployments. The challenge of new task learning is often exacerbated by the scarcity of data for the new categories due to rarity or cost. Here we explore the important task of Few-Shot Class-Incremental Learning (FSCIL) and its extreme data scarcity condition of one-shot. An ideal FSCIL model needs to perform well on all classes, regardless of their presentation order or paucity of data. It also needs to be robust to open-set real-world conditions and be easily adapted to the new tasks that always arise in the field. In this paper, we first reevaluate the current task setting and propose a more comprehensive and practical setting for the FSCIL task. Then, inspired by the similarity of the goals for FSCIL and modern face recognition systems, we propose our method -- Augmented Angular Loss Incremental Classification or ALICE. In ALICE, instead of the commonly used cross-entropy loss, we propose to use the angular penalty loss to obtain well-clustered features. As the obtained features not only need to be compactly clustered but also diverse enough to maintain generalization for future incremental classes, we further discuss how class augmentation, data augmentation, and data balancing affect classification performance. Experiments on benchmark datasets, including CIFAR100, miniImageNet, and CUB200, demonstrate the improved performance of ALICE over the state-of-the-art FSCIL methods.
FaceCook: Face Generation Based on Linear Scaling Factors
Sep 08, 2021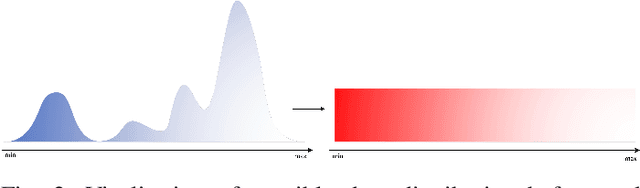
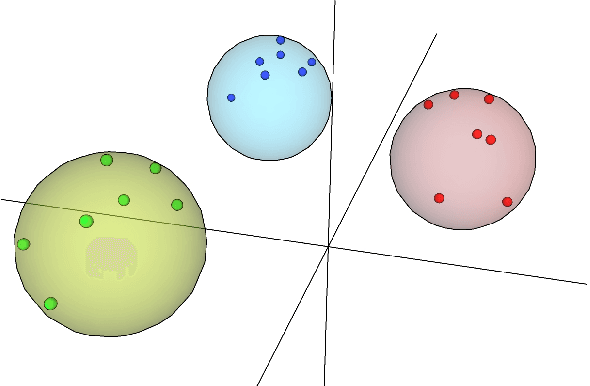
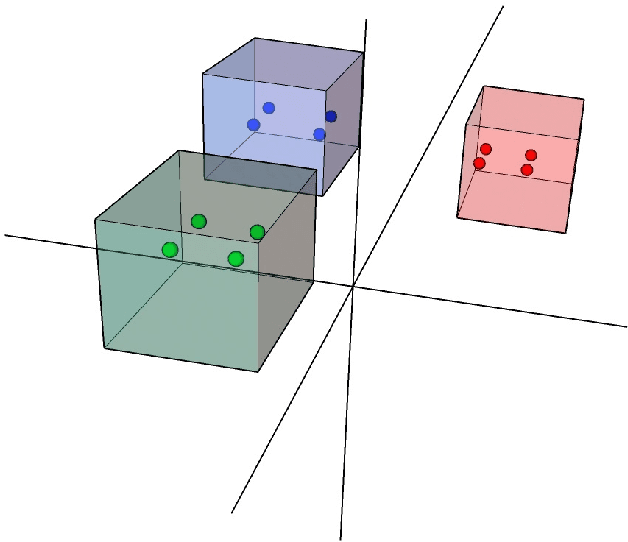

With the excellent disentanglement properties of state-of-the-art generative models, image editing has been the dominant approach to control the attributes of synthesised face images. However, these edited results often suffer from artifacts or incorrect feature rendering, especially when there is a large discrepancy between the image to be edited and the desired feature set. Therefore, we propose a new approach to mapping the latent vectors of the generative model to the scaling factors through solving a set of multivariate linear equations. The coefficients of the equations are the eigenvectors of the weight parameters of the pre-trained model, which form the basis of a hyper coordinate system. The qualitative and quantitative results both show that the proposed method outperforms the baseline in terms of image diversity. In addition, the method is much more time-efficient because you can obtain synthesised images with desirable features directly from the latent vectors, rather than the former process of editing randomly generated images requiring many processing steps.
DIODE: Dilatable Incremental Object Detection
Aug 12, 2021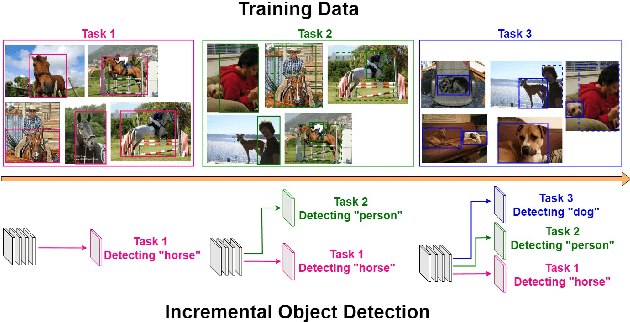
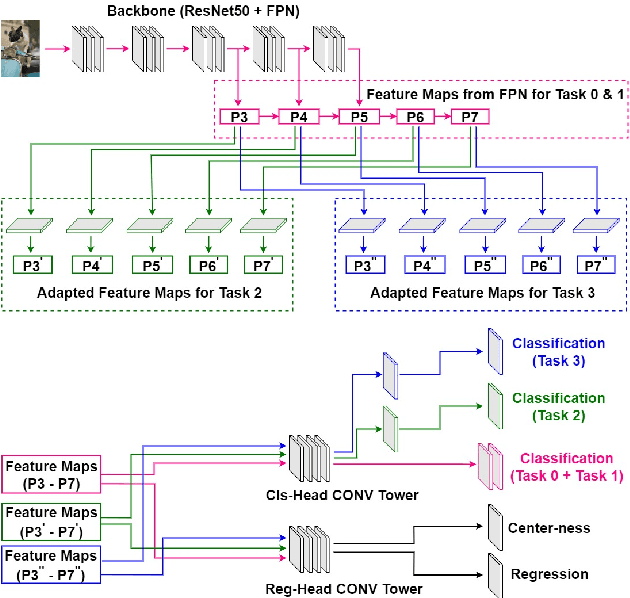
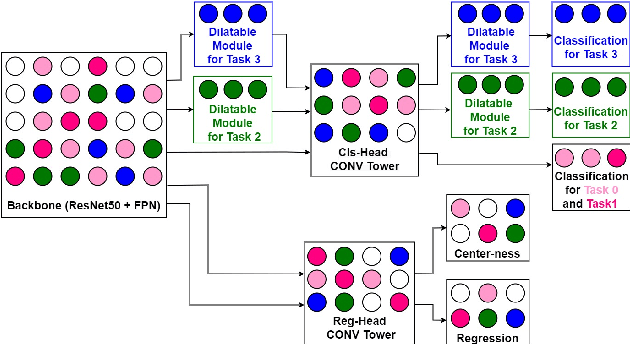
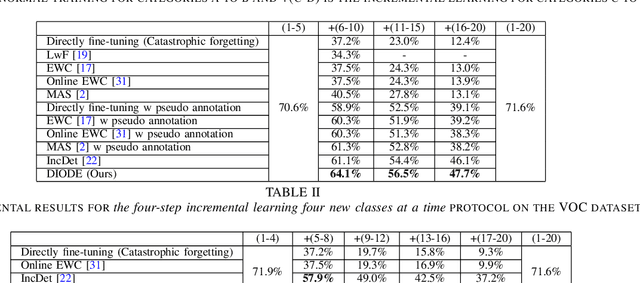
To accommodate rapid changes in the real world, the cognition system of humans is capable of continually learning concepts. On the contrary, conventional deep learning models lack this capability of preserving previously learned knowledge. When a neural network is fine-tuned to learn new tasks, its performance on previously trained tasks will significantly deteriorate. Many recent works on incremental object detection tackle this problem by introducing advanced regularization. Although these methods have shown promising results, the benefits are often short-lived after the first incremental step. Under multi-step incremental learning, the trade-off between old knowledge preserving and new task learning becomes progressively more severe. Thus, the performance of regularization-based incremental object detectors gradually decays for subsequent learning steps. In this paper, we aim to alleviate this performance decay on multi-step incremental detection tasks by proposing a dilatable incremental object detector (DIODE). For the task-shared parameters, our method adaptively penalizes the changes of important weights for previous tasks. At the same time, the structure of the model is dilated or expanded by a limited number of task-specific parameters to promote new task learning. Extensive experiments on PASCAL VOC and COCO datasets demonstrate substantial improvements over the state-of-the-art methods. Notably, compared with the state-of-the-art methods, our method achieves up to 6.0% performance improvement by increasing the number of parameters by just 1.2% for each newly learned task.