 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDIODE: Dilatable Incremental Object Detection
Aug 12, 2021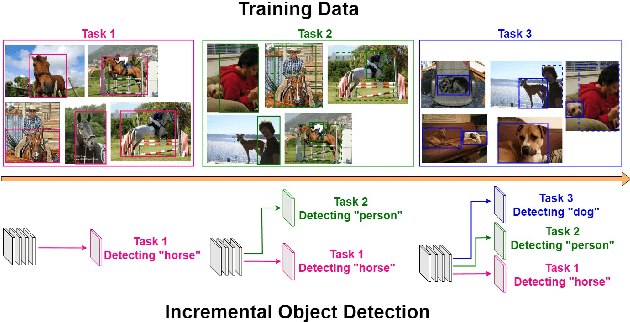
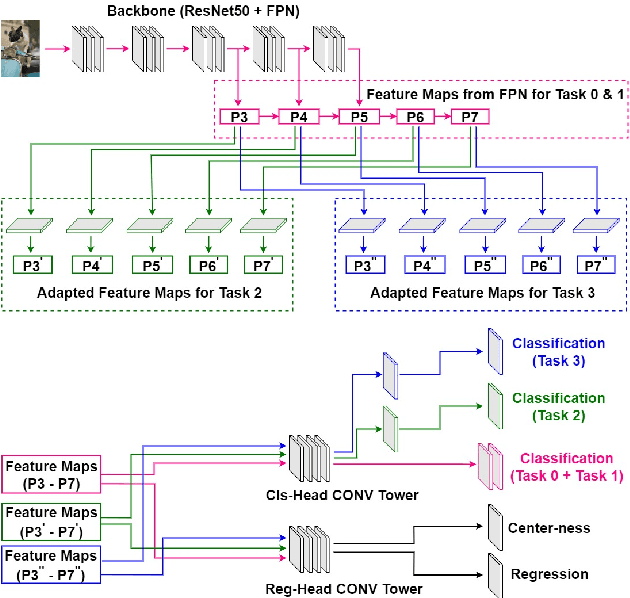
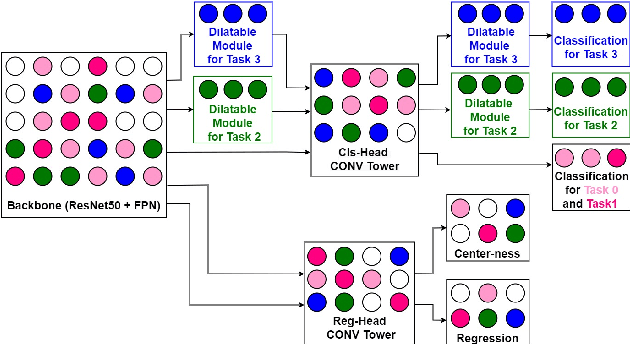
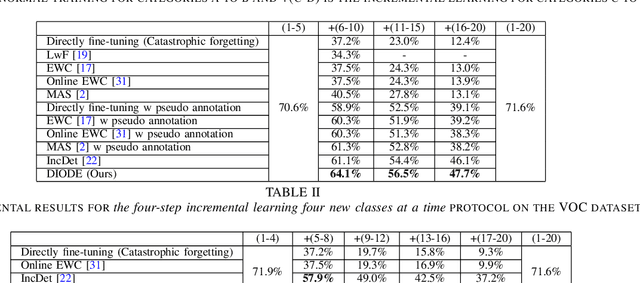
To accommodate rapid changes in the real world, the cognition system of humans is capable of continually learning concepts. On the contrary, conventional deep learning models lack this capability of preserving previously learned knowledge. When a neural network is fine-tuned to learn new tasks, its performance on previously trained tasks will significantly deteriorate. Many recent works on incremental object detection tackle this problem by introducing advanced regularization. Although these methods have shown promising results, the benefits are often short-lived after the first incremental step. Under multi-step incremental learning, the trade-off between old knowledge preserving and new task learning becomes progressively more severe. Thus, the performance of regularization-based incremental object detectors gradually decays for subsequent learning steps. In this paper, we aim to alleviate this performance decay on multi-step incremental detection tasks by proposing a dilatable incremental object detector (DIODE). For the task-shared parameters, our method adaptively penalizes the changes of important weights for previous tasks. At the same time, the structure of the model is dilated or expanded by a limited number of task-specific parameters to promote new task learning. Extensive experiments on PASCAL VOC and COCO datasets demonstrate substantial improvements over the state-of-the-art methods. Notably, compared with the state-of-the-art methods, our method achieves up to 6.0% performance improvement by increasing the number of parameters by just 1.2% for each newly learned task.
Scalable Bayesian Deep Learning with Kernel Seed Networks
Apr 19, 2021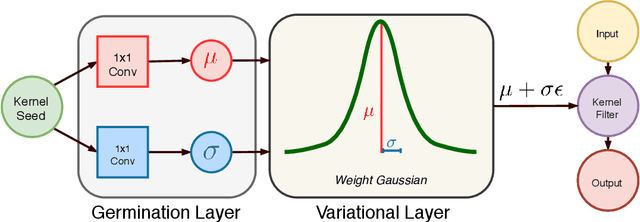
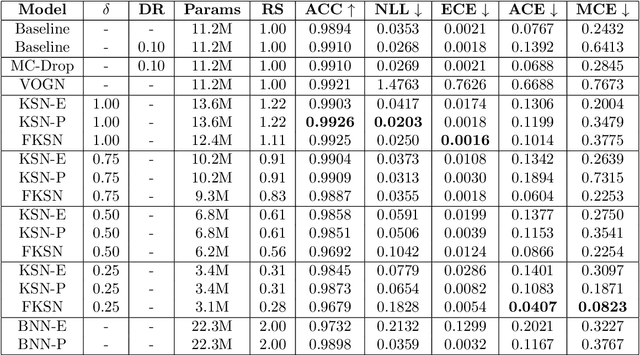
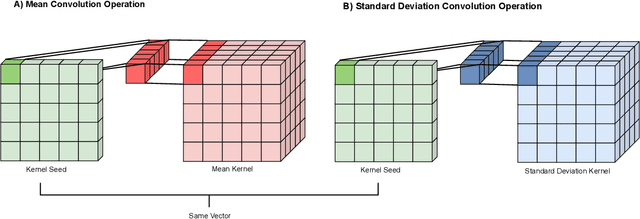
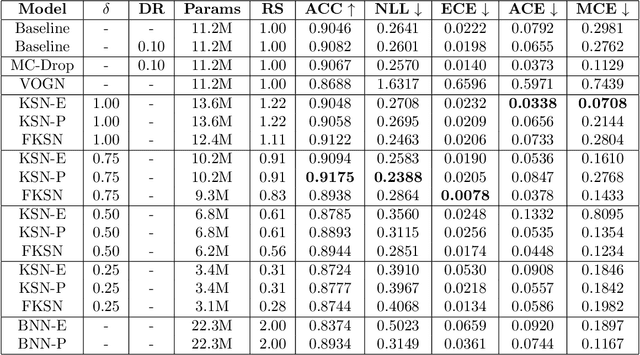
This paper addresses the scalability problem of Bayesian deep neural networks. The performance of deep neural networks is undermined by the fact that these algorithms have poorly calibrated measures of uncertainty. This restricts their application in high risk domains such as computer aided diagnosis and autonomous vehicle navigation. Bayesian Deep Learning (BDL) offers a promising method for representing uncertainty in neural network. However, BDL requires a separate set of parameters to store the mean and standard deviation of model weights to learn a distribution. This results in a prohibitive 2-fold increase in the number of model parameters. To address this problem we present a method for performing BDL, namely Kernel Seed Networks (KSN), which does not require a 2-fold increase in the number of parameters. KSNs use 1x1 Convolution operations to learn a compressed latent space representation of the parameter distribution. In this paper we show how this allows KSNs to outperform conventional BDL methods while reducing the number of required parameters by up to a factor of 6.6.
SID: Incremental Learning for Anchor-Free Object Detection via Selective and Inter-Related Distillation
Dec 31, 2020


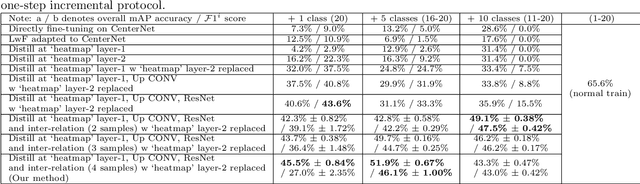
Incremental learning requires a model to continually learn new tasks from streaming data. However, traditional fine-tuning of a well-trained deep neural network on a new task will dramatically degrade performance on the old task -- a problem known as catastrophic forgetting. In this paper, we address this issue in the context of anchor-free object detection, which is a new trend in computer vision as it is simple, fast, and flexible. Simply adapting current incremental learning strategies fails on these anchor-free detectors due to lack of consideration of their specific model structures. To deal with the challenges of incremental learning on anchor-free object detectors, we propose a novel incremental learning paradigm called Selective and Inter-related Distillation (SID). In addition, a novel evaluation metric is proposed to better assess the performance of detectors under incremental learning conditions. By selective distilling at the proper locations and further transferring additional instance relation knowledge, our method demonstrates significant advantages on the benchmark datasets PASCAL VOC and COCO.
SOS: Selective Objective Switch for Rapid Immunofluorescence Whole Slide Image Classification
Mar 11, 2020
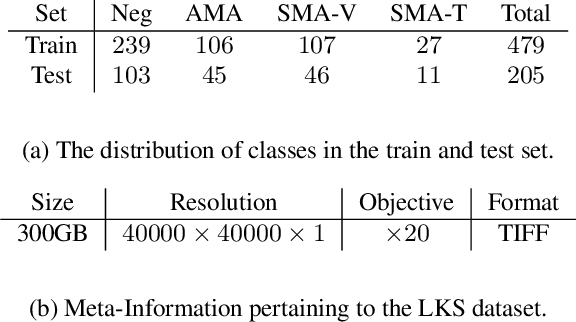
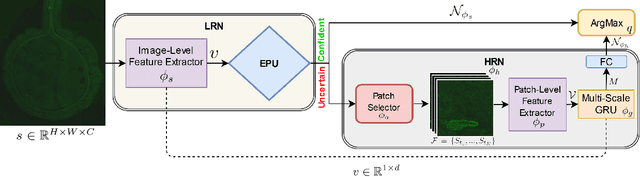
The difficulty of processing gigapixel whole slide images (WSIs) in clinical microscopy has been a long-standing barrier to implementing computer aided diagnostic systems. Since modern computing resources are unable to perform computations at this extremely large scale, current state of the art methods utilize patch-based processing to preserve the resolution of WSIs. However, these methods are often resource intensive and make significant compromises on processing time. In this paper, we demonstrate that conventional patch-based processing is redundant for certain WSI classification tasks where high resolution is only required in a minority of cases. This reflects what is observed in clinical practice; where a pathologist may screen slides using a low power objective and only switch to a high power in cases where they are uncertain about their findings. To eliminate these redundancies, we propose a method for the selective use of high resolution processing based on the confidence of predictions on downscaled WSIs --- we call this the Selective Objective Switch (SOS). Our method is validated on a novel dataset of 684 Liver-Kidney-Stomach immunofluorescence WSIs routinely used in the investigation of autoimmune liver disease. By limiting high resolution processing to cases which cannot be classified confidently at low resolution, we maintain the accuracy of patch-level analysis whilst reducing the inference time by a factor of 7.74.
CORAL8: Concurrent Object Regression for Area Localization in Medical Image Panels
Jun 24, 2019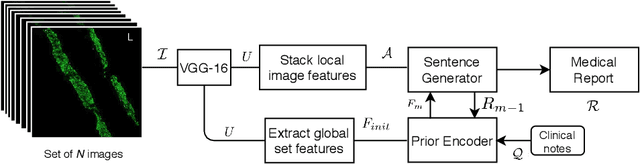
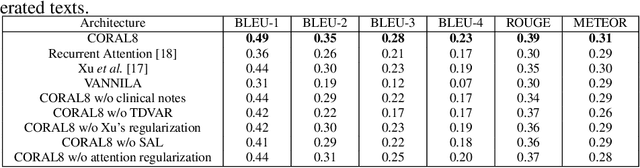

This work tackles the problem of generating a medical report for multi-image panels. We apply our solution to the Renal Direct Immunofluorescence (RDIF) assay which requires a pathologist to generate a report based on observations across the eight different WSI in concert with existing clinical features. To this end, we propose a novel attention-based multi-modal generative recurrent neural network (RNN) architecture capable of dynamically sampling image data concurrently across the RDIF panel. The proposed methodology incorporates text from the clinical notes of the requesting physician to regulate the output of the network to align with the overall clinical context. In addition, we found the importance of regularizing the attention weights for word generation processes. This is because the system can ignore the attention mechanism by assigning equal weights for all members. Thus, we propose two regularizations which force the system to utilize the attention mechanism. Experiments on our novel collection of RDIF WSIs provided by a large clinical laboratory demonstrate that our framework offers significant improvements over existing methods.